Projects – Spring 2004
Click on a project to read its description.
Project Description
The student team involved with this project will investigate the feasibility of Queuing Network Modeling for predicting filer performance in multi-class transaction workload environments.
Background
Much of queuing theory is oriented towards modeling a complex system using a single service center with complex characteristics. Sophisticated mathematical techniques are employed to analyze these models. Relatively detailed performance measures are obtained: distributions as opposed to averages, for example.
Rather than single service centers with complex characteristics, queuing network modeling employs networks of service centers with simple characteristics. Benefits arise from the fact that the application domain is restricted to computer systems. [See Lazowska et al, Quantitative System Performance Computer System Analysis Using Queuing Network Models, Prentice Hall, 1984. http://www.cs.washington.edu/homes/lazowska/qsp/.]
Queuing network models are analytic, as opposed to simulation models. They characterize a system as a set of service centers which represent devices or other system resources and customers representing the workloads. Customers are partitioned into transaction classes, each of which is defined by a workload intensity (population or arrival rate), and a set of service demands on the set of service centers. The model is solved analytically to provide metrics such as throughput, response time, queue lengths, and service center utilizations. Little's Law gone amuk. (In plain English, Little's Law says: The average number of customers in a stable system (over some time interval) is equal to their average arrival rate, multiplied by their average time in the system.)
It seems that complex storage systems (such as filers) may be prime candidates for the application of queuing network modeling because of the following:
- Storage systems have a limited set of transaction classes. Unlike a database server, for example, which has an infinite set of possible transaction classes, a storage server has a small finite set. This is especially true for block-oriented servers. The major transaction classes are defined by 2 values for transfer direction {read, write} and a dozen or so transfer sizes {512, 1K, 2K, ..., 128K}
- Storage systems grow quickly in terms of quantity of devices more than many other type of computer systems.
Some of the problems with this idea are:
- The basic solution techniques for queuing network models restrict the models they can solve to "separable queuing networks" which have many limitations (e.g. no priority scheduling, uniformity of service demands, no fork/join behavior, can't model detailed interactions of parallel processes.) Techniques have been developed to address many of these, but they add complexity and compute time.
- Some performance characteristics of filers are very state-dependent and possibly, difficult to model.
Project Proposal
The project proposal is to investigate whether such models can be used effectively to predict filer performance characteristics, given a filer configuration and a workload characterization. Or do the complexities of filers operation prohibit such prediction? The work would involve a mix of coding up models, measuring specific aspects of filer performance to feed into the models and to validate the models, and researching the literature for techniques or limitations. Ideally, a prototype of a modeling tool would be developed.
Possible Applications of the Model
Sizing, problem diagnosis, capacity planning of filers.
QoS/Storage Provisioning - Tool can be used to possibly evaluate the resources required to provide a certain level of throughput and response time to a given workload.
This project is a continuation of a Fall 2003 Senior Design Project. Previous student work is available as a starting point. This project will put you in a position to become familiar with the C programming language and the architecture of storage systems (experience with the C programming language and filers is useful, but not required).
Celerra Configuration Replicator
Project Description
The EMC Celerra File Server is EMC's flagship Network Attached Storage product line. There are several versions of the product (as shown in Figure 1), but they all share the same operating system and management interface. Internally & in the field we are encountering greater needs to setup a Celerra file server and then use that configuration as a template for other file servers. The management interface for the Celerra is a Web based management tool that is supported underneath by an API interfaced via XML and a CLI interface. This project would develop a prototype of a tool which captures a description of a configuration, and recreates that configuration on another system. It is expected that the student team will define the requirements, develop what scope can be completed during the semester, and execute their plan with technical assistance from EMC engineers.
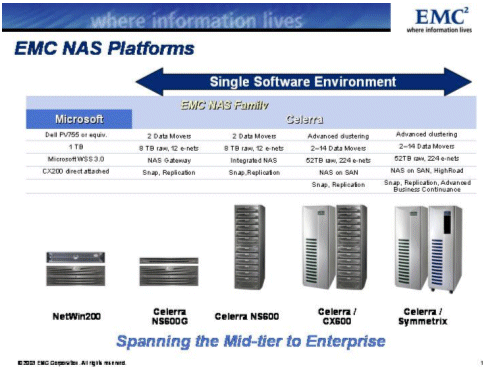
Figure 1, EMC NAS Platforms
Deliverables
- Requirements definition document which includes results from:
- Understanding the type of configuration data to be retrieved
- Investigation to determine the dependencies between objects in the configuration description (pre-conditions and sequencing)
- Investigation to determine the best way to replicate the configuration on multiple ip addresses or hostnames with a single invocation
- An architectural design definition
- Functional specification(s) for construction of the actual software
- Weekly written status reports on progress.
- Software tool to retrieve the configuration data.
- Software tool to interpret the configuration data, establish pre-conditions and sequencing, and recreate the configuration on one or several other systems.
- Verification tool that demonstrates the configurations are the same.
- Source code and scripts for the actual tools, any tool or test software sources, and documentation (user's guide) for the implementation.
- Test specification defining use cases and test assertions, test tools, and a test report demonstrating how the software performed relative to each test case and assertion.
- Overview presentation and written report outlining the requirements, the methodology, software components, implementation, results, and lessons learned based on the work done.
Resources needed: Desktop workstation, JRE, JDK, Access to a CNS cabinet (will be provided remotely by EMC).
Recommended skill set: Basic web development, Java, JSP, Scripting, XML.
Company Background
EMC Corporation is the world leader in information storage systems, software, networks, and services and the only company 100% dedicated to automated networked storage.
EMC Automated Networked Storage combines SAN, NAS, and CAS environments into an integrated networked storage infrastructure. It unifies networked storage technologies, storage platforms, software, and services to enable organizations to better and more cost-effectively manage, protect and share information.
As a result, customers are able to reduce costs through consolidation of storage and server resources, centralize and automate manual storage management tasks, and improve overall business continuity and flexibility.
The Research Triangle Park Software Design Center is an EMC software design center. The 200+ developers working there develop world-class software used in our NAS (Network Attached Storage), SAN (Storage Area Networking), and storage management products.
Value to EMC
Internally, we need a way to easily duplicate a system configuration multiple times across many lab systems at one time. The tools from this project will help us to save time and effort in performing these operations. This project provides a proof-of-concept for one way to meet this need.
The Research Triangle Park Software Design Center is an EMC software design center. The 200+ developers working there develop world-class software used in our NAS (Network Attached Storage), SAN (Storage Area Networking), and storage management products.
Enhanced Graphing Applet for an Engineering Web Application
Introduction
WebWorks is a part of the Information Systems department within John Deere's Commercial and Consumer Equipment Division (C&CE) that develops internet, extranet, and intranet applications for John Deere. They work as a set of internal consultants to the division. WebWorks focuses on providing cost effective solutions written using solid industry techniques and open standards. WebWorks is a small group of programmers practicing Extreme Programming.
Description
One of the ways John Deere provides Genuine Value to its customers is by building the most reliable product. Reliability is an aspect that can be engineered into our products. It is proven by durability testing, lab work, and design reviews. We have built a system that allows our engineers to track the reliability of our products. The web based system has some simple graphing features to display the engineering data. We would like the Senior Project team to overhaul the graphing tool and add some advanced graphing capability. The Graphing software is written in Java and runs within a java web application. You will gain experience in XML, Java Applets, Java graphics toolsets. You will get a chance to work with members of the John Deere WebWorks application development team.
As WebWorks works in an XP environment, we suggest that the Extreme Programming methodology be followed when developing this application:
- Plan and scope out each release. Prioritize tasks.
- Small releases - every release should be as small as possible and should contain the most important business requirements. Release often.
- Simple design.
- Testing
- Test cases should be developed that can be used in acceptance testing.
- Test first coding can be used to integrate Unit testing into the design. (JUnit)
- Pair programming.
- Collective ownership - anyone can change any code anywhere.
- Coding standards - document code, format code so its easier to read and follow.
Ad Hoc Wireless Networks
Project Description
The goal of this project is to investigate and develop algorithms for transferring data through an ad hoc wireless network. The target technology for this project will be Berkeley "Mica Motes" (available through CrossBow Technologies). "Motes" are small, battery-powered (2xAA), power managed microprocessors with on-board wireless transceivers (916 MHz ISM band). The range of MICA2 transceivers is estimated to be about 1000 ft. Data to be transferred through the ad hoc network is sensor based. Multiple-packet data streams are sourced from sensors attached to mobile motes. The challenge is to build a system in which an ad hoc (but fixed) network of relay mote transceivers will recognize the presence of a mobile source mote transceiver, and permit a data stream relay operation to occur from the mobile sensor through the ad hoc relay network to a pre-specified target base station. The initial use envisioned for such a system is a wildlife tracking application. Specifically, tracking endangered red wolves (rufus canis) recently re-introduced into the Alligator River Wildlife refuge in Eastern North Carolina.
This project is a continuation of a Fall 2003 Senior Design Project. Previous student work is available as a starting point.
Project Description
Progress Energy generates Key Performance Indicators (KPIs) to monitor and track numerous safety and performance goals to enable the opportunity for continuous improvement across the company's fleet of generating plants. Currently, monthly KPI reports are generated for each of the four nuclear plants and for the entire Nuclear Generation Group (NGG) in five distinctly separate Microsoft Access databases. The aim of this project is to develop a prototype web-based tool utilizing Microsoft Development tools and Microsoft SQL*Server that can be used across Energy Supply (Nuclear, Fossil, Hydro-Electric (Hydro), Combined Cycle (CC), and Combustion Turbine (CT) plants) generation plants that enable the roll-up of KPIs. The application would enable both manual input of KPI data and automate capture with the ability to generate standard reports using the KPI Microsoft Graphic report templates currently employed in the company.
OPOS Device Simulators
Fujitsu Transaction Solutions is one of the top three suppliers of retail systems and services worldwide. Its integration of Microsoft DNA" (Distributed InterNet Architecture) creates a high performance yet open platform that retailers as diverse as Nordstroms and Payless Shoe Source are able to customize.
OLE for Retail POS (OPOS) is an object-based programming environment for the development of Point-of-Sales (POS) terminal applications. OPOS allows POS developers to run their applications unmodified across a complete range of industry standard POS terminals and peripherals. This provides retailers with increased flexibility and reduces the effort required to ensure cross-platform operations for POS applications developed using the OPOS standard. OPOS reduces the cost of development usually associated with developing applications for proprietary hardware peripherals.
Epson, NCR, and Fujitsu in conjunction with Microsoft developed the OPOS specification. This specification describes the OLE control architecture that allows hardware and software vendors to use highly productive development environments, such as Visual Basic, to create POS application software in a device independent manner.
The goal of this project is to enhance OPOS Device Simulators.
(C#, Visual Basic.Net, Windows XP/2000)
Project Description
Developing GUI-based wysiwyg user interfaces for browsers is cumbersome and time consuming. Non-trivial interfaces require layout coding as opposed to the friendly drag and drop interface provided by most rich-client IDE's (e.g., Visual Basic). This project should provide an easy to use GUI editor for building browser based user interfaces. The editor should support the placement of both HTML tags and JSP custom tags. It should allow tags to be layered such that visibility is controlled by the underlying code. It should allow for the visual placement of tags using drag and drop. It should provide an editor for modifying tag attributes. Lastly, the editor should be made available as an Eclipse plug-in.
Learning About The Red Wolves of Eastern North Carolina
Overview
The overall goal of the NC State Computer Science "PackTracker" project is to investigate the prospects for improving wildlife tracking capability by applying a new computer technology. This new technology integrates battery powered computers, a variety of sensor based devices and short range (wireless) radio transceivers. One example of such a system has been developed by researchers at UC Berkeley. The Berkeley system has been described as "Smart Dust" because the potential exists for such a system to be manufactured in a very small form factor -- approaching dust particle size (hence the term "Motes" to describe these computer elements), and manufactured very inexpensively -- to the point of disposable. A commercial version of such a system is currently available through Crossbow Technologies. Although the form factor (about the size of two AA batteries) and cost (approximately $160 each) are not quite a disposable dust mote, the trend is clear.
In anticipation of this trend to smaller and cheaper sensor based computing devices, there are several computer system research issues that must be investigated before this new technology can be successfully applied to a wildlife tracking application. Previous work of students in the Senior Design Center of the Computer Science Department at NC State University has resulted in the design of a novel computer system architecture that could be applied to improving quality and quantity of tracking data related to the Red Wolf population recently re-introduced into the wild in Eastern North Carolina.
This wildlife tracking computer architecture has three major subsystems: The first subsystem is dedicated to collecting sensor data; The second subsystem is focused on collecting data from the sensor elements and relaying this data to a permanent database; The third subsystem includes the permanent database and concentrates on data organization, data visualization, and data mining.
Available sensors include the ability to detect temperature, night/day, acceleration, and gps-based location information. If these sensors are placed in a collar on a given animal, the Mote system has sufficient battery power and memory capacity to store tracking data over an extended time period, perhaps as long as six months. The sensor subsystem also would have the capability to interchange sensor data as each collared animal wanders into the vicinity of another collard animal (approximately a radius of 500 feet).
The data relay subsystem (also referred to as the network subsystem) is defined as a collection of Motes programmed with the capability to detect collared animals in the vicinity (approximately a radius of 500 feet) of a given network Mote, and off-load tracking data collected for (and by) that particular animal. The network design includes the capability to detect an animal and relay data from the location of that interception to a permanent database located as much as a mile away. In the case of denning animals, the network subsystem could be positioned near (but not necessarily in) the den site. A network subsystem of ten to twenty nodes is planned.
Pre-prototypes of these three subsystems (sensors, network, and database) have been designed and implemented by previous teams of computer science students. This has demonstrated the overall feasibility of this approach. Each subsystem has its particular challenges and each needs further investigation and refinement. By far, the most challenging work lies in the network subsystem. The wildlife tracking application we have just outlined creates the need for new algorithms and programs.
The goal of this project is to refine existing programs for both the sensor collection and data relay subsystems and demonstrate system functionality. This demonstration would take the form of several (three or four) students equipped with a (very rough) collar prototype traversing several acres of terrain while tracking data is collected. (Thus simulation roaming wolves!). One corner of this terrain would be established as the denning area. As students wander into and out of the denning area, tracking data would be relayed to a base station.
Voice Activated WI-FI Alarm Clock
Description
The Voice Activated WI-FI Alarm Clock is a small home NetApp that can be bedside or hung on a wall. The clock has all the normal functions of an alarm clock including manual controls. When a PCMCIA wireless card is added to the clock, it becomes a small networked computer appliance with access to the internet.
Normal functions:
Normal alarm clock functions
Advanced functions:
User trained voice activated commands:
- Time set
- Alarm On/Off/Set
- Volume Up/Down
- Snooze
Internet radio commands:
- News
- Weather
- Sports
User profiles:
- Internet radio sites
- Websites
- MP3 sites
Technical specifications:
Software
- Linux OS
- Web configuration
Hardware
- Standard Voltage
- Ethernet interface
Legend Web Search - An Internet Search Engine For Design Engineers (Think Google CAD Search!)
We would like the students to create a scalable web crawler to search the web for engineering content and make it easy to find. This project has two major components: Crawler Technology and Engineering Document Meta Data Organization.
Crawler Technology
The Crawler architecture needs to use of multiple Windows hosts to search the web. With many crawlers simultaneously searching the web care must be taken that each crawler searches a different portion of the web. Results from each crawler will be combined into a single database (see Metadata Organization below).
The search targets are engineering drawings such as AutoCAD.DWG files. These files are available on the internet for use by design engineers, but can be hard to locate.
The crawler process will include capturing related information from the web site, downloading the CAD file, calling I-Cubed's CAD Component to extract additional metadata from the CAD file, and creating an image of the CAD file such as jpeg or AutoCAD's DWF. The information will then be passed to the Metadata Organizer for cataloging.
The engineering content can be seeded with URLs for known manufacturers of engineering content (e.g. http://www.soss.com/product/cad/, http://www.smarttech.com/support/product/sb/cad.asp, http://www.cecodoor.com/dwglib.htm, etc) to facilitate finding as much data as quickly as possible. Or search results from other search engines (Google: CAD drawings .dwg) can be utilized.
Metadata Organization
The information gathered by the crawlers must be normalized, organized and classified, automatically. Existing schemes, such as the United Nations Standard Products and Services Code (http://www.unspsc.com/defaults.asp), should be used for the taxonomy functions.
Once organized, the information must be presentable and accessible via standard web browsers. The goal of the system is to create a search engine for engineering content similar to Google's Image Search.
Technology and Skills
The skills and technology that can be used on this project could include grid computing, search engines, internet crawlers, html parsing, database design and html generation.
SCORE-O-MATIC: Grass Roots Sports Reporting
Overview
When people think of spectator sports they typically think of professional sports or major college sports. While these sports obviously have millions of fans, they aren't the only sports with passionate fans. There are over 3 million youth soccer players in the US that play in tournaments and leagues throughout the year. For the parents, grandparents, brothers, sisters, and close friends of these players (likely to be between 10-20 million people), the outcomes of these games are of paramount importance.
In addition to youth sports like soccer, high schools and college club teams play thousands of football, softball, baseball, lacrosse, basketball, ultimate frisbee, etc, games every week - each with a small circle of fans. While these amateur sports are followed by millions, individual games have so few direct fans (20-500 people), that the economics of covering these sports for any sort of traditional media doesn't make financial sense.
With the wide spread availability of the internet, there is now an inexpensive medium for delivering real-time sports updates to small, targeted, audiences. However, somebody has to report on the game for spectators following on the internet -- this is where the Score-O-Matic (SOM) comes in. The SOM allows ad-hoc reporters (likely to be fans and parents) to provide score updates (and in some cases, audio) to a central database through a cell phone or wireless web browser (using WAP).
Fans can view game updates through a web site (either in a "portal view" showing all games during a particular time, or a "tournament" view showing all games, pools and brackets from a particular tournament), or by having information sent to designated cell phones via SMS text messaging.
In addition to accepting score and audio updates via cell phone, the Score-O-Matic will be designed to allow for the uploading of written game recaps, photographs, and game statistics, along with live streaming audio.
Technology & Applicant Background
The Score-O-Matic will use industry leading technologies including: Microsoft SQL server, Microsoft .NET (using C#), IIS, and WAP. Voice response development will use Envox 5.0, text to speech by ScanSoft and voice recognition through Nuance. Knowledge of any of the following tools, C#, .NET, VisualStudio, SQL, XML and/or Envox (fat chance) would be nice, but is not expected.
Marketing
By aggregating the coverage of thousands of amateur games each week, the creators of the SOM look to create a small scale sports network that will offer unique opportunities for advertisers and sports' sponsors. Revenue generated from advertising, premium offerings and services offered to tournaments, teams and league organizers will result in the Score-O-Matic quickly becoming a viable business.
ISG, Inc.
ISG, Inc, a local Raleigh company, is developing the Score-O-Matic. ISG has been in business for over ten years specializing in voice response applications for the healthcare industry. The Score-O-Matic represents a new business for ISG and marketing, prototyping and demonstrations of the product will take place concurrently with the design and development process.
The Score-O-Matic will definitely be completed and brought to market.
A prototype of the Score-O-Matic (as used by the UPA Ultimate Frisbee Championships) can be viewed at: http://www.scoreomatic.com/v3
Background
Do you remember your first semester in college? Did you wish that you had a access to a mentor? An opportunity to get help even though you did not know what you needed? An opportunity to sit and chat with older students or professors?
Project Description
This project is associated with an ongoing research project sponsored by the National Science Foundation called LESSONS (LEarning Styles and Strategies Of eNgineering Students). Over the last two years a team of faculty has learned that the success of engineering students is closely linked to their learning styles, study habits, and motivation to learn. In addition, a large data gathering effort confirmed that the study skills of new students are weak. The goal of this project is to design and build an interactive website that will help orient freshmen engineering students to the academic world of NCSU and offer them opportunities to empower themselves to become effective and successful learners.
Based on this premise, the research team envisions a website that has the following characteristics:
- Engaging and fun to work with (entertaining)
- Meaningful
- Help bridge engineering with the standard course material (Math, Physics, Chemistry, English)
- Relate to Real Life of a student (stress, health, knowing where resources are and how to use them, social network, extracurricular activities "did you know?")
- Relevant to future career
- Helpful tools to assist even before the arrive on campus (study skills, time management)
- Provide opportunities to interact with others (teams, peers, faculty)
- Include a virtual mentoring module
- Easy to maintain and expand
- Secure
- Stand alone (no links to other sites that can go dead)
- ??????
The team is encouraged to expand the list.
The student team should meet regularly with the LESSONS faculty team to define content of this website and to ensure that the project is developing correctly. This project is funded through an NSF grant, and therefore is owned by NCSU and not by the students who develop it.
Opscan Grade Book/Document Management System
The Computer Science Department is acquiring an Opscan instrument. This device includes equipment for Optical Mark Reading (OMR) and additional equipment for scanning written or typed pages to create a document image. Both types of scans are potentially useful for helping the CSC Department manage course evaluations and grade book data.
The goal of this project is to define, design and implement a database for storing/retrieving Opscan data. A detailed requirements specification needs to be developed along with a design for extracting files from the Opscan (online) and reducing and archiving OMR and scanned images into an appropriate database for subsequent retrieval. This design should lead to a prototype system that demonstrates basic functionality.
This project is a continuation of a Fall 2003 Senior Design Project. Previous student work is available as a starting point.
This project is sponsored by NetApp in support of the educational mission of the NC State Computer Science Department.
Tablet PC
The Tablet PC represents another step in the evolution of computing. Features integrated into a Tablet PC include wireless network access and a notepad sized stylus-writable computer screen in addition to everything you expect in a laptop or notebook computer. The goal of this project is to define and prototype uses of this technology that enhance education in the University environment, especially considering the challenges of learning in large classes. Microsoft's "One Note" is a new software product that illustrates the potential of these devices. Two Tablet PCs will be made available to the team. Possible avenues for development include, but are not limited to, an evaluation of the features and facilities of "One Note," the development of the concept of a sharable whiteboard, real-time feedback to an instructor, classroom polling and voting, reliable identification and attendance. Another possible area of emphasis is enhancement of distance education using a Tablet PC.
The team assigned to this project will be expected to interview faculty and students to identify likely areas for exploration, prioritize these areas and define specific Tablet PC applications that enable learning, and demonstrate results in one or more of these areas by the end of the semester.
This project is a continuation of a Fall 2003 Senior Design Project. Previous student work is available as a starting point.
This project is sponsored by NetApp in support of the educational mission of the NC State Computer Science Department.
Network API Project
Current usage of Red Hat Network requires the usage of a web interface. For example, if a sysadmin wants to install an updated glibc package to 300 systems across a network, the sysadmin must go the the RHN website, select the systems, schedule the installation of the update, and then track the status of the update, all from the web UI.
The disadvantage of a web UI is that many enterprise customers prefer to perform these kinds of actions programatically. For example, a sysadmin may use a separate networked application to monitor load on certain systems; such a sysadmin may need this load data to decide when systems might be upgraded safely. An effective API would allow the sysadmin to script these upgrades based upon the load data from this other application.
The Red Hat Network API Project will have four phases.
In Phase One, engineers will work with the RHN project lead to identify key customer requirements. Every customer says "I want an API to do everything that I can do from the web interface," but realistically, this is neither practical nor sensible. The Phase One deliverable will be the minimal list of API calls that will satisfy the majority of our customer requirements. (3 weeks)
In Phase Two, engineers will code the API calls identified in Phase One. With the assistance of the project lead, engineers will learn RHN's current API framework and business logic. The Phase Two deliverables will be the complete set of API calls and simple client code to test each API. (4 weeks)
In Phase Three, engineers will use the client code to compile a test suite for the APIs. Automated test cases are absolutely essential to ensure ongoing compatibility of these APIs. The Phase Three deliverables will be a test suite for the entire set of APIs that will be suitable for integration into our development build system. (4 weeks)
In Phase Four, engineers will develop their own sample application using the RHN API. This application should demonstrate the usefulness of the API in an enterprise systems management environment. The Phase Four deliverable will be an application suitable for demo use for Red Hat Network's enterprise customers. (4 weeks)
The Red Hat Network API Project will require engineers with the following skills or interests:
- Familiarity with Perl in an OO context. The current RHN web infrastructure and API framework are Perl-based.
- Familiarity with relational database concepts. The backend of RHN is Oracle.
- Familiarity with, or interest in, web services protocols. RHN uses XMLRPC as the transport mechanism for its API calls.
Red Hat Network is a web services platform designed to simplify the deployment and management of Red Hat solutions in the enterprise. It is a central element of Red Hat's Open Source Architecture. Read more about Red Hat Network at: http://www.redhat.com/software/rhn/
Network TFTP Project
Dynamic Host Configuration Protocol, or DHCP, is best known for its ability to allocate IP addresses dynamically to systems over a network. However, DHCP also allows for more complex and interesting host configuration possibilities.
There are several ways to boot a system remotely. Red Hat prefers the use of PXE (preboot execution environment). Together, a DHCP server and a TFTP (trivial file transfer protocol) server can be set up to handle PXE boot requests.
One of the limitations of current TFTP server implementations is that content can only be delivered based upon static configuration files on the TFTP server. Red Hat Network keeps a lot of data about a lot of host systems, and we're looking to extend TFTP so that it can call out to RHN dynamically to make use of some of that data, instead of relying on TFTP's static configuration files.
The Red Hat Network TFTP Project will have two phases.
In Phase One, engineers will build a DHCP and a TFTP server, and will learn the mechanics of delivering PXE boot requests over a network. Engineers will also learn about RHN's Provisioning offering, and will work with the RHN project lead to develop a technical proposal to extend TFTP to make use of this data. The Phase One deliverable will be a technical requirements document for this proposal. (3 weeks)
In Phase Two, engineers will code the TFTP extensions proposed in Phase One. Engineers will develop iteratively according to milestones identified by the engineering team, with input from the RHN project lead. Engineers will be required to present unit tests for each significant component of the implementation. The final Phase Two deliverable will be a full implementation of the technical requirements from Phase One, suitable for release as a GPL product. (12 weeks)
The Red Hat Network TFTP Project will require engineers with the following skills or interests:
- Familiarity with C. tftp-server is written in C, and engineers will be working on this particular application.
- Familiarity with the concepts of DHCP and remote boot.
- Familiarity with, or interest in, web services protocols. The implementation of these extensions will likely involve the incorporation of an XMLRPC client into tftp-server.
Red Hat Network is a web services platform designed to simplify the deployment and management of Red Hat solutions in the enterprise. It is a central element of Red Hat's Open Source Architecture. Read more about Red Hat Network at:
Network Java RPM Project
Red Hat Network distributes software to its clients in the form of RPM files. One of the great strengths of RPM (RPM Package Manager) is that it tracks dependencies between packages. For example, the "up2date" package requires that certain versions of the "python" package must be installed. RPM represents these dependencies properly, and Red Hat Network provides a mechanism for resolving these dependencies and finding additional packages.
Red Hat Network will be undergoing a significant shift over the next several months, shifting to an entirely Java-based application stack. This presents a key problem where RPM is concerned. RPM has an API written in C, and sets of bindings in Python and in Perl. These bindings are necessary to use RPM's dependency resolution libraries. Currently there are no Java bindings for RPM at all.
The Red Hat Network Java RPM Project will have two phases.
In Phase One, engineers will map out the current set of RPM API calls, with special attention paid to the subset of calls currently used by RHN through the Python bindings. Engineers, with the assistance of RHN project lead, will identify the key API calls, rank these calls in importance, and scope the work of developing Java bindings for each of these calls. This completed document will be the deliverable for Phase One. (4 weeks)
In Phase Two, engineers will work to implement Java bindings for the most important API calls as defined in the Phase One deliverable. Engineers will work down this list, implementing as many of the features as the schedule permits. The ideal deliverable for Phase Two would be a full implementation of RPM bindings for Java. An acceptable deliverable will include all API calls used by RHN with the corresponding Python bindings. (10 weeks)
The Red Hat Network Java RPM Project will require engineers with the following skills or interests:
- Familiarity with C. RPM APIs are written entirely in C.
- Familiarity with Perl or Python. Both of these languages provide bindings to the RPM APIs, and either would provide assistance in understanding how API bindings are written.
- Familiarity with Java. Obviously, familiarity with Java will be required to write the Java bindings.
Red Hat Network is a web services platform designed to simplify the deployment and management of Red Hat solutions in the enterprise. It is a central element of Red Hat's Open Source Architecture. Read more about Red Hat Network at:
Network Message Bus Project
Red Hat Network is a network application stack that is primarily pull-based. Information about RHN-managed systems is managed centrally. When an admin needs to change the configuration of a system or group of systems, he schedules the change centrally, and each RHN client checks in periodically to see if any actions have been scheduled for that particular client.
The advantage to this mechanism is that when client check-in times are properly dispersed, RHN may serve many more clients. The disadvantage, however, is that an admin must wait for systems to check in, and in many cases, this wait is unacceptable.
One option is to put RHN listener clients on each system. This would allow the RHN server to pass commands to the client directly. However, this approach might place unreasonable demands on the server if it were required to communicate with 10,000 clients simultaneously.
Another approach is to build a network message bus. In this case, certain clients could connect to the bus, and the server could simply broadcast commands to the message bus. Scaling up to handle lots of clients could then become more a function of the bus architecture itself; for instance, bridge clients could be added to the bus to handle complex routing of messages, thus removing this burden from the central server.
Just about everybody uses a network message bus. Anyone who's used IRC or AOL Instant Messenger knows the basics: client signs on, client exchanges messages with other clients via a central server that routes the messages. In this case, the bus would be used not for person-to-person communication, but for system-to-system communication.
The Red Hat Network Message Bus Project will have four phases.
In Phase One, engineers will learn about the Jabber protocol and research its suitability as a message bus platform. Engineers will work with the RHN project lead to assess Jabber's fitness in terms of scalability, extensibility and reliability. Engineers will also learn about some of the other messaging platforms like Spread and IRC. The Phase One deliverable will be a document outlining the strengths and weaknesses of Jabber, and an assessment of the risks associated with using Jabber. If the engineers determine that Jabber is wholly unsuitable for this task, then the deliverable must propose an alternate solution. (3 weeks)
In Phase Two, engineers will install a messaging server and build a simple messaging client based upon the technology identified in Phase One. The messaging client should demonstrate a basic understanding of how a client talks over a message bus. This client will likely be built from commonly available libraries. The deliverable for Phase Two will be a functionalclient that will serve as the basis for future development. (3 weeks)
In Phase Three, with assistance from the RHN project lead, engineers will identify the particular kinds of messages that RHN server and RHN clients will need to pass along the bus. The deliverable for Phase Three will be a specification of this RHN-specific messaging protocol. (3 weeks)
In Phase Four, engineers will extend both the client and server code to implement the functionality specified in the Phase Three deliverable. The goal will be to have server that dispatches messages to many clients, and clients that dispatch actions based upon those messages in real time. The Phase Four deliverable will be a client/server application that conforms to the specification. (5 weeks)
The Red Hat Network Message Bus Project will require engineers with the following skills or interests:
- Familiarity with C. Most of the code out there will be C code.
- Familiarity with network programming concepts.
Red Hat Network is a web services platform designed to simplify the deployment and management of Red Hat solutions in the enterprise. It is a central element of Red Hat's Open Source Architecture. Read more about Red Hat Network at:
Enhancement of the E.P.S. Framework
Expert Process Solutions LLC (EPS) provides an analysis framework, process map templates and top-down methods to assist companies in their efforts to document their business processes. The E.P.S. Framework™ is a business modeling and analysis tool that easily models business operations and enables the documentation of internal corporate processes to help business leaders identify improvement opportunities. In addition to evaluation of operations, the E.P.S. Framework™ product and has the added advantage of helping companies comply with the new process documentation requirements of the Sarbanes-Oxley Act, enacted in the wake of governance scandals at Enron and other major corporations. The Framework will be maintained by a few power users and be accessed by Internal and External Auditors and managers.
The existing E.P.S. Framework™ is an Access 2002 Database application. The application consists of a database with four primary tables in a hierarchical structure and three views that represent the structure of a business in a three level model. In addition, an Assessment Table provides properties that relate to two of the model levels. The framework database comes populated with models of company structures and process diagrams in PowerPoint format. (Access has functionality for viewing and editing PowerPoint slides stored in an Access DB.) Example Assessment properties are also provided.
This project consists of information technology, usability and security enhancements to the product. Specifically:
- The existing views use MS Access™ "Forms" for display of information to users. These views must be converted to a Visual Basic implementation for display and update. PowerPoint OLE capabilities provided by Microsoft in the Access database must be retained in the VB "view" application. In addition, some minor logic and calculation functionality must be added to the VB display application.
- New Visual Basic programs must be constructed for an initial database load that will enable users to create a custom framework to model a specific business. This will include "copy" functionality to enable a newly created framework to be populated from the present Access DB, which is distributed to users on a CD. The Access database should be retained for distribution purposes, which consists of tables with both data and PowerPoint OLE Objects in the fields of each record.
- Create the ability to link the display and update VB views to a SQL Database on a server. Provide record-level security for read-only user access and viewing of database segments in a corporate server setting.
- Reporting: develop standard queries and reporting capabilities with summary totals where needed. Provide the ability to easily upload and download certain table information from Excel spreadsheets.
- PowerPoint Functionality enhancement: enabling easy creation of Process diagrams for two of the three levels. Standard block objects are used to create diagrams for each of the two levels. Create a "drag and drop" tool to place drawing blocks on a grid and make line connections between on or more with simple click commands. Provide the ability to add notes to specific locations on the drawing. The VB views should be enhanced to provide the ability to create the diagram in a window of the view. The application is designed for the diagram view and the properties data to be viewed in the same screen or window.
- Create an application to adapt elements (to be defined) of the three views to a corporate internal website.
Deliverables:
- Three Visual Basic programs to permit viewing and updating the access database with the ability to be redirected to an SQL Server DB (with security features for the SQL Server DB).
- Visual Basic programs to create and populate a new database model of a company.
- Standard reports from both the Access and SQL database.
- A drag and drop tool providing a subset PowerPoint functionality to be integrated into the VB applications defined in Deliverable #1, above.
- Application for selecting items from the DB for internal website viewing.
The goal of the Fourth Annual Computer Society International Design Competition (CSIDC) is to advance excellence in education by having student teams design and implement computer-based solutions to real-world problems. The theme of this year's CSIDC is Added Value: Turning Computers Into Systems. Teams are encouraged to take a PC, laptop, hand-held computer (or similar device) and use additional low-cost hardware/software to create a computer-based solution to a problem that is socially valuable. Add-on cost must be less than $400 (this cost will be paid by the Senior Design Center). First Prize is $15,000 to be distributed among the students on the team. Total of all prizes to be awarded to students is $37,000.
For more information check http://www.computer.org/csidc/
Project Archives
| 2026 | Spring | Fall | |
| 2025 | Spring | Fall | |
| 2024 | Spring | Fall | |
| 2023 | Spring | Fall | |
| 2022 | Spring | Fall | |
| 2021 | Spring | Fall | |
| 2020 | Spring | Fall | |
| 2019 | Spring | Fall | |
| 2018 | Spring | Fall | |
| 2017 | Spring | Fall | |
| 2016 | Spring | Fall | |
| 2015 | Spring | Fall | |
| 2014 | Spring | Fall | |
| 2013 | Spring | Fall | |
| 2012 | Spring | Fall | |
| 2011 | Spring | Fall | |
| 2010 | Spring | Fall | |
| 2009 | Spring | Fall | |
| 2008 | Spring | Fall | |
| 2007 | Spring | Fall | Summer |
| 2006 | Spring | Fall | |
| 2005 | Spring | Fall | |
| 2004 | Spring | Fall | Summer |
| 2003 | Spring | Fall | |
| 2002 | Spring | Fall | |
| 2001 | Spring | Fall |