Projects – Spring 2025
Click on a project to read its description.
Sponsor Background
Aspida is a tech-driven, agile insurance carrier based in Research Triangle Park. We offer fast, simple, and secure retirement services and annuity products for effective retirement and wealth management. More than that, we’re in the business of protecting dreams; those of our partners, our producers, and especially our clients.
Background and Problem Statement
Our Operations team handles calls from external sales teams and direct clients. Often our Operations associates are new college grads with little experience. Often they are not able to solve a problem without assistance and sometimes require a call back. We have historical data which could be used as a knowledge base but it's unstructured and not searchable.
Project Description
Our project is to build an LLM using historical data – call logs, chat logs, product knowledge. The LLM will be utilized as an assistant for Operations associates to quickly resolve problems while on the phone with the customer. Further, we have some stretch goals in mind which could include automating a response using AI generated voice or text.
Technologies and Other Constraints
- Data sets – we are assuming data sets will be in JSON format
- LLM – we prefer using Claude with Bedrock on AWS
- Cloud Environment – AWS preferred
- UI – React
- Backend – Node.js
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Through a collaboration between Poole College of Management and NC State University Libraries, we aim to create an innovative open educational resource. Jenn, a recipient of the Alt-Textbook Grant, has already developed an open source textbook for MIE 310 Introduction to Entrepreneurship. Our upcoming focus now involves creating open source mini-simulations as the next phase of this initiative.
Background and Problem Statement
Currently, there is a significant lack of freely accessible simulations that effectively boost student engagement and enrich learning outcomes within educational settings. Many existing simulations are typically bundled with expensive textbooks or necessitate additional purchases. An absence of interactive simulations in an Entrepreneurship course diminishes student engagement, limits practical skill development, and provides a more passive learning experience focused on theory rather than real-world application. This can reduce motivation and readiness for entrepreneurial challenges post-graduation.
Our primary goal is to develop an open source simulation platform that initially supports the MIE 310 course, but could be later made accessible to all faculty members at NC State and eventually across diverse educational institutions.
Project Description
The envisioned software tool is a versatile open source tool designed to create visual novel-like mini-simulations with content and questions related to a certain course objective. The intent is to empower educators to be able to create their own simulations on a variety of different topics. Faculty will be able to develop interactive learning modules tailored to their teaching needs. This tool needs to be able to export grades, data, and other relevant information based on the following requirements:
- Introduce the scenario in a welcome screen, including text and images
- Have an end of simulation screen that displays the users’ grade
- Allow for multiple simulations to be run back to back
- Export grades and user to a database to be used by Moodle to grade the student
- Update system design
- Create a website for students to access the simulation by logging in with their NCSU credentials
Technologies and Other Constraints
All resources used must be created with the open-source tools as the Alt-Textbook project is open source. For maintainability and extension, the software must be full stack web-based and not use a gaming engine.
Sponsor Background
The Undergraduate Curriculum Committee (UGCC) reviews courses (both new and modified), curriculum, and curricular policy for the Department of Computer Science.
Background and Problem Statement
North Carolina State University policies require specific content for course syllabi to help ensure consistent, clear communication of course information to students. However, creating a course syllabus or revising a course syllabus to meet updated university policies can be tedious, and instructors may often miss small updates of mandatory text that the university may require in a course syllabus. There is additional tediousness in updating a course’s schedule each semester. In addition, the UGCC must review and approve course syllabi as part of the process for course actions and reviewing newly proposed special topics courses. Providing feedback or resources for instructors to guide syllabus updates can be time consuming and repetitive, especially if multiple syllabi require the same feedback and updates to meet university policies.
Project Description
The UGCC would like a web application to facilitate the creation, revision, and feedback process for course syllabi for computer science courses at NCSU. An existing web application enables access to syllabi for users from different roles, including UGCC members, UGCC Chair, and course instructors (where UGCC members can also be instructors of courses). The UGCC members are able to add/update/reorder/remove required sections for a course syllabus, based on the university checklist for undergraduate course syllabi. Instructors are able to use the application to create a new course syllabus, or revise/create a new version of an existing course syllabus each semester.
We are building on an existing system. The focus this semester will be on adding the idea of schedule functionality to the syllabus tool. Additionally, there are several process improvements that should be made to support future deployment of the system.
New features include:
- Update how syllabus changes are handled. Instructors, course coordinators, and UGCC members should be able to make changes to syllabi for any given semester at any point. Finalized, template-level changes will update down-stream syllabi.
- UGCC members can add important semester dates like last day to add classes, drop/revision deadline, and last week of classes.
- Section blocks should be expanded to include a schedule block for listing class topics and dates.
- When copying a syllabus for a new semester, the instructor can add the teaching schedule and there is a first attempt at updating the schedule to the new semester’s dates.
- Instructors can upload a schedule file that can populate a schedule block.
- Provide functionality for downloading the syllabus in multiple formats like *.docx, *.pdf, *.md.
- Process improvements include:
- Automated frontend testing
- GitHub actions that will run tests and report statement coverage
- Scripts to support VM deployment
Stretch goal:
- Usability testing by CSC faculty
Technologies and Other Constraints
- Technologies are based on extending the existing codebase, which uses:
- Docker
- Java (for the backend)
- PostgreSQL
- JavaScript (for the frontend)
- The software must be accessible and usable from a web browser
Sponsor Background
Katabasis is a non-profit organization that specializes in developing educational software for children ages 8-15. Our mission is to facilitate learning, inspire curiosity, and catalyze growth in every member of our community by building a digital learning ecosystem that adapts to the individual, fosters collaboration, and cultivates a mindset of growth and reflection.
Background and Problem Statement
It can be difficult for everyone to consider the long-term effects of their decisions in the moment, but particularly difficult for students with emotional and behavioral disorders (EBD). Students with EBD will often have increased rates of office discipline, suspension from school, and poor academic performance. Long-term outcomes for students with EBD also suffer as a result, including a significantly greater likelihood for school dropout, high unemployment, low participation in postsecondary education, increased social isolation, and increased levels of juvenile and adult crime.
By encouraging these students to give structure to and reflect on their decisions, we can empower students with EBD to take control over their thought processes and incentive structures. To this end, Decision Intelligence provides an excellent framework for decision modelling, and is highly scalable to all levels of technical fluency.
Project Description
We are seeking a group of students to develop a web interface for middle school students sent out of the classroom (or otherwise dealing with emotional or behavioural issues) to interact with to attempt to better understand their actions, external factors, and outcomes.
Developing an intuitive and approachable interface will be the key to success in this project. It should consist of an elicitation portion, display portion, and editing portion. For the elicitation portion, there should be a gamified way of getting the details of the situation from the student. This can take the form of a literal browser game, or be more indirect, such as phrasing questions in a more whimsical fashion with engaging graphics. The key is to make it approachable and intuitive. For the display portion, we want to see a clear flow from actions to outcomes, as established by the decision intelligence framework (which we will provide the team further details on). The goal here is to make it clear to the users how different actions can lead to different outcomes. We recommend a causal decision diagram (which we can again provide more documentation for), but are open to creative ways to display the same information. Finally for the editing portion, we want to make sure users are able to tweak and adjust the display that has been generated to better match their reality. The elicitation will likely never generate a perfectly accurate display, so we want to make sure users are able to refine the display until it best matches their actual real life circumstances.
In summary, the game should be developed around the following core feature set:
- Gamified and Intuitive Interface: The web platform created must be highly approachable and intuitive, given its target users are likely to have short attention spans and high potential for bouncing off or getting frustrated with systems they can’t understand. Making sure the experience
- Decision Intelligence Framework: The backbone of the system is the Decision Intelligence framework. This consists of a way of structuring the decision making process by identifying levers (or actions), external factors affecting your decision, intermediate factors that act as stepping stones to the final factor, outcomes, the things you are measuring as an end result. Ensuring the interface developed highlights and clearly communicates these factors is essential.
- OpenDI Toolset: The team will adhere to the open source OpenDI standards, which has some data protocols and initial codebases to branch off of. This will provide the team with some initial guidance on DI software development toolsets, and also give experience in working with open source projects.
Technologies and Other Constraints
We encourage students to utilize, adhere to, and potentially contribute to the OpenDI framework.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Dr. Lavoine is an Assistant Professor in renewable nanomaterials science and engineering. Her research exploits the performance of renewable resources (e.g., wood, plants) in the design and development of sustainable alternatives to petroleum-derived products (e.g., food packaging). As part of her educational program, Dr. Lavoine aims to help faculty integrate sustainability into their curriculum to raise students’ awareness of current challenges on sustainable development and equip them with the tools to become our next leaders in sustainability.
Background and Problem Statement
In June 2024, Dr. Lavoine and three of her colleagues offered a faculty development workshop on sustainability that introduced a new educational framework to guide faculty in the design of in-class activities on sustainability.
This platform integrates three known frameworks: (1) the pillars of sustainability (environment, equity, economy), (2) the Cs of entrepreneurial mindset (curiosity, connection, creating value) and (3) the phases of design thinking (empathy, define, ideate, prototype, implement, assess). For ease of visualization and use, this platform was represented as three interactive spinnable circles (one circle per framework) that faculty can spin and align with each other to brainstorm ideas at the intersection of phases from the different frameworks.
Because this platform only served as a visual tool with no functionality, a group of CSC students took up the challenge in Fall 2024 to build an entire website and database, based on this initial framework, for faculty to design and seek inspiration for in-class activities on sustainability. The CSC students did a great job at designing and programming the front end and the back end of the platform. They have suggested great graphics ideas and have built the entire foundation for users to 1- create an account, 2- upload in-class activities and 3- search for in-class activities.
This website is not quite complete yet. Hence, the purpose of this project is to keep building and designing this website to have a final prototype by June 2025. Indeed, Lavoine and her co-workers will offer this faculty development workshop in June 2025 again. How great would it be for the faculty participants to have this website functioning and ready to use?
Once finalized, Dr. Lavoine intends to share this website with the entire teaching community – and to use it primarily during faculty development workshops on sustainability. Demands from instructors and students on sustainability are exponentially increasing. Now, more than ever, it is important to put in place the best practices in teaching and learning sustainability. It is not an easy task, and research in that field has already shown some tensions between frameworks, systems, etc. The goal of this website is not to tell faculty and instructors what sustainability is about (because there is no single definition), but rather to guide them towards creatively and critically design active learning, engaging activities that raise students’ awareness on the value tensions around sustainability and help them make decisions!
Project Description
As mentioned above, the design of the website and its functionality has been initiated in Fall 2024. It will be important to build on the work that has already been done to make this Spring 2025 project a success.
Looking at the “amazing work” the 2024 CSC team has done, Dr. Lavoine has some ideas to take this website to the next level:
- Replace the previous graphic with a new, visually appealing design showing connections between the three frameworks and enabling user interaction.
- Implement upgrades and untested features from the 2024 website version.
- Add a text box for users to input a summary/brief description of activities during the upload process.
- Represent activities as tiles with an image and title.
- Integrate AI-based image generation based on activity titles and descriptions.
- Conduct usability testing with students and faculty, using feedback forms for improvements.
- Make the platform mobile-friendly and evaluate required changes for usability.
- Develop a student training interface on sustainability using submitted activities.
- Explore tools for faculty to create tests, quizzes, or assignments from uploaded activities.
More ideas are welcome! This website will evolve and get better with your input and your expertise.
Technologies and Other Constraints
Frontend: ReactJS v18.3.1, Backend: Django 4.2.16, Database: MySQL 8.4.2, Containerized with Docker
This platform should be, first, accessible through a desktop/laptop and a tablet (hence, a touch-screen option would be nice), but in the future, why not think about a mobile application or a web platform accessible through mobile.
When it comes to hosting this platform, Dr. Lavoine would consider using first the virtual machine options available at NC State (https://oit.ncsu.edu/about/units/campus-it/virtual-hosting/pricing-and-billing/). If this platform reaches demands and needs beyond expectations, cloud services (such as AWS) could be used.
Sponsor Background
The mentors mentioned above are part of the Enterprise Architecture and Innovation (EAI) division at the North Carolina Department of Information of Technology (NCDIT). They use information technology to make government more efficient, effective, and user-friendly for the public. The EAI team partners with business leaders throughout the state to find innovative ways to solve problems and improve solutions for our customers.
One of the business leaders we have been working closely with over the past two years is the Chief IT Procurement Director for the State of NC, James Tanzosch. James leads the Statewide IT Procurement Office (SITPO) that is responsible for overseeing the procurement of IT goods and services for the state. We have worked with this team to solve many process pain points through innovative solutions, but we still have many more opportunities to improve!
Background and Problem Statement
The NC IT procurement process is a very complex and lengthy process that our end users (agencies) have to navigate for the purchase of IT goods and services. There have been several process changes over the past two years to move an email and paper-based process to a new electronic system that is used for submitting solicitation requests, receiving proposals from vendors, evaluating vendor responses, organizing NCDIT reviews of responses, and awarding a contract to vendors. This has created a more repeatable and transparent process for all to follow.
However, there still is not a user-friendly visual that end users can reference to see where their procurement requests are within the 10-step procurement process, to understand if their request is delayed, and what actions need to be done next. Figure 1 shows the ten steps of the NCDIT IT Procurement Process.


Figure 1: NCDIT 10-Step Procurement Process
Project Description
The vision from the Statewide IT Procurement Office is to create a “pizza” tracker type of visual to show end users where their procurement projects are within the 10-step procurement process. An example of a “pizza” tracker can be seen below in figure 2. In addition to visualizing status, we could make the tracker interactive and/or provide access to available educational content so the end users understands the critical tasks / activities they need to be aware of to progress to the next step within the 10-step procurement process.

Figure 2: Example of a Domino’s Pizza Tracker
This tracker would be beneficial to the end users in a couple of ways:
- The tracker will give end users one location to see their procurement projects, where those projects currently are in the process, and have links / connections to educational information within that same visual. This will keep the end users from having to access multiple systems and sites for this information.
- The educational content linked to this tracker will allow new end users and those not as familiar with the IT procurement process to get up-to-speed on the process quicker. This will help them have a better overall end user experience.
Technologies and Other Constraints
The application will be web-based and mobile-friendly. It must utilize Azure Entra for authentication. The choice of technology stack or framework is flexible, provided that only active open-source technologies are selected.
The application should be designed for deployment to a cloud provider using a standard Docker container. Alternatively, the agency has access to the Power Platform, which can also be utilized for development.
Project and status information will be provided through a predefined REST API (a Swagger file will be supplied). Any additional backend resources developed for this application should adhere to RESTful principles.
If a database is required, it should be a Platform as a Service (PaaS) solution that can be deployed as a native service on Azure. Please note that options from the Azure Marketplace are not currently permitted within the state. It will be important for any proposed developed solution, that the solution is compliant with allowed state technologies. The NCDIT mentor team can work with students to align the requirements as needed.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
The Senior Design Center (SDC) of the Computer Science (CSC) Department at NC State oversees CSC492—the Senior Design capstone course of the CSC undergraduate program at NC State. Senior Design is offered every semester with current enrollment surpassing 200 students across several sections. Each section hosts a series of industry-sponsored projects, which are supervised by a faculty Technical Advisor. All sections, and their teams, are also overseen by the Director of the Center.
Background and Problem Statement
Senior Design involves extensive collaboration among students, faculty, and sponsors. Regular meetings are essential for teams to coordinate their work, report progress, and seek feedback from their sponsors. Scheduling these meetings, however, is a significant challenge. The process often involves numerous back-and-forth communications to find mutually agreeable times, taking into account each participant’s availability, room availability, and potential conflicts with other obligations such as classes or other meetings.
Current tools like when2meet and Doodle facilitate some aspects of scheduling but lack the ability to enforce necessary constraints, such as avoiding scheduling during class times or reserving appropriate meeting rooms. Furthermore, there is no centralized system that allows Senior Design staff and faculty to view and manage all meeting schedules across sections, while still limiting visibility for students and sponsors to their respective teams.
Project Description
For this project, your team will develop a Web application to streamline the scheduling of meetings for Senior Design participants. This application will enhance existing scheduling solutions by introducing additional constraints and functionalities tailored to the needs of the Senior Design Center. The system will have three types of users: system administrators, teaching staff, and team members (students and sponsors).
The entire feature set of the system is not fully determined, so students are welcome to propose useful features. However, the initial system should provide features such as:
All Users
- Authenticated users can initiate a meeting request
- Specify a date range for when the meeting can occur
- Specify a duration for the meeting
- Indicate if virtual or in person
- View expected available time slots of respondents
- The system will produce a unique link that can be shared
- Any user with the link can respond to meeting requests by indicating availability on a calendar view in 15-minute increments. Time blocks can be marked as available or “if-need-be”.
- Responses can be modified
- Prepopulate their profile with typical availability, to serve as a starting point when responding to requests.
- Send messages to participants in meeting requests they are a part of
- Receive notifications for confirmed meeting schedules and updates.
Teaching Staff
- View all meetings scheduled for teams within their sections.
- Filter meetings by team, date, or meeting type.
System Administrators
- Manage “workspaces”, which serve as groupings of users. For example, this can be used to segment users into semesters or similar groupings.
- Manage meeting rooms with a designated Google Calendar each. If the calendar for a room is not busy at a specific time, the room is available.
- Ability to toggle room availability on or off, so that an existing room can be excluded from consideration for a meeting request
- View and manage all scheduled meetings across all sections and teams.
- Assign default meeting durations and room preferences based on meeting type (e.g., sponsor meetings vs. team-only meetings).
- Configure integration with Google Calendar for system-wide and individual availability.
- Assign users into teams and/or sections, as well as define their role in these.
Additional features can be added if time permits, such as setting up recurring meetings.
Technologies and Other Constraints
This will be a Web application running on Docker containers. The backend will expose a REST API and will be written in Node.js with the Express Framework. The frontend will be built using React. The database will use MySQL/MariaDB. Integration with the Google Calendar API will be implemented to sync availability and meeting schedules.
This application will use a combination of Shibboleth and local accounts to authenticate users.
Sponsor Background
SAS provides technology that is used around the world to transform data into intelligence. A key component of SAS technology is providing access to good, clean, curated data. The SAS Data Management business unit is responsible for helping users create standard, repeatable methods for integrating, improving, and enriching data. This project is being sponsored by the SAS Data Management business unit in order to help users better leverage their data assets.
Background and Problem Statement
An increasingly prevalent and accelerating problem for businesses is dealing with the vast amount of information they are collecting and generating. Combined with lacking data governance, enterprises are faced with conflicting use of domain-specific terminology, varying levels of data quality/trustworthiness, and fragmented access. The end result is a struggle to timely and accurately answer domain-specific business problems and potentially a situation where a business is put at regulatory risk.
The solution is either building, or buying, a data governance solution to allow you to holistically identify and govern an enterprise's data assets. At SAS we've developed a data catalog product which enables customers to inventory the assets within their SAS Viya ecosystem. The product also allows users to discover various assets, explore their metadata, and visualize how the assets are used throughout the platform.
Now we have established the lay of the land, let's consider two cases which expose some of the weaknesses of a data catalog:
- As part of some financial reporting, an enterprise has some number of data tables upon which an ETL (exchange-transfer-load) flow is performed to generate a report-ready data table that is used in displaying or generating the content for a report. Currently in our data catalog, we have the ability to identify these individual assets, but only via their lineage are we able to understand their connection. Additionally, we don't have the ability to govern (in terms of authorization, versioning, etc.) all the assets involved in this process (input data tables, ETL flow, report-ready table, report) as a unit, but only as individual assets.
- In an enterprise, data assets are typically owned by a given business unit and for another party/business unit to make use of their data they'll need to go through some type of request process and then get a copy/tailored version of the data asset(s) for the requestor's use case. Currently in our data catalog, you may be able to identify a set of assets and who the owner of those assets is within your enterprise, but there is no formal mechanism for gaining and governing access.
This brings us to a burgeoning concept known as "data as a product "and "data products" in industry (see terminology below). A data product is a combination or set of reusable data assets curated to solve a specific business problem for a data consumer. If we could create the concept of a data product and data product catalog on top of our existing data catalog, we could realize the connections of existing assets and govern their entire lifecycle as one unit.
Terminology
Data as a product is the concept of applying product management principles to data to enhance its use and value.
Data product is a combination of curated, reusable assets (likely datasets, reports, etc.) engineered to deliver trusted data (and metadata) for downstream data consumers to solve domain-specific business problems. A more technical definition of a data product would be a self-describing object containing one or more data assets with its own lifecycle.
Data catalog is a centralized inventory of an organization/ecosystem's data assets and metadata to help them discover, explore, and govern their data.
Data product catalog is similar to a data catalog, but the inventory doesn't consist of an organization's data assets, but it's product. The focus of a data product catalog is to reduce the gap between data producers and consumers to help data consumers solve their domain-specific problems.
Project Description
As part of this project, you'll begin the work of creating a data product catalog. The tool must allow users to define a blueprint/template for a data product (i.e. name, description, shape/characteristics of assets, etc.). After a blueprint is defined, the user must be able to perform an analysis of available metadata and receive suggestions of potentially existing data products in the metadata. If a user believes one or many of the suggestions are accurate, they must be able to create a data product object based on the suggestion.
Data Product Blueprint and Instances
The tool must be able to define a blueprint for a data product (`data product blueprint`) and allow for instances of the blueprint (`a data product`) to be created.
The tool must also support the remaining basic CRUD (create, read, update, delete) operations for blueprints and instances of the blueprints. The tool may support versioning.
As a suggestion, see the following model: https://docs.open-metadata.org/v1.4.x/main-concepts/metadata-standard/schemas/entity/domains/dataproduct
Metadata
The sponsor will provide a script for the generation of synthetic metadata based off the Open Metadata schema (https://docs.open-metadata.org/v1.4.x/main-concepts/metadata-standard/schemas). The generated metadata will be available in a CSV format and the tool must be able to upload or otherwise ingest the metadata.
Identification
Given metadata and a data product blueprint, the tool must allow the user to run a identification algorithm to provide suggestions from the metadata for assets matching the blueprint.
The implementation of the identification algorithm is up to the team, but the algorithm:
- should be performant (to be defined by team in collaboration with sponsors). On a small amount of metadata, the algorithm should run in seconds.
- must provide results as suggestions with some type of ranking/score
- may provide the ability for the user to define any configuration properties for the algorithm
Manual Assignment
Given metadata and a data product blueprint, a user with knowledge of a data product must be able to use the tool to manually create a data product (an instance of a data product blueprint). The creation process must include mapping of metadata to the data assets defined in data product blueprint.
Technologies and Other Constraints
- Any open source library/packages may be used.
- This should be a web application. While the design should be responsive, it does not need to run as a mobile application.
- React must be used for UI.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Bandwidth is a software company focused on communications. Bandwidth’s platform is behind many of the communications you interact with every day. Calling mom on the way into work? Hopping on a conference call with your team from the beach? Booking a hair appointment via text? Our APIs, built on top of our nationwide network, make it easy for our innovative customers to serve up the technology that powers your life.
Background and Problem Statement
As a company, we’re always looking for ways to improve productivity and interpersonal communication. A solution allowing us to see real time analytics about our internal communications platform (Slack) could lead to insights on how we communicate with those both within and across our internal teams.
Project Description
Usage statistics for emojis, both in messages and as reactions to them, show how we express ourselves in the workplace and can be a valuable tool for gauging the feelings and mentalities of our employees, allowing us to act on those insights and create a better workplace environment.
The problem? The data is all retrievable, but we have no meaningful way to view and act on it. The solution: A way to view this data broken down by different metrics in an easily understandable fashion.
We would like to be able to view the total number of times each emoji has been used across a Slack workspace. There could be a table showing the top few, but there should be a way to search for a specific emoji even if it hasn’t been used. It would be nice if we had different views for emojis used in messages, as reactions, and combined. Additionally, we would like to have the same views, but filtered by individual(s) and channel(s). This includes the ability to view an individual(s) emoji usage across specific channel(s).
There may be a place for sentiment analysis in this project. For example, a 👍 likely means the person had a positive reaction to a message, but a 👎 likely means the person had a negative reaction to the message. What about other emojis, like 🙂, that are more ambiguous?
Technologies and Other Constraints
We’d like for this data to be viewable in some kind of web application/dashboard, this should most likely be done in JavaScript/Typescript (maybe React). Feel free to find libraries that provide nice tables and/or graphs. How exactly you choose to represent the data is up to you. The web app should be viewable internally only, meaning we’ll need to deploy it using AWS, potentially via ECS, a lambda, or Elastic Beanstalk.
The back end for this will probably require a database to hold the historical data, as well as an API for grabbing and manipulating the data from the database. Python should be good for this, but it could be done in other languages if you determine some advantage a language offers. Since the project is going to contain at least a front end and back end, it should be Dockerized with a container for each component.
Sponsor Background
NC State DELTA, an organization within the Office of the Provost, seeks to foster the integration and support of digital learning in NC State’s academic programs. We are committed to providing innovative and impactful digital learning experiences for our community of instructors and learners, leveraging emerging technologies to craft effective new ways to engage and explore.
Background and Problem Statement
This project is a continuation of previous Senior Design Projects from Spring and Fall 2024, continuing the development of an editor for creating branching dialogue chatbots. While there is a lot of focus on using AI to power various instances of a "chatbot" system, there is still a tendency for AI-driven chat systems to go "off the rails" and provide unexpected results, which are often disruptive, if not exactly contrary, to the intentions behind a chatbot dialogue simulation where accuracy matters. We have developed a "chatbot" prototype that simulates having conversations in various contexts (conducting an interview, talking to experts, leading a counseling session, etc.) using a node-based, and completely human-authored branching dialogue format. While this guarantees that conversations remain on-script, it also means that a human needs to author the content, and this responsibility currently falls to internal developers on the DELTA team, instead of instructors who have more expertise with the content. We feel like this tool could be a benefit to a large number of faculty at the University and, extending the efforts of the previous student teams, we would like to expand the capabilities of the editor to support widespread use and/or adoption of this tool.
Provided are some current examples of how the chatbot tool is actively in use at NC State:
- Counseling Chatbot, https://cechatbot.ced.ncsu.edu/
- Horse Wellness, https://sites.google.com/ncsu.edu/trot-to-trophy-ii/scenario-chat
- Interview a Document, https://go.distance.ncsu.edu/ed730/
Project Description
DELTA has collaborated with the Senior Design Center in the Spring and Fall of 2024 to develop a functioning prototype of an authoring application for these node-based conversations. The tool gives users direct control over the conversational experiences they are crafting with the ability to visualize, create, and edit the branching dialogue nodes. This authoring tool does not require users to have any programming experience, as the tool converts these nodes directly into a data format which is compatible with chatbot display systems.
Continuing development from Fall 2024, our primary goals for Spring 2025 focus on further improvements to the node editing interface and the user experience; in particular we would like to introduce expanded conversational capabilities and quality of life features in the editing interface, potentially including:
- Enhancements to options for editing, previewing, and exporting chat conversations.
- Improved node organization groups to make it more visually clear which options appear as a single choice.
- "Comment" nodes, not connected to the main dialogue tree, for the purpose of planning and organizing content and keeping track of work-in-progress conversations.
- Support for "Dinner Party" scenarios where a single "chatfile" (JSON data format) could contain several speakers and concurrent bubbles of conversation that an end user could drop into and out of in non-linear fashion.
Technologies and Other Constraints
The previous student teams developed the current editor using SvelteFlow in the frontend and a Node.js REST API backend powered by Express, and using a MySQL/MariaDB database. While we imagine continued development in the same environment would be the most efficient path forward, we are still somewhat flexible on the tools and approaches leveraged.
We envision the editor, and chatbot instances themselves, as web applications that can be accessed and easily shared from desktop and mobile devices. The versions of the chatbot currently in use are purely front-end custom HTML, CSS, and JavaScript web applications, which parse dialogue nodes from a "chatfile" which is just a human readable plaintext file with a custom syntax. We want to preserve the node-based structure and current level of granularity of the chat system, but are flexible regarding the specific implementation and any potential improvements to data formats or overall system architecture.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
We are the NC State Urban Extension Entomology Research & Training Program, and our mission is to promote the health and wellbeing of residents across North Carolina within and immediately surrounding the built environment. Our primary goals are to partner with the pest management community of NC to 1) address key and ongoing issues in the field through innovative research, 2) develop and disseminate relevant and timely publicly available information on household pests, and 3) to design and offer impactful training programs to pest management professionals.
Background and Problem Statement
The pest management industry is often behind the curve in the widespread implementation of technology, which in this modern age greatly limits access to available information. Currently, despite our program frequently developing crucial publications and offering impactful training programs, only a small percentage of our stakeholders utilize these services. This disparity is largely due to the way in which these services are currently presented: hidden within obscure NC State domains or sent via mail as paper bulletins across the State. As a result, countless stakeholders across NC currently miss integral information which could influence pest management programs, directly impacting the health of residents across the State.
Despite the slow uptake of technology within the pest management industry, one piece of technology has become ubiquitous: the smartphone. We have already worked with a team to begin to leverage this technology through the development of several core components of an app (The WolfPest App) that connects our generated materials and courses directly to the pest management industry across the state. We launched the app in January, 2025.
Project Description
Despite the incredible progress made last semester, we have already identified additional application features that, if added, will further flesh out the app and provide critical functionality and access to our stakeholders. This includes the incorporation of a pest-database of all published content housed within the app, where stakeholders can “favorite’ pests to quickly access their information. Further, we want to offer more streamlined specimen submission for identification, as well as a “store” where stakeholders can purchase training materials from a simple online catalog.
Technologies and Other Constraints
As this is well beyond our typical wheelhouse, we would like to work with the students to identify key pieces of technology they feel are most useful for these additional components of the project. We would like to work with the students to build upon the app’s foundation, ensuring that the second app iteration is as equally streamlined and simplified for use by the pest management industry. We recognize the development and updating of applications is an ongoing process, and given this project is centered around NC State resources the IP would likely remain with NC State University. However, we would want students in this project to attend the annual NC Pest Management Conference in January to announce their involvement with the project, and to familiarize themselves with the industry they are serving (if they have the interest in doing so). We are unaware of any other issues, and are happy to discuss changes in our project ideas as feasibility and timeliness dictates.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Ankit is the Founder & CEO of K2S and an NC State Computer Science alum. He envisions a platform which enables other alumni an easy way to give back to the student community by way of mentorship to active Computer Science students. From an industry and a university perspective we’re trying to create a virtual engagement program for the NC State Community.
Background and Problem Statement
Successful alumni often revisit the path that got them there, and it invariably leads them down to the roots of their alma mater. In recognition of their supporters and heroes along that path, they have the urge to become one themselves.
In the Department of Computer Science at NC State, we understand that navigating the program and curriculum can be challenging. Wouldn't it be great to have someone who has been there before support and guide you around the pitfalls, helping you reach your full potential? Much of the skills and knowledge you will experience will take place in classrooms and labs but it also happens in the individual connections made with peers and alumni. CSC's alumni network includes over 10,000 members, many that have been very successful in their careers and who are eager to give back and support current students.
We proposed creating an online mentorship portal that connects current CSC students with CSC alumni to share a goal of promoting academic success and professional advancement for all. A portal which allows alumni to easily provide mentorship and their lessons learned not only is fulfilling to the alumni as a way of giving back, it also provides real help and guidance to students stepping out from the shadows of our lovely campus. Examples include George Mason University's Mason Mentors Program and; UC-Berkley's Computer Science Mentor Program.
Project Description
WolfConnect got its name when it was kickstarted with a team of Senior Design Students in Fall 2023. Today it includes the ability to sign up, set up your profile, education and work history and send a connection request to other users. You can also send private messages to other users.
Primary Portal end-users include: CSC alumni looking to give back to their alma mater by mentoring students and; current CSC UG and GD students looking for help on a specific topic or project. Secondary users could include alumni who are looking for speaking opportunities and; current students searching for contacts for specific internships and Coops.
This semester, we aim to take the WolfConnect portal to the finish line by making it ready for production. This requires some new features and enhancements to existing features, as well as some bug fixes. The main new feature will be adding a “News Feed”. Some of the existing features that can be enhanced include:
- Implementing user retention metrics for administrators
- Improving forum discussions to allow replies in threads and adding tags to posts
- Implementing an algorithm to suggest connections based on user interests and schedule compatibility
There are also some implemented features that are incomplete or not working properly, including:
- Ability to log in with Shibboleth (for NCSU users)
- Saving user’s availability times
- Saving user’s profile picture
Technologies and Other Constraints
The previous team has a detailed handoff of their deliverables, source code and user guides. The idea would be to use that to build on top of that existing model. The system runs on Docker. The backend container is PHP-based and serves a REST API using the Laravel Framework. The frontend container is built with React and MaterialUI. A MySQL database will be used to store all the data. The platform is hosted on an NC State-hosted VM.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
The North Carolina Department of Health and Human Services (DHHS), in collaboration with our partners, protects the health and safety of all North Carolinians and provides essential human services. The DHHS Information Technology (IT) Division provides enterprise information technology leadership and solutions to the department and their partners so that they can leverage technology, resulting ultimately in delivery of consistent, cost effective, reliable, accessible, and secure services. DHHS IT Division works with business divisions to help ensure the availability and integrity of automated information systems to meet their business goals.
Background and Problem Statement
We have an existing legacy application, OpTrack, that utilizes FoxPro and was developed 25 years ago in a production-only environment to meet business operation needs for tracking the inventory of labels used in the Agency printing shop. The print shop receives shipments of various labels used in the correspondence that is sent out by multiple DHHS Divisions. Labels are received into a main warehouse, but inventory can also be maintained in the print shop for immediate use. Staff use a combination of spreadsheets and the OpTrack application to track inventory in the warehouse and the print shop. A separate system is used to order labels.
Project Description
We would like to create a new application to improve the workflow for tracking label inventory in the warehouse and the print shop. Students will be able to meet with the product owner to analyze existing workflows and discuss desired improvements. The application should rely on role-based access control and expand the current application functionality. In the new application, all users must be able to view the current warehouse inventory levels.
Warehouse staff must be able to create new inventory types, record new stock into their inventory, and remove items from their inventory once print jobs are completed. The user interface should be modern and adhere to digital accessibility guidelines.
Potential stretch goals include adding functionality to send label print jobs to designated printers, to record losses, and to integrate support for barcode scanning.
Technologies and Other Constraints
Tools and technologies used are limited to those approved by the NC Department of Health and Human Services Information Technology Department (NC DHHS ITD). Student projects must follow State IT Policies dictated by NC DHHS ITD to allow the app to be deployed by ITD.
In addition, although there is currently some development work previously performed by the Agency using the Microsoft Dynamics Power Platform; students will not be limited to that framework as the basis of a solution. Students are encouraged to think of innovative solutions to manage inventory and design accordingly. If the Power Platform software is used, DHHS will provide licensing for Power Apps, Power Automate (Workflows), Power Pages, and Dataverse components.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Division of Parks and Recreation
The Division of Parks and Recreation (DPR) administers a diverse system of state parks, natural areas, trails, lakes, natural and scenic rivers, and recreation areas. The Division also supports and assists other recreation providers by administering grant programs for park and trail projects, and by offering technical advice for park and trail planning and development. The North Carolina Division of Parks and Recreation exists to inspire all its citizens and visitors through conservation, recreation, and education.
Applications Systems Program
The Applications Systems Program works to support the Division and its sister agencies with web-based applications designed to fulfill the Division’s needs and mission. The current suite of applications addresses: personnel activity, Divisional financial transactions, field staff operations, facilities/equipment/land assets, planning/development, incidents, natural resources, etc. Data from these web applications assist program managers with reporting and analytic needs.
Many previous SDC projects have been sponsored, providing a strong understanding of the process and how to efficiently support the completion of this project while gaining insights into real-world software application development. Our team includes five NCSU CSC alumni, all of whom have completed projects with the SDC. The Apps System Program will be overseeing the project and working directly with you to fulfill your needs and facilitate the development process.
Background and Problem Statement
The Division of Parks and Recreation (DPR) has a passport program that lets visitors track their adventures in state parks and collect stamps at each location. The passport features a page for every state park, along with pages for four state recreation areas, three state natural areas, and nine state trails. Each page includes a photo of a signature landmark, activities available at the site, contact information, and more.
Visitors typically collect stamps at the park's visitor center, though stamps for trails can sometimes be obtained at partner locations like bike shops. This initiative encourages park-goers to explore each park and collect every stamp. While having a physical passport can be fun and engaging for park visitors, it invites problems such as if a visitor loses their passports or a new version is released, their progress will be lost. Our solution to these problems is a digital passport. A digital passport can store a visitor's progress online and let it be easily accessed and updated without the risk of losing physical copies or starting over with each new version.
After discussions with our Public Information Officer and her team, there is significant interest in developing a digital passport application. This transition could provide numerous benefits, including reduced printing costs, timely updates on passport news and versions, and a richer, more informative experience for passport holders about state parks.
Additionally, this project will provide an opportunity for the Applications System Team to become more familiar with new technologies and explore how they can be incorporated into existing applications.
Project Description
The Digital Passport app is an innovative project aimed at enhancing the visitor experience at State Parks by transitioning from a physical paper passport to a digital platform. This app will allow users to track their visits and progress, collect virtual stamps using geolocation technologies, and explore information about each park and natural resources like fauna and flora found at them. This project will be reasonably open-ended in its approach, but there are a couple of features that should be maintained or included.
Key Features
- Offline Accessibility: As a Progressive Web Application (PWA), the app will be accessible offline, allowing users to access their passport information and track their progress without the need for a constant internet connection.
- Geolocation Integration: Users can collect virtual stamps as they visit various State Parks, trails, and Recreation Areas. Geofencing technology will ensure that stamps are only awarded when users are physically present at the designated locations.
- Informational Content: Each digital passport page will feature images of signature landmarks, icons indicating available activities, and details about the number of trails at each park. This will provide a more informative and engaging experience compared to the traditional physical passport.
The Digital Passport App represents a unique opportunity for students to contribute to a meaningful project that encourages exploration and appreciation of NC State Parks while reducing costs associated with traditional printing and materials.
Technologies and Other Constraints
Tools and technologies used are limited to those approved by the NC Department of Information Technology (NC DIT). Student projects must follow state IT policies dictated by NC DIT once deployed by DPR. Additionally, students cannot use technologies under the Affero General Public License (AGPL).
Besides these constraints, we do not have requirements on what technologies students can use. We are encouraging students to experiment and use technologies they find interesting. We would be interested in seeing potential ARCGIS incorporation, but it is not a requirement or need. If students do go down that route, we can provide ARCGIS data relevant to state parks and trails.
Students will be required to sign an NDA related to personal and private information stored in the database and to sign over IP to sponsors when the team is formed. We are willing to work with students on what IP they can use for their future Resume/CV.
Sponsor Background
The Senior Design Center (SDC) of the Computer Science (CSC) Department at NC State oversees CSC492—the Senior Design capstone course of the CSC undergraduate program at NC State. Senior Design is offered every semester with current enrollment exceeding 200 students across several sections. Each section hosts a series of industry-sponsored projects, which are supervised by a faculty Technical Advisor. All sections, and their teams, are also overseen by the Director of the Center.
Background and Problem Statement
Grading team-submitted documents is a critical component of evaluating Senior Design projects. Currently, this grading process relies on spreadsheets where teaching staff manually input grades for rubric items, calculate averages, and aggregate scores. While functional, this system is prone to errors, such as accidentally modifying formulas, and lacks advanced features to simplify grading and feedback. Additionally, managing and distributing these grading spreadsheets across sections and teaching staff adds unnecessary overhead.
The existing process does not easily support flexible rubrics or proper aggregation of scores from multiple graders. Furthermore, there is no streamlined way for administrators to monitor grading progress or ensure consistency across sections. These shortcomings highlight the need for a centralized, robust grading tool tailored to the SDC’s specific needs.
Project Description
For this project, your team will develop a Web application to replace our current spreadsheet-based system. This application will streamline document grading, improve accuracy, and introduce advanced features such as flexible rubrics, multi-grader score aggregation, and role-based access.
System Features
The "SDC Documentation Grader Tool" will include the following features, tailored to specific user roles:
Grading Management
- Rubric Definition and Customization
- Administrators can define grading rubrics with nested categories, optional items, conditional weights, and extra-credit options.
- Rubrics can be assigned to specific documents, allowing flexibility for different assignment types.
- Multi-Grader Support: Administrators can assign multiple graders to the same document. Rubric scores for each item will be averaged across all graders who evaluate a document.
- Real-Time Updates: Grading progress and rubric aggregations are updated automatically to provide live feedback to users.
Role-Based Features
- Administrators
- Assign teaching staff (advisors and TAs) to teams and documents for grading.
- View all grades and grading progress across all teams and sections.
- Designate deadlines for teaching staff to complete grading a specific document.
- Monitor overall grading and compliance with deadlines.
- Teaching Staff (Advisors and TAs)
- Access assigned documents and rubrics.
- Input grades with optional detailed feedback for rubric items.
- View only the grades they have submitted for assigned documents.
- Students
- Access final grades and detailed feedback for graded documents, once released by administrators.
Technologies and Other Constraints
This Web application will run on Docker containers. The backend will expose a REST API and will be developed using Node.js with the Express Framework. The frontend will be built with React. The database will use MySQL/MariaDB. Authentication will be integrated with Shibboleth to leverage existing institutional infrastructure.
Sponsor Background
From critically endangered vultures and gorillas in Africa to rare native plants and amphibians in our state, the North Carolina Zoo has been a leader in wildlife conservation for more than two decades. Our team of experts conducts thorough research to understand the needs of threatened species. We provide data and technology to global communities and organizations to assist them in their efforts to protect wildlife. Zoo staff also work to protect over 2,800 acres of land around our property.
Background and Problem Statement
 The NC Zoo is home to three Grey Mouse Lemurs: Cholula, Cedar, and Speedwell. Mouse Lemurs are among the smallest primates, averaging only 3 inches tall. As a nocturnal species, these lemurs tend to spend their days sleeping and nights actively foraging, exercising, and playing. This nocturnal behavior pattern is at odds with the Zoo’s visitor times, making the educational mission of the Zoo a challenge for keepers. To address this problem, keepers have experimented with a variety of lighting conditions in the lemur enclosure to “flip” daytime and nighttime. However, keepers are responsible for many animals and their enclosures, making tracking the effectiveness of lighting configurations difficult. Keepers would like a way to track and visualize the movement patterns of Cholula, Cedar, and Speedwell to better understand how changes to lighting conditions impact their behavior.
The NC Zoo is home to three Grey Mouse Lemurs: Cholula, Cedar, and Speedwell. Mouse Lemurs are among the smallest primates, averaging only 3 inches tall. As a nocturnal species, these lemurs tend to spend their days sleeping and nights actively foraging, exercising, and playing. This nocturnal behavior pattern is at odds with the Zoo’s visitor times, making the educational mission of the Zoo a challenge for keepers. To address this problem, keepers have experimented with a variety of lighting conditions in the lemur enclosure to “flip” daytime and nighttime. However, keepers are responsible for many animals and their enclosures, making tracking the effectiveness of lighting configurations difficult. Keepers would like a way to track and visualize the movement patterns of Cholula, Cedar, and Speedwell to better understand how changes to lighting conditions impact their behavior.
Project Description
The long term vision for the project is to instrument the lemur enclosure with one or more cameras and a computer-controlled lighting system that will allow keepers to program the lights and objectively measure the time, location, frequency, and duration of movement. This information should be made available via an application that facilitates keepers exploring the history and trends of movement behaviors, possibly filtered by lighting conditions. To facilitate progress in this first semester project, students will receive a library of pre-recorded videos from the Zoo staff. They will use off-the-shelf image processing techniques to identify movement, and display those movements in the application.
The application shall run locally without internet access on a computer furnished by the NC Zoo:
- Enable video (live or pre-recorded) to be analyzed for lemur movement
- Display video (live or pre-recorded)
- Visualize the movement location, time, frequency, and duration of the lemurs
- Enable keepers to enter lighting configuration information, including the characteristics and schedule
- Allow movement analytics to be filtered and summarized based on range or lighting characteristic queries
- Display results of (5) in appropriate graphs and/or visualizations
Technologies and Other Constraints
Students will use existing open source image processing libraries (e.g., Open CV) to analyze videos and open source graphics libraries for visualizing results. If the students elect to design a web-based application, it must still run locally on the computer without internet access.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Dr. Tian is a research scientist who works with children on designing learning environments to support artificial intelligence learning in K-12 classrooms. Dr. Tian’s PhD dissertation study focused on designing AMBY, a development environment for middle school students to build their own conversational agents.
Dr. Tiffany Barnes is a distinguished professor of computer science at NC State University. Dr. Barnes conducts computer science education research and uses AI and data-driven insights to develop tools that assist learners’ skill and knowledge acquisition.
Ally Limke is a PhD student who works closely with Dr. Barnes and Dr. Tian to understand what teachers need to lead programming activities in their classrooms.
Background and Problem Statement
AMBY (“AI Made by You”, Figure 1, see here for a video demo of AMBY) is a web-based application that allows middle school-aged children to create conversational agents (or chatbots) without prior programming experience. In AMBY, children can define the components of the chatbot such as intents, training phrases, responses, and entities. An intent is the underlying goal of a user when they message the chatbot, for example, the intent of a user request “Can you recommend a song?” is “Request for song recommendations”. Training phrases are example phrases the children create for the chatbot to recognize a certain intent. Responses are the list of responses the chatbot will return back to the user if a certain intent gets recognized. Entities are a list of phrases or words that can be extracted from the end-user expressions. AMBY has enabled over 300 middle school students to create chatbots and learn about AI.
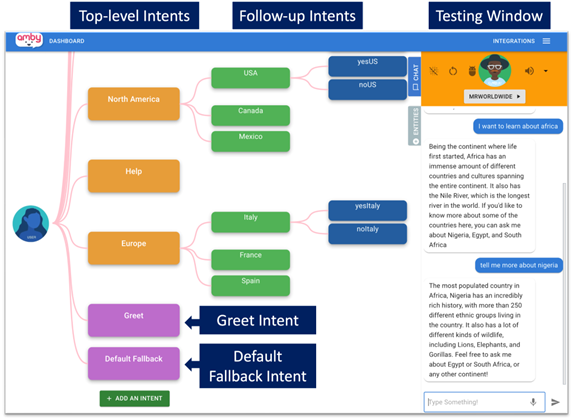
Figure 1. AMBY interface with a chatbot example. Children develop the chatbot on the left panel and test the chatbot on the right.
AMBY is currently built on Google Dialogflow, which is an existing chatbot development environment (mainly targeted for small businesses like ordering pizza). We created AMBY to address the educational needs for children to learn about AI by creating AI artifacts. Compared with Dialogflow, AMBY is more visually attractive to younger aged students, and it visualizes the conversation flow which allows users to design conversations, and it eliminates the advanced features of Dialogflow to make it easy for children with no prior programming experience to create a chatbot of their own interest.
Regarding technical implementation (Figure 2), AMBY uses the React framework front-end and Node.js on the backend. For chatbot training and testing, it communicates with the Google Dialogflow using the Google Dialogflow API.
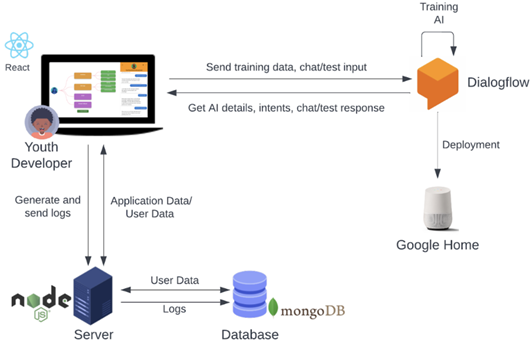
Figure 2: AMBY architecture.
One constraint of the current AMBY architecture is that its backend relies on Dialogflow. We have encountered several challenges using a Dialogflow backend: 1) Initially not designed for children to build chatbots, Dialogflow has age restrictions for user google accounts (limited to 14+ years old users). In the past we had to pay for specialized google accounts for children to use, but this workaround is not scalable for everyone to use; 2) There is limited information we can pull from Dialogflow to help children understand how their chatbot gets trained and debug on their chatbots.
Project Description
We envision creating a new backend for AMBY for an enhanced control of dialogue models and higher explainability of the chatbot training process. The new backend will replace the “Dialogflow” component  in Figure 2.
in Figure 2.
Project Goals:
- Data Extraction:
- Review the current AMBY database and build a pipeline to extract chatbot data (intents, training phrases, responses, entities) in a structured format (e.g., a .json file) for use in dialogue modeling.
- Backend Design and Development:
- Investigate potential LLM-based backend solutions for dialogue modeling. Possible options to start are OpenAI GPT4, LLAMA, and Rasa. Design a new backend architecture for AMBY.
- Implement the identified backend solution to 1) send extracted data from goal 1 to the backend and 2) train dialogue models for the chatbot. 3) handle chatbot testing, which includes receiving user messages, generating chatbot responses based on trained dialogue models, and sending the output back to AMBY for display in the interface.
- Student Feedback Generation:
- Create a script using LLM prompts that analyzes the content of the children-created chatbot and provides constructive feedback for children. The feedback will analyze the quality of their input training data and identify areas for improvement in the chatbot’s design.
Technologies and Other Constraints
- Technologies required for Web-based app
- MongoDB database
- Express.js
- React.js
- Node.js
- LLM requirements
- OpenAI or LlamaIndex or other free/low-cost, open source API for LLM calls
- Python
- Prompt Engineering
Sponsor Background
Hitachi Energy serves customers in the utility, industry and infrastructure sectors with innovative solutions and services across the value chain. Together with customers and partners, we pioneer technologies and enable the digital transformation required to accelerate the energy transition towards a carbon-neutral future.
Background and Problem Statement
Hitachi Energy is currently developing a monitoring product for bushings and tap changers within the TXpert Ecosystem that utilizes multiple inputs, sub-processes those inputs, and sends them further as inputs to algorithms and for consumption by end-users. The product will fundamentally consist of a single board computer (SBC) and an input/output (I/O) board.
The features of the product will be:
- time sync with GPS
- measure temperature and humidity
- measure leakage currents in bushings
- measure vibrations in tap changers
- measure motor currents in tap changers
The outcome of the project will enable the I/O board to work with the targeted SBC.
Project Description
The project requires software drivers that need to be created and tested – enabling functional verification of the platform.
The required drivers for this project are:
- USB Communications with GNSS/GPS Device (NEO-M9N-00B-00)
- I2C Driver for Temperature and Humidity Sensor (SHT30-DIS-B2.5KS)
- I2C Driver for Light Emitting Diode (LED) Driver (LP5569RTWR)
- USB-to-SPI Device (FT4222)
- Digital Input/Output (DIO) Port (read/write)
- SPI Driver Shift Register Interface (74HC165)
- SPI Driver for high-speed ADC (AD7771)
- SPI Driver for RTD (temperature sensor) (ADS124S08)
Technologies and Other Constraints
- The drivers will be utilized on a Linux OS platform.
- Hitachi Energy will provide a development platform to enable validation of the drivers, targeted at the end of January 2025.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Hitachi Energy Transformers Business Unit specializes in manufacturing and servicing a wide range of transformers. These include power transformers, traction transformers, and insulation components. They also offer digital sensors and comprehensive transformer services. Their products are crucial for the efficient transmission and distribution of electrical energy, supporting the integration of renewable energy sources and ensuring grid stability.
The Hitachi Energy’s North American R&D team for Transformers business unit, located at the USA corporate offices in Raleigh NC, is looking to partner with NCSU to enhance the functionality of a software component delivered within some of our product offerings.
Background and Problem Statement
The Web API Link is a Hitachi Energy application that allows the transmission of data between remote end points. For this project, we’re concerned with data transmission between remote monitoring devices and the Hitachi Energy Lumada Asset Performance Management (APM) application. The data transmitted are power transformer condition parameter values, like ambient temperature, oil temperature, or gas content in oil, that are tracked or calculated by the remote monitoring devices.
The remote monitoring devices are Smart Sensors and/or Data Aggregators attached to the power transformers. They are able to transmit data using a TCP/IP network and a variety of protocols likeModbus TCP, IEC-61850 or DNP3.
The Lumada APM application is used to assess the condition of power transformer fleets. It can be accessed as a SaaS or an On-Premise application. The Lumada APM application provides a REST API interface that allows the exchange of data with external applications.
Web API Link application description
The Web API Link allows the transmission of data between remote end points. It implements the following concepts and allows the transmission of data between them:
- Input Devices. An interface that allows the implementation of communication protocols/functionalities to read data from a device implementing a communication protocol such as: Modbus TCP, IEC-61850, etc.
- Output Devices. An interface that allows the implementation of communication protocols/functionalities to output data that has been read from an input device to transmit/communicate data or an outcome. For example, REST-API, email messages, etc.
Figure 1 graphically describes the main components of the application.
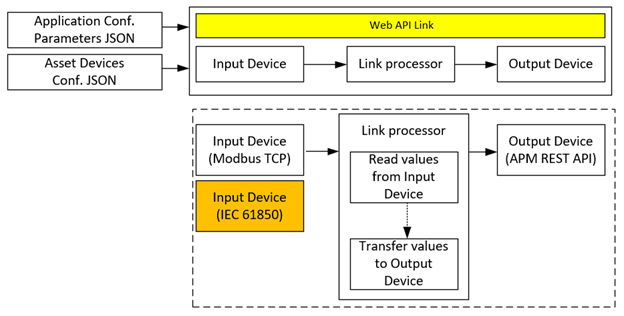
Figure 1
The architecture of the application is structured in such a way that allows the creation of drivers/plug-ins that can be attached to the application to add additional communication protocols/functionalities support dynamically, without having to modify the core code of the application. The configuration of the application and the end points between the Input Devices and Output devices is done via JSON configuration files.
Project Definition
The senior design team’s work will focus on two significant enhancements to the functionality of the Web API Link application. We’re describing these as two phases of the project.
Phase 1 – Web API Link Configuration UI Enhancement.
In the past, configuring the Web API Link has required creating and editing JSON by hand. This work has been simplified by the Web API Link Configurator, an application created by a Fall 2024 senior design team at NC State. This application reduces the tedium of creating the configuration files, but there are some opportunities to extend it to make it even more useful. In particular, the Spring 2025 senior design team will be designing and implementing several enhancements:
- Adding field validations.
- Enhancing the user experience by improving the configuration flows and the availability of preloaded information.
- Adding functionality of the application.
Phase 2
Support for additional protocols would permit the Web API Link application to communicate with additional input devices. Referring to the application diagram in Figure 1, the additional protocols could be supported as Input Device driver/plugins. This would allow extensions to the Web API Link application without significant changes to the design. In the Spring 2025 semester, two supports will be added for two additional protocols:
- DNP3 plug-in component. To allow the Web API Link to communicate and read register values from devices enabled with the DNP3 communication protocol and transmit these values to the Lumada APM application via its REST API interface.
- IEC-61850 plug-in component. To allow the Web API Link to communicate and read register values from devices enabled with the IEC-61850 communication protocol and transmit these values to the Lumada APM application via its REST API interface (to be implemented internally at Hitachi Energy)
Technologies and Other Constraints
The technologies to be used to create the software components are:
- The application must be able to be executed both on Windows and Linux operating systems.
- The output DLL must be able to be executed on x86 processors computers.
- .NET Core 6.0 or above
- C# programming language
- Application configuration files are created using JSON format.
- Visual Studio 2022 or above.
- The application was created on a Windows 10 PC but will be used on a Linux Operating system.
- The necessary libraries to implement the code change, will be provided by Hitachi Energy.
- A test environment will be provided by Hitachi Energy.
The technologies requirements for the Web API Link Configuration UI are:
- ASP.NET Docker container application
- .NET Core 6.0 or above
- Compatible with Ubuntu (20.04). Main target.
- Compatible with Windows (10/11). Desirable.
- The specific technologies could be proposed by the NCSU students working on the project.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
The Laboratory for Analytic Sciences is a research organization in support of the U.S. Government, working to develop new analytic tradecraft, techniques, and technology that help intelligence analysts better perform complex tasks. Processing large volumes of data is a foundational capability in support of many analysis tools and workflows. Any improvements to existing processes and procedures, whether they are measured in time, efficiency, or stability, can have significant and broad reaching impact on the intelligence community’s ability to supply decision-makers and operational stakeholders with accurate and timely information.
Background and Problem Statement
In some cases, the task a model is trained to perform is quite broad, for example the task for a large language model like GPT is to generate human-like text in response to almost any prompt. In other cases the task can be extremely specific, for example the famous Netflix Challenge was to create a model which could predict the rating (1-5 stars) that a user would assign to a given movie. Naturally, all else being equal, more specific tasks are easier to accomplish than general tasks which gives rise to potential accuracy improvements and time/computation cost savings from designing processing systems around task-specific models that do exactly what is desired…and nothing else.
Given some base model that performs a general task, model fine-tuning and distillation are methods that can be used, sometimes in conjunction, to produce models which perform better, and/or more efficiently, on a specific task than the base model. For example if we consider the application of speech-to-text (STT), fine-tuning for specific accents, dialects, or speaking styles from a base model can improve recognition rates, and distilling an STT model from a base model can dramatically reduce the size of a model while taking only a small hit to performance (e.g. Ref #1), or even increasing the performance on the more specific task(s) of interest.
With the above considerations, it is reasonable to consider a system structure in which a family of models, each fine-tuned/distilled to perform accurately and efficiently for some subtask of the more general task of interest, is trained and deployed, rather than a single, general-purpose, model. Incoming data to be processed must then be routed to the appropriate model based on its individual characteristics. Borrowing again from the example of STT algorithms, incoming data might be sampled and examined to determine which accent, dialect, or speaking style it contains, and then routed to a model which was fine-tuned/distilled for that specific accent, dialect, or speaking style. If such a system can be engineered and developed, it is conceivable that both performance and efficiency gains could result.
Note: The method of sampling and examining the incoming data is a key element of such a system. In some applications, this may be trivial, while in others it may require training a machine-learning (ML) routing model which itself must be both accurate and extremely lightweight computationally, else it will erase the potential performance and efficiency gains. It’s quite reasonable to assume that for many applications a classic machine-learning model (logistic regression, support vector machine, random forest, etc) could accomplish this task with sufficient accuracy and speed.
Caption: A basic diagram of the Data Routing System
Project Description
The LAS would like a Senior Design team to develop a prototype system that employs a routing model and a family of fine-tuned/distilled subtask models to process an incoming stream of diverse data. The overarching purpose of the project is to learn how such a system should be designed with performance in mind (incoming data flows are assumed to be very high volume), and to complete a test of performance and efficiency of the system as it compares to a system in which only the base model is used for processing the data flow. Ideally, the system would have monitoring capabilities and a basic dashboard offering insight into the time-varying accuracy and performance metrics to enable system owners to determine when/if the routing and/or subtask models could/should be modified.
The LAS will provide the team with one or more data set(s) with which to use for development and testing, a base model, and potentially a family of subtask models as well. Developing the routing model will be part of the team’s requirements. Depending on the data set(s) and task selected for development and testing, the design and development of this routing model may take a significant ML effort, so at least one team member will ideally have strong interest in the topic.
Technologies and Other Constraints
The team will have great freedom to explore, investigate, and design the ML processing system described above. However, the methodology employed should not have any restrictions (e.g. no enterprise licenses required). In general, we will need this technology to operate on commodity hardware and software environments. Beyond these constraints, technology choices will generally be considered design decisions left to the student team. The LAS will provide the student team with access to AWS resources for development, testing and experimentation. The LAS will also provide the student team with a model deployment system (MDS), which is a Kubernetes-backed service enabling deployment of ML models and associated data inferencing.
ALSO NOTE: Public distributions of research performed in conjunction with USG persons or groups are subject to pre-publication review by the USG. In the case of the LAS, typically this review process is performed with great expediency, is transparent to research partners, and is of little to no consequence to the students.
References
Sponsor Background
Division of Parks and Recreation
The Division of Parks and Recreation (DPR) administers a diverse system of state parks, natural areas, trails, lakes, natural and scenic rivers, and recreation areas. The Division also supports and assists other recreation providers by administering grant programs for park and trail projects, and by offering technical advice for park and trail planning and development. The North Carolina Division of Parks and Recreation exists to inspire all its citizens and visitors through conservation, recreation, and education.
Applications Systems Program
The Applications Systems Program works to support the Division and its sister agencies with web-based applications designed to fulfill the Division’s needs and mission. The current suite of applications addresses: personnel activity, Divisional financial transactions, field staff operations, facilities/equipment/land assets, planning/development, incidents, natural resources, etc. Data from these web applications assist program managers with reporting and analytic needs.
Many previous SDC projects have been sponsored, providing a strong understanding of the process and how to efficiently support the completion of this project while gaining insights into real-world software application development. Our team includes five NCSU CSC alumni, all of whom have completed projects with the SDC. The Apps System Program will be overseeing the project and working directly with you to fulfill your needs and facilitate the development process.
Background and Problem Statement
The Division of Parks and Recreation (DPR) has a passport program that lets visitors track their adventures in state parks and collect stamps at each location. The passport features a page for every state park, along with pages for four state recreation areas, three state natural areas, and nine state trails. Each page includes a photo of a signature landmark, activities available at the site, contact information, and more.
Visitors typically collect stamps at the park's visitor center, though stamps for trails can sometimes be obtained at partner locations like bike shops. This initiative encourages park-goers to explore each park and collect every stamp. While having a physical passport can be fun and engaging for park visitors, it invites problems such as if a visitor loses their passports or a new version is released, their progress will be lost. Our solution to these problems is a digital passport. A digital passport can store a visitor's progress online and let it be easily accessed and updated without the risk of losing physical copies or starting over with each new version.
After discussions with our Public Information Officer and her team, there is significant interest in developing a digital passport application. This transition could provide numerous benefits, including reduced printing costs, timely updates on passport news and versions, and a richer, more informative experience for passport holders about state parks.
Additionally, this project will provide an opportunity for the Applications System Team to become more familiar with new technologies and explore how they can be incorporated into existing applications.
Project Description
The Digital Passport app is an innovative project aimed at enhancing the visitor experience at State Parks by transitioning from a physical paper passport to a digital platform. This app will allow users to track their visits and progress, collect virtual stamps using geolocation technologies, and explore information about each park and natural resources like fauna and flora found at them. This project will be reasonably open-ended in its approach, but there are a couple of features that should be maintained or included.
Key Features
- Offline Accessibility: As a Progressive Web Application (PWA), the app will be accessible offline, allowing users to access their passport information and track their progress without the need for a constant internet connection.
- Geolocation Integration: Users can collect virtual stamps as they visit various State Parks, trails, and Recreation Areas. Geofencing technology will ensure that stamps are only awarded when users are physically present at the designated locations.
- Informational Content: Each digital passport page will feature images of signature landmarks, icons indicating available activities, and details about the number of trails at each park. This will provide a more informative and engaging experience compared to the traditional physical passport.
The Digital Passport App represents a unique opportunity for students to contribute to a meaningful project that encourages exploration and appreciation of NC State Parks while reducing costs associated with traditional printing and materials.
Technologies and Other Constraints
Tools and technologies used are limited to those approved by the NC Department of Information Technology (NC DIT). Student projects must follow state IT policies dictated by NC DIT once deployed by DPR. Additionally, students cannot use technologies under the Affero General Public License (AGPL).
Besides these constraints, we do not have requirements on what technologies students can use. We are encouraging students to experiment and use technologies they find interesting. We would be interested in seeing potential ARCGIS incorporation, but it is not a requirement or need. If students do go down that route, we can provide ARCGIS data relevant to state parks and trails.
Students will be required to sign an NDA related to personal and private information stored in the database and to sign over IP to sponsors when the team is formed. We are willing to work with students on what IP they can use for their future Resume/CV.
Sponsor Background
OpenDI's mission is to empower you to make informed choices in a world that is increasingly volatile, uncertain, complex, and ambiguous. OpenDI.org is an integrated ecosystem that creates standards for Decision Intelligence. We curate a source of truth for how Decision Intelligence software systems interact, thereby allowing small and large participants alike to provide parts of an overall solution. By uniting decision makers, architects, asset managers, simulation managers, administrators, engineers, and researchers around a common framework, connecting technology to actions that lead to outcomes, we are paving the way for diverse contributors to solve local and global challenges, and to lower barriers to entry for all Decision Intelligence stakeholders.
OpenDI’s open source initiative is producing the industry standard architecture for Decision Intelligence tool interoperability, as well as a number of example implementations of OpenDI compliant tools and associated assets.
Background and Problem Statement
Decision Intelligence is a human-first approach to deploying technology for enhancing decision making. Anchoring the approach is the Causal Decision Model (CDM), comprising actions, outcomes, intermediates, and externals as well as causal links among them. CDMs are modular and extensible, can be visualized, and can be simulated to provide computational support for human decision makers. The OpenDI reference architecture provides a specification of CDM representation in JSON as well as defines an API for exchanging CDMs. However, there is no existing tool that allows curation, provenance, and sharing of these extensible CDMs. This project will provide OpenDI’s Model Hub, similar to Docker’s Docker Hub, to allow public browsing, searching, and sharing of CDMs.
Project Description
The best way to think about OpenDI’s Model Hub is by looking at Docker Hub.
Users should be able to:
- Register for accounts
- Take models created using other tools (provided by OpenDI) and push those models to the Model Hub
- Pull models from the Model Hub
- Track the history and provenance of extensions or modification to Models
- Control whether models are publicly available or shared with specific other users
- View and search models they have access to
- As a stretch goal, create a CLI utility to interact with the Model Hub and/or integrate Model Hub interactions with OpenDI’s Authoring Tool example
Technologies and Other Constraints
This project will require the team to contribute directly to the OpenDI open source assets. OpenDI assets are developed publicly on GitHub, and the result (or process) of this project will be hosted there as well. This means team members will be expected to follow OpenDI community contribution standards and to contribute their work under the license OpenDI selects. Team members are encouraged to use their own GitHub accounts to get credit for their contributions.
The final deliverable will run in a linux VM on Oracle Cloud, and be proxied using CloudFlare.
Sponsor Background
This is a joint effort between Okan Pala and NC State Office of Research Commercialization working together to develop a “proof-of-concept” location-based advertisement platform.
Background and Problem Statement
Problem 1: Direct interactivity with digital displays such as vehicle top, in-vehicle, fixed in place, etc. is not available. Static advertisements on digital displays are not (geographically or temporally) targeted, cumbersome, expensive, and not user friendly. There is no easy way for a mom-and-pop store or a local chain manager or an individual with a special message to put advertisements on digital displays, vehicle-top or otherwise. They most likely need to go through an advertising agency, and it won’t be geographically or temporally targeted in most cases.
Problem 2: It is not easy for users to create ads or personal messages in a mobile app. There is no system to aid users in content generation, personalization, customization or adding user input for advertisements or messages deployed on location-specific vehicle-top, in-vehicle or fixed-in-place digital displays (nearby a given location).
Problem 3: The content filtering and flagging is a cumbersome and labor-heavy process. With the aid of an AI system, this could be mostly automated and only ads flagged by AI could be directed for human input.
Problem 4: (Competitive disadvantage) Taxis lost a lot of ground to ride sharing services because of inefficiencies and other costs that only taxis incur. Rideshare services have a competitive edge.
Problem 5: (Fare upsurge) Rideshare services use upsurge pricing when the demand is high. It can get absurdly high during big events.
Project Description
This project is concerned with providing direct interactivity with vehicle-top and other related displays, where businesses and individuals can display an advertisement or personal messages through a mobile application. We’ll simply say “ads” when we’re talking about these types of advertisements and personal messages.
The goal of this project is to create a mobile app that can deliver geo-specific and temporally targeted ads to digital vehicle-top and in-vehicle displays. Users will have control over the ads’ timing (temporal control) and location (geofencing). This should include a bidding system to allow users to outbid others for a message to be shown at a specific time and place.
In the Spring 2024 semester, an NCSU senior design team completed Initial work to create an application that has the backbone of an advertising system. This included a general design for all the components, but the Spring 2024 team prioritized implementation of a single component to be able to finish the work by the end of the semester. This component was the vehicle-top display connected to a mobile application as the advertising platform. Some major additions and improvements are needed, such as ad bidding logic, financial business logic, better geospatial overlay business logic, improvement of the local program running on the display itself. In addition to the improvements to the mobile app and the vehicle-top digital display software, we would like to incorporate the use of AI for content generation for ads, as well as near-real time content control before the ads are approved for display.
The advertising system should have its own API for external advertising institutions to connect to and ride providers to utilize. We would like the API to be designed in such a manner that in the future the system could work with other entities such as Uber, Lyft, taxicab companies.
If the time allows (or the team needs a challenge), we also would like the team to complete the design and the implementation of the rideshare application to work with the advertising system. Below is the description.
Business logic for revenue share and fare down-surge will be based on real-time revenue sharing from digital displays. Ad or messaging revenues from digital displays are shared between the rider and taxi owner to create fare down-surge, based on the user’s preference. Big events are large revenue opportunities since vehicle-top ads will be seen more. This, in turn, potentially pushes fares down even lower while increasing the taxi owner’s share. We would like the API to be designed in such a manner that, in the future, the system could work with other entities, such as Uber and Lyft, to expand past the Taxi industry and individual drivers.
Examples:
Advertising
Joshua Merrit is the General Manager for a restaurant chain in the triangle region (e.g., Cheesecake factory or McDonalds). He is interested in creating an effective ad campaign in order to generate revenue in down times of the restaurant. He determines that the time segment the revenues are the lowest during the weekdays is 10:00 am to 11:30 am and 2:00pm to 4:00 pm. He pulls up the web interface or the mobile application and with the aid of a user-friendly interface uploads the logo, the message to be displayed and an interesting background image. With the help of AI, he gets a recommendation to fuse the background and the logo and create an attractive animation. The system also allows him to generate a digital coupon tied to a QR code to be displayed along with the ad. Mr. Merrit is offering a BOGO deal for anyone that comes in with the coupon between the times defined above. He also designates the locations of interest where he wants the ads to be displayed (the restaurant locations, city center, etc.), geofencing distance as well as the time windows to create a campaign. He gets an option to pay per impression or pay per customer acquired or a combination. Based on these settings, he receives an estimate and sets his ceiling budget for the campaign and enters his payment info to complete the transactions.
Personalized Message
Andrew and Sharon are avid NC State fans. They do their best to attend all the football and basketball games. When they are leaving a game the wolfpack won at the Carter-Finley stadium, they decide to put money together with their friends to place a “Go Pack!” message on all nearby digital displays. They put “Go Pack” as the message in the app and receive a recommendation to insert the NC State logo. They also agree to add a flashy animation to make their point. They accept and set their mobile phone location as the point of interest (or the stadium exit) and agree to pay per impression for the next 15 minutes within a 2-mile radius up to a pre-set amount in total. Then they receive an estimate of the number of impressions they would get within that time span and realize that they need to bid up the UNC fans to get more impressions (e.g., 15 second impressions in a rotating order).
Public Safety
City of Charlotte officials received a warning from the local natural gas distribution company about a possible gas leak in NoDa neighborhood that might cause an explosion. They put out alerts to police, emergency services and traditional media as well as social media. They also think of putting messages on nearby vehicle-top, in-vehicle and fixed displays to warn people about the location and the possible danger. This way, only people who are nearby would be notified and rerouted to a new destination.
Fare Down-Surging (If we implement a ride share component or a rideshare company would connect to our system through our API)
After entering the ride vehicle (or in advance), app users can choose either to reduce the ride cost by choosing fare down-surging or pay full ride cost and display personalized message/info on outside display systems. If fare down-surging is selected, outside display systems will display paid commercial ads and messages pushed by other users ahead of time or during the ride. Part of the income generated with these ads would then be deducted from the full ride price (fare down-surging)”.
The advantage of this app is that the potential for income or (cost deduction for the ride) increases during special events as opposed to price up-surging like Uber/Lyft has implemented previously. For example, some ride services may increase prices before and after football games because of the increased demand. These special events and crowded areas would provide more opportunities for advertisers to reach wider segments. The more the advertisement the more the income is shared between vehicle operator and the rider (income share / price down-surging).
Personalization of Vehicle-top and In-vehicle displays
When a vehicle picks up the call, exterior display systems start displaying personalized messages, logos, etc. immediately so that the app users can recognize the taxi coming to pick them up. This could also be used by corporate customers for their own people.
Riders get a choice between reduced ride cost through down surging or paying the regular price and displaying their own message or ad. For example, corporate customers may choose to display their own corporate logo, message, or ad.
Technologies and Other Constraints
We are flexible about technology. The team should research the best available technology and use that for each component and make the system design accordingly. As for location-specific analysis, we know that ESRI (GIS software system vendor) has the technology for geofencing. They also do have a development platform for app development, but we are not sure if this is the best option for a robust application.
NC State University and Okan Pala own the IP and the team will be asked to sign over the IP rights. If there are any other legal issues, we can check with the NC State Office of Research Commercialization.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Dr. DK Xu and Dr. Kai Lan are collaborating on designing and prototyping an intelligent validation platform for environmental data. Dr. DK Xu is a professor at NCSU CSC specializing in artificial intelligence and large language models, while Dr. Kai Lan is a professor at NCSU College of Natural Resources with expertise in sustainability science and environmental engineering. Their mission is to advance sustainability and environmental data management through innovative AI technologies, making large-scale data validation more accurate and efficient. The EcoValid project aligns with the goals by leveraging cutting-edge AI and multi-modal data retrieval to enhance the reliability and accessibility of environmental datasets.
Background and Problem Statement
Environmental data, including satellite imagery, field sensor readings, and scientific reports, is the backbone of climate modeling, ecological research, and resource management. It informs critical decisions, from assessing the impact of deforestation to optimizing water usage in agriculture. However, the sheer volume and diversity of this data create significant challenges. Current validation methods often rely on manual processes that are not only slow and labor-intensive but also prone to inconsistencies and errors. These limitations hinder the ability to scale validation efforts, making it difficult to ensure data reliability for large-scale applications like global climate models or real-time resource tracking.
Recent breakthroughs in artificial intelligence, particularly in retrieval-augmented generation (RAG) and large language models (LLMs), offer a transformative opportunity to address these challenges. These technologies excel at retrieving and synthesizing relevant information from vast datasets, enabling accurate and context-aware analysis. By integrating RAG and LLM capabilities with structured environmental databases, it is possible to automate and streamline the validation process. This project aims to develop a scalable, AI-powered solution focused on environmental data validation. Recognizing the scope of a senior design project, the emphasis will be on creating a foundational framework — a multi-modal intelligent agent that can retrieve, validate, and report on environmental data with a clear focus on feasibility and impact.
Project Description
EcoValid aims to leverage cutting-edge AI technologies to create a multi-modal platform for validating environmental data efficiently and effectively. The project will deliver three levels of functionality, with the third being optional:
Basic Data Validation: Enable users to query environmental data, such as greenhouse gas emissions or carbon footprints, and receive clear, reliable validation results. The platform will cross-reference user-submitted data with trusted sources like environmental databases and reports, providing concise feedback on data accuracy.
Advanced Insights and Reporting: Allow users to submit complex queries, such as validating multi-step life cycle assessments or identifying discrepancies in environmental data. The system will analyze these inputs, retrieve relevant information using RAG from curated databases, and generate detailed, context-aware validation reports, ensuring users can make informed decisions.
Interactive Visualization (Optional): Provide graphical representations of validation outcomes within the platform. For example, the tool can visually map discrepancies between datasets, display trends in carbon emissions, or generate a flow diagram of validated life cycle stages. These visualizations will enhance user understanding of the data and its implications.
Technologies and Other Constraints
We anticipate that the best platform for this work would be a web-based application tailored for environmental data validation, leveraging RAG and LLM capabilities. The key features and components will include:
- Front-End UI Design:
- Develop an intuitive and user-friendly interface for querying and data validation.
- Provide tailored interaction modes for different user roles (e.g., researchers, and policy analysts).
- LLM-Powered Back-End:
- Integrate LLM capabilities to process and respond to user queries efficiently.
- Leverage RAG to connect to external environmental databases and retrieve relevant information.
- Analyze user-submitted data (e.g., carbon footprints, life cycle assessments) against trusted sources.
- Database Design:
- Develop a robust database to store user queries, validation results, and additional environmental datasets.
- Ensure secure and efficient storage and retrieval of data, including mechanisms to export results (e.g., validation reports) in formats like CSV.
- Implement mechanisms for seamless integration with external data sources, such as Ecoinvent or OpenLCA.
The Spring 2025 senior design team will prototype an application with the following deliverables:
Front-End Development:
- Design and implement a user-friendly interface for environmental data queries and validation.
- Enable users to log in, create profiles, and specify roles (e.g., researcher, policymaker) for personalized interaction.
- Allow users to upload datasets for validation, including structured and semi-structured data.
Back-End Functionality:
- Implement LLM-powered functionalities to handle:
- Query processing and retrieval of relevant environmental data.
- Validation of user-submitted data against curated databases using RAG.
- Generation of validation summaries and detailed reports.
- Ensure secure communication between the front-end and back-end systems.
Database Design:
- Develop a scalable database for storing validation results, user data, and external database references.
- Implement robust security protocols to protect sensitive data.
- Create export options for validation results, enabling users to share insights with stakeholders.
Additional Features (if feasible):
- Integrate basic visualization tools to present validation outcomes graphically (e.g., trend charts, and data discrepancy maps).
- Explore voice interaction capabilities to enhance accessibility.
- Design wireframes and interaction flows to connect users with similar environmental data interests or projects.
We will develop a list of further deliverables for the fall very soon.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
The Christmas Tree Genetic Program (CTG) at NC State’s Whitehill Lab is working on genomic tools to develop elite Fraser fir trees. Graduate students are working on elucidating mechanisms involved in the tree abilities to handle disease pressure, pest problems and challenges brought about by climate change. Understanding these mechanisms allow the researchers to develop Christmas trees that are more resilient to biotic and abiotic stressors.
Background, Problem Statement, and Previous Work
Scientists in the CTG program handle a large number of plant material such as unique individual trees, cones, seeds, embryos, cultures and clones. Currently, all the data is managed using Microsoft Excel, which will quickly become obsolete in the face of a growing amount of plant material information needing to be stored. Plant material tracking is key for data integrity. We need to know what is what, where and when at any point in time. A database will help manage our inventory and prevent data loss and mismanagement. Such a database is referred to as a Laboratory Inventory Management System, or LIMS.
ROOTS is a repository of data related to CTG’s research activities both in the fields and in the laboratory.
The various steps of the protocols used by the research group are represented in the database. Individual plant materials of various stages are saved in the database (trees, cones, seeds, embryos…) along with metadata (origin, transfer date, quantity, location…)
The first round of development, completed by the Sen Design team in Spring 2023, resulted in a strong emphasis on lineage tracking and nomenclature. The ROOTS DB ensures that the seeds from a tree are connected to the parents and the progeny (“children”). The naming nomenclature contains specific information related to the tree breeding work done by the CTG. The system has three types of users: user, superuser and admin. The user has viewing privileges only. The superuser can add, modify, and discard data in the system, and generate reports of material data based on species, genealogy, and other criteria. The admin has additional permission to add new users, superusers, and admins to the system.
At the end of the Fall 2023 semester, the Christmas Tree Genetics program had two main outstanding requirements:
- Installing ROOTS database on the CTG server via Docker
- Successfully running through the entire process of Initiation of embryos from seeds, maintenance of embryos, maturation of embryos, germination of embryos and acclimatization of young trees.
The second round of development for ROOTS 2.0 completed during the Fall 2023 semester resulted in the following:
ROOTS utilizes Shibboleth Login that requires NCSU unity id and dual factor authentication. Furthermore, the individual components of our ROOTS 2.0 system such as the frontend, backend, database, and notification service are built and run in Docker containers. The functionality for uploading and managing files and photos, as well as the implementation of exporting material data and tracking lifecycle data is complete and fully functional. The ROOTS 2.0 application is currently deployed and running on the CTG local server.
Project Description
This is the third round of development for the ROOTS database.
The Spring 2025 team will focus on:
- Offline functionality (work offline, update DB when back online)
- Offline mode scheduling (calculate date intervals to alert of next transfer to fresh medium is needed).
- Reporting (generate reports containing requested data)
- Other features upon exploration
Technologies and Other Constraints
ROOTS is a web application using the following stack
Frontend: React with the Material UI and NPM QR Reader packages.
Backend: NodeJS with an Express.JS framework and Sequelize for the Object-Relational Mapper
Database: MySQL
Authentication: Shibboleth
Containerized using Docker
Sponsor Background
NC State DELTA, an organization within the Office of the Provost, seeks to foster the integration and support of digital learning in NC State’s academic programs. We are committed to providing innovative and impactful digital learning experiences for our community of instructors and learners, leveraging emerging technologies to craft effective new ways to engage and explore.
Background and Problem Statement
This project is a continuation of previous Senior Design Projects from Spring and Fall 2024, continuing the development of an editor for creating branching dialogue chatbots. While there is a lot of focus on using AI to power various instances of a "chatbot" system, there is still a tendency for AI-driven chat systems to go "off the rails" and provide unexpected results, which are often disruptive, if not exactly contrary, to the intentions behind a chatbot dialogue simulation where accuracy matters. We have developed a "chatbot" prototype that simulates having conversations in various contexts (conducting an interview, talking to experts, leading a counseling session, etc.) using a node-based, and completely human-authored branching dialogue format. While this guarantees that conversations remain on-script, it also means that a human needs to author the content, and this responsibility currently falls to internal developers on the DELTA team, instead of instructors who have more expertise with the content. We feel like this tool could be a benefit to a large number of faculty at the University and, extending the efforts of the previous student teams, we would like to expand the capabilities of the editor to support widespread use and/or adoption of this tool.
Provided are some current examples of how the chatbot tool is actively in use at NC State:
- Counseling Chatbot, https://cechatbot.ced.ncsu.edu/
- Horse Wellness, https://sites.google.com/ncsu.edu/trot-to-trophy-ii/scenario-chat
- Interview a Document, https://go.distance.ncsu.edu/ed730/
Project Description
DELTA has collaborated with the Senior Design Center in the Spring and Fall of 2024 to develop a functioning prototype of an authoring application for these node-based conversations. The tool gives users direct control over the conversational experiences they are crafting with the ability to visualize, create, and edit the branching dialogue nodes. This authoring tool does not require users to have any programming experience, as the tool converts these nodes directly into a data format which is compatible with chatbot display systems.
Continuing development from Fall 2024, our primary goals for Spring 2025 focus on further improvements to the node editing interface and the user experience; in particular we would like to introduce expanded conversational capabilities and quality of life features in the editing interface, potentially including:
- Enhancements to options for editing, previewing, and exporting chat conversations.
- Improved node organization groups to make it more visually clear which options appear as a single choice.
- "Comment" nodes, not connected to the main dialogue tree, for the purpose of planning and organizing content and keeping track of work-in-progress conversations.
- Support for "Dinner Party" scenarios where a single "chatfile" (JSON data format) could contain several speakers and concurrent bubbles of conversation that an end user could drop into and out of in non-linear fashion.
Technologies and Other Constraints
The previous student teams developed the current editor using SvelteFlow in the frontend and a Node.js REST API backend powered by Express, and using a MySQL/MariaDB database. While we imagine continued development in the same environment would be the most efficient path forward, we are still somewhat flexible on the tools and approaches leveraged.
We envision the editor, and chatbot instances themselves, as web applications that can be accessed and easily shared from desktop and mobile devices. The versions of the chatbot currently in use are purely front-end custom HTML, CSS, and JavaScript web applications, which parse dialogue nodes from a "chatfile" which is just a human readable plaintext file with a custom syntax. We want to preserve the node-based structure and current level of granularity of the chat system, but are flexible regarding the specific implementation and any potential improvements to data formats or overall system architecture.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Dr. Tiffany Barnes and Dr. Veronica Cateté lead computer science education research in the department of computer science at NC State University. Dr. Barnes uses AI and data-driven insights to develop tools that assist learners’ skill and knowledge acquisition. Dr. Cateté works closely with K-12 teachers and students conducting field studies of technology use and computing in the classroom.
Dr. Tian is a research scientist who works with K-12 students on designing conversation-based learning environments to support artificial intelligence learning in K-12 classrooms.
Ally Limke is a PhD student who has been working closely with Dr. Barnes and Dr. Cateté to understand what teachers need to lead programming activities in their classrooms.
Background and Problem Statement
To support the new influx of teachers and educators from various backgrounds to teach block-based programming lessons, we developed a wrapper for the Snap! language called SnapClass. This system supports assignment creation and student submission as well as project grading. The tool was developed using various programming paradigms and after initial deployment and usability test, we have new feedback to work with to address user needs and tool functionality.
SnapClass v7.0 will build on the work done by eight prior Senior Design teams beginning in Spring 2022. The prior teams have added useful functionality to SnapClass such as the integration of multiple block-based programming environments into the system, a FAQ for students working in Snap, mechanisms for auto-saving code, differentiated assignment to students based on skill level, non-coding assignments, logging of student actions in the environment, etc.
Project Description
Teachers often face the challenge of limited time to provide individualized support to each student during class. To help bridge this gap, we want to integrate a cutting-edge, LLM-based (Large Language Model) chatbot into SnapClass, our programming learning management system designed for K-12 students learning the Snap! language. By incorporating this AI-powered chatbot, students will gain an additional resource to ask programming questions and receive instant, informative feedback, complementing teacher support.
This project involves adapting an existing Retrieval-Augmented Generation (RAG) system provided by Game2Learn lab to understand and respond effectively within the context of the Snap! language. Ensuring that the chatbot offers relevant, context-aware assistance will empower students to continue learning outside direct teacher guidance. Additionally, we plan to create a teacher dashboard that displays student-chatbot interactions, helping educators identify common areas of difficulty, and monitor appropriate use of the tool in the classroom.
Initial Requirements:
- Train the existing RAG system to specialize in the Snap! Programming language, i.e. enable it to make sense of /explain and generate Snap programs.
- Integrate the RAG system into the Snap! and Cellular coding interface(s) and ensure it is easily accessible to students alongside their code. Cellular is a version of Snap! which has been extended for scientific simulations with Cellular and is embedded into the SnapClass platform.
- Create a dashboard within SnapClass in which teachers can review students’ conversations with the chatbots.
- Provide insights and analytics on how the chatbots are being used. Metrics may include but not limit to: number of students used the chatbot, number of messages sent, type of questions, topic of questions
Snapclass, like other software projects, has had a long lifespan, with new features and updates being added over time. Regular bug fixes, updates, and optimizations are necessary to keep the software running smoothly. In order for the SnapClass system to reach a new level of users, the codebase needs to scale accordingly. This means new features, modules and components should be easy to add without compromising the stability or performance of the system. With a well-structured and maintainable code base, we can more easily adapt to changing user requirements and integrate more third-party libraries or frameworks such as LMS support.
Technologies and Other Constraints
- Technologies required for Web-first SnapClass development
- JavaScript
- HTML
- SQL/phpMyAdmin
- Current Technologies in use for SnapClass wrapper (Flexible for maintenance/growth)
- Node.JS
- Mocha (Unit Testing)
- Angular
- MySQL
Sponsor Background
Dr. Tiffany Barnes and Dr. Veronica Cateté lead computer science education research in the Department of Computer Science at NC State University. Dr. Barnes uses AI and data-driven insights to develop tools that assist learners’ skill and knowledge acquisition. Dr. Cateté works closely with K-12 teachers and students conducting field studies of technology use and computing in the classroom.
Dr. Tian is a research scientist who works with K-12 students on designing conversation-based learning environments to support artificial intelligence learning in K-12 classrooms.
Ally Limke is a PhD student who has been working closely with Dr. Barnes and Dr. Cateté to understand what teachers need to lead programming activities in their classrooms.
Background and Problem Statement
To support the new influx of teachers and educators from various backgrounds to teach block-based programming lessons, we developed a wrapper for the Snap! language called Snapclass. This system supports assignment creation and student submission as well as project grading. The tool was developed using various programming paradigms and after initial deployment and usability testing, we have new feedback to work with to address user needs and tool functionality.
SnapClass v7.0 will build on the work done by eight prior Senior Design teams beginning in Spring 2022. The prior teams have added useful functionality to SnapClass such as the integration of multiple block-based programming environments into the system, a FAQ for students working in Snap, mechanisms for auto-saving code, differentiated assignments to students based on skill level, non-coding assignments, logging of student actions in the environment etc.
Project Description
Many K-12 educators face significant challenges when teaching programming. Time constraints limit their ability to provide timely, detailed feedback, and those without specialized computer science training often struggle to accurately assess coding assignments. This project focuses on building and integrating a Large Language Model (LLM) based auto-grader within SnapClass, our programming learning management system. The goal is to empower teachers with an efficient, AI-powered solution that automatically evaluates student code based on customizable rubrics. By developing an LLM-based auto-grader, we aim to reduce the workload for teachers and bridge the knowledge gap, allowing for more consistent and insightful feedback for students. This enhancement will not only streamline the grading process but also improve the quality of feedback students receive, fostering better learning outcomes.
Key Project Goals:
- Generate custom rubrics: Embed an LLM to generate custom rubrics for Snap! Projects. Teachers should be able to edit / customize the rubric.
- Customizable Rubric Evaluation: Design the auto-grader to interpret and apply the grading rubrics, aligning with their specific teaching goals and expectations.
- Seamless Integration: Embed an LLM-based autograder directly into SnapClass's existing teacher grading pages, providing a user-friendly experience (similar to GradeScope functionality) for teachers and maintaining the platform's intuitive design.
- Feedback Enhancement: Develop capabilities that enable the auto-grader to generate initial drafts of constructive, rubric-aligned feedback to students, that teachers can then edit, approve, and disable/enable for students, The feedback should be written in a way that helps students understand their specific mistakes and make suggestions about areas for improvement.
Snapclass, like other software projects, has had a long lifespan, with new features and updates being added over time. Regular bug fixes, updates, and optimizations are necessary to keep the software running smoothly. In order for the Snapclass system to reach a new level of users, the codebase needs to scale accordingly. This means new features, modules and components should be easy to add without compromising the stability or performance of the system. With a well-structured and maintainable code base, we can more easily adapt to changing user requirements and integrate more third-party libraries or frameworks such as LMS support.
Technologies and Other Constraints
- Technologies required for LLM generation
- OpenAI or LlamaIndex or other free/low-cost, open source API for LLM calls
- Technologies required for Web-first Snapclass development
- JavaScript
- HTML
- SQL/phpMyAdmin
- Current Technologies in use for Snapclass wrapper (Flexible for maintenance/growth)
- Node.JS
- Mocha (Unit Testing)
- Angular
- MySQL
Sponsor Background
Our company is an innovative, global healthcare leader committed to saving and improving lives around the world. We aspire to be the best healthcare company in the world and are dedicated to providing leading innovations and solutions for tomorrow.
Merck’s Security Analytics Team is a small team of Designers, Engineers and Data Scientists that develop innovative products and solutions for the IT Risk Management & Security organization and the broader business. Our team’s mission is to be at the forefront of cybersecurity analytics and engineering to deliver cutting-edge solutions that advance the detection and prevention of evolving cyber threats and reduce overall risk to the business.
Background and Problem Statement
Cyber-attacks are becoming more prevalent every day, all over the world. Everyone is at risk of becoming a victim of a cyber-attack - government entities, individuals, and public/private sectors. All attacks are due to some vulnerability in a system and pose a high risk for cybercriminals to exploit. Vulnerabilities can vary and exist in unpatched software, weak passwords, unsecured APIs, etc.
Currently, organizations face challenges in efficiently prioritizing vulnerabilities and managing patches. The manual processes involved are time-consuming, prone to human error, and often result in delayed remediation of critical vulnerabilities. This exposes our systems to potential breaches and compromises our overall security posture.
By leveraging generative AI, organizations can streamline their vulnerability prioritization processes and automate patch management, ensuring a more agile and responsive approach to cybersecurity. Organizations can focus on the most critical threats, improving their security posture and reducing breach risks. Automating patch management enhances operational efficiency by freeing IT and security teams to work on strategic initiatives. Timely patching ensures compliance with regulations, avoiding fines, and saves costs by reducing manual processes.
The goal of this project is to assess how Generative AI can impact the future of cybersecurity. Consider how GenAI can enhance efficiency and accuracy, but also how it might face challenges such as trust and bias.
Project Description
GenAI can be leveraged in vulnerability prioritization and automated patching. Your objective is to
- Develop Vulnerability Prioritization: Use GenAI advanced tools and methodologies to accurately assess and prioritize vulnerabilities based on their potential impact and exploitability.
- Automate Patch Management: Deploy automated solutions to streamline the patching process, ensuring timely and consistent application of security patches across all systems. (Examples: If it’s a misconfiguration, such as a flag that needs to be set, automate the process to fix the setting. If a patch is needed if you are running an outdated binary with a vulnerability, it should be patched to prevent data leaks by upgrading or applying the necessary patch.)
Implementation Plan
- Assessment and Planning: Conduct a thorough assessment of your vulnerability management and patching processes. Identify gaps and areas for improvement.
- Tool Selection: Evaluate and select GenAI based advanced patching tools
- Pilot Testbed to test the selected tools and processes.
- Monitoring and Continuous Improvement: Establish metrics to monitor the effectiveness of the new solutions and continuously improve our processes. This could be done via either a dashboard or a summary of recommendations
At the completion of this project, students will have also built a user-friendly dashboard for the vulnerability management framework that integrates generative AI algorithms to enhance the efficiency and effectiveness of security teams by providing a comprehensive overview of identified vulnerabilities with visualizations such as graphs, which categorize vulnerabilities by severity and track trends over time. Key functionalities include AI-driven prioritization recommendations, actionable insights for remediation steps, patch management status tracking, and seamless integration with existing security tools. The dashboard empowers security teams to make informed decisions, improves collaboration among departments, and supports continuous improvement in security practices by focusing efforts on the most critical threats, ultimately streamlining the vulnerability management process and enhancing the organization’s overall security posture.
Technologies and Other Constraints
Tips, steps, and tools:
- Kubernetes environments to run against
- Choose applicable Open-source Gen AI security scanning tool (kubescape, botkube, GeniA etc)
- Dummy Vulnerabilities / misconfiguration setting
- Develop a dashboard /report to show the outcome of scheduled patching and results.
The final solution proposed in this project involves the integration of generative AI algorithms into a comprehensive vulnerability management framework that automates the prioritization of security vulnerabilities and streamlines the patching process. By harnessing the power of machine learning and natural language processing, the solution offers real-time analysis of threat data, enabling organizations to assess the severity and exploitability of identified vulnerabilities more accurately. This AI-driven approach not only enhances the efficiency of vulnerability assessment but also minimizes the manual labor involved in patch management by automating deployment and configuration tasks. Additionally, the solution includes a user-friendly dashboard that provides security teams with actionable insights and prioritization recommendations, allowing them to focus their efforts on the most critical threats. Ultimately, this innovative framework aims to significantly reduce the time to remediation, improve the overall security posture of organizations, and empower IT teams to respond proactively to emerging threats.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Dr. Lavoine is an Assistant Professor in renewable nanomaterials science and engineering. Her research exploits the performance of renewable resources (e.g., wood, plants) in the design and development of sustainable alternatives to petroleum-derived products (e.g., food packaging). As part of her educational program, Dr. Lavoine aims to help faculty integrate sustainability into their curriculum to raise students’ awareness of current challenges on sustainable development and equip them with the tools to become our next leaders in sustainability.
Background and Problem Statement
In June 2024, Dr. Lavoine and three of her colleagues offered a faculty development workshop on sustainability that introduced a new educational framework to guide faculty in the design of in-class activities on sustainability.
This platform integrates three known frameworks: (1) the pillars of sustainability (environment, equity, economy), (2) the Cs of entrepreneurial mindset (curiosity, connection, creating value) and (3) the phases of design thinking (empathy, define, ideate, prototype, implement, assess). For ease of visualization and use, this platform was represented as three interactive spinnable circles (one circle per framework) that faculty can spin and align with each other to brainstorm ideas at the intersection of phases from the different frameworks.
Because this platform only served as a visual tool with no functionality, a group of CSC students took up the challenge in Fall 2024 to build an entire website and database, based on this initial framework, for faculty to design and seek inspiration for in-class activities on sustainability. The CSC students did a great job at designing and programming the front end and the back end of the platform. They have suggested great graphics ideas and have built the entire foundation for users to 1- create an account, 2- upload in-class activities and 3- search for in-class activities.
This website is not quite complete yet. Hence, the purpose of this project is to keep building and designing this website to have a final prototype by June 2025. Indeed, Lavoine and her co-workers will offer this faculty development workshop in June 2025 again. How great would it be for the faculty participants to have this website functioning and ready to use?
Once finalized, Dr. Lavoine intends to share this website with the entire teaching community – and to use it primarily during faculty development workshops on sustainability. Demands from instructors and students on sustainability are exponentially increasing. Now, more than ever, it is important to put in place the best practices in teaching and learning sustainability. It is not an easy task, and research in that field has already shown some tensions between frameworks, systems, etc. The goal of this website is not to tell faculty and instructors what sustainability is about (because there is no single definition), but rather to guide them towards creatively and critically design active learning, engaging activities that raise students’ awareness on the value tensions around sustainability and help them make decisions!
Project Description
As mentioned above, the design of the website and its functionality has been initiated in Fall 2024. It will be important to build on the work that has already been done to make this Spring 2025 project a success.
Looking at the “amazing work” the 2024 CSC team has done, Dr. Lavoine has some ideas to take this website to the next level:
- Replace the previous graphic with a new, visually appealing design showing connections between the three frameworks and enabling user interaction.
- Implement upgrades and untested features from the 2024 website version.
- Add a text box for users to input a summary/brief description of activities during the upload process.
- Represent activities as tiles with an image and title.
- Integrate AI-based image generation based on activity titles and descriptions.
- Conduct usability testing with students and faculty, using feedback forms for improvements.
- Make the platform mobile-friendly and evaluate required changes for usability.
- Develop a student training interface on sustainability using submitted activities.
- Explore tools for faculty to create tests, quizzes, or assignments from uploaded activities.
More ideas are welcome! This website will evolve and get better with your input and your expertise.
Technologies and Other Constraints
Frontend: ReactJS v18.3.1, Backend: Django 4.2.16, Database: MySQL 8.4.2, Containerized with Docker
This platform should be, first, accessible through a desktop/laptop and a tablet (hence, a touch-screen option would be nice), but in the future, why not think about a mobile application or a web platform accessible through mobile.
When it comes to hosting this platform, Dr. Lavoine would consider using first the virtual machine options available at NC State (https://oit.ncsu.edu/about/units/campus-it/virtual-hosting/pricing-and-billing/). If this platform reaches demands and needs beyond expectations, cloud services (such as AWS) could be used.
Sponsor Background
ShareFile is a leading provider of secure file sharing, storage, and collaboration solutions for businesses of all sizes. Founded in 2005 and acquired by Citrix Systems in 2011, ShareFile has grown to become a trusted name in the realm of enterprise data management. The platform is designed to streamline workflows, enhance productivity, and ensure the security of sensitive information, catering to a diverse range of industries including finance, healthcare, legal, and manufacturing.
Background and Problem Statement
In client collaboration scenarios, a service provider is someone who provides a service to their client. Examples of typical service providers include lawyers and accountants. Their clients include everyday people. In a typical client collaboration scenario, the service provider frequently needs to acquire information from the client.
For example, an accountant will send a questionnaire to their client, asking for demographic and financial information in order to begin working on a client’s annual income tax returns. Historically, this process was done using paper forms. Today, it is increasingly being accomplished with the use of online, web-based forms.
It is common for the service provider to have an inventory of forms they use for different scenarios. Building online forms usually involves the use of a WYSIWYG form builder tool. Although the form builder helps the service provider to create these forms, it is still a requirement that the service provider provide all of the intelligence in authoring these forms. They must provide all the questions, validations and logic related to the form’s behavior.
The WYSIWYG paradigm helped to reduce the time and effort involved in form building. We want to further reduce the time and effort involved by applying AI technology. By leveraging AI, a form builder could kickstart a service provider’s efforts by providing an initial form based on the service provider’s prompts.
Project Description
Project Overview
The goal of this project is to create an AI-powered form builder that enables users to generate forms dynamically. Examples of forms include survey forms, signup forms, and data request forms for various services. The system will include a backend with a dynamic schema, CRUD APIs to manage forms and data, and a pipeline to analyze collected data in a product like Snowflake.
There are two distinct user personas:
- Form creators: These users would use the LLM prompt to create a form. They can modify the form, and see any submissions to the form.
- Form users: These users submit answers to the form questions.
Requirements
1. Form Creation
- AI-Generated Forms: Utilize AI models to assist users in generating form templates based on specified inputs or objectives.
- Prompt-Based Generation: Allow users to answer prompts or provide descriptions of their form's purpose (e.g., "Create a survey to measure customer satisfaction"). The AI should generate a complete form based on the user's input, similar to platforms like WIX.
- Form Types:
- Surveys
- Signup forms (stretch)
- Data request forms (stretch)
- JSON Schema: Forms should be represented as a JSON Schema that can be rendered by the frontend for user input
- Customizable Fields / Drag-and-Drop Builder (Stretch): Users should be able to modify AI-generated forms by adding, editing, or removing fields.
- Preview Mode (Stretch): Enable users to preview the form before saving or deploying.
- Theming (Stretch): Provide options for customizing the form's appearance (e.g., colors, fonts, and layout).
2. User Interface (Frontend)
- Form Renderer: Forms are rendered using the JSON Schema served, at a unique public URL.
- Form Submissions: Submissions are stored in the database, where form creators can view.
3. Backend
- Flexible Schema:
- Implement a flexible schema to accommodate varying field types and structures.
- Ensure scalability for a high volume of forms and submissions.
- CRUD APIs:
- Create: API to save new forms.
- Read: API to retrieve forms and their submissions.
- Update: API to modify existing forms.
- Delete: API to remove forms or submissions.
- Data Validation: Validate submitted data against the form's schema.
4. Integration with AI Services
- AI Model Integration:
- Use an external or custom-trained AI model for generating form templates.
- Include support for natural language input to describe the form's purpose.
5. Data Management
- Storage:
- Store form metadata, schema and submissions in a database.
- Use optimized data structures for querying and scalability.
- Data Export (Stretch):
- Enable export of submission data to external analysis tools like Snowflake.
- Provide data in a structured format compatible with Snowflake (e.g., CSV, JSON).
6. Analytics and Insights (Stretch)
- Dashboards:
- Show basic analytics for each form (e.g., submission count, completion rate).
- Visualize user responses with charts or graphs.
- Stretch Goal - Snowflake Integration:
- Develop a pipeline to push submission data to Snowflake in near real-time or through scheduled batches.
- Ensure data integrity and security during the transfer.
Use Cases
1. Survey Form for Customer Feedback
- A business user wants to gather customer feedback on a new product. They interact with the AI by providing prompts like "Create a survey to measure customer satisfaction." The AI generates a survey with questions such as "How satisfied are you with our product?" and "What can we improve?" The user customizes the form with additional fields and themes before deploying it.
2. Signup Form for an Event (Stretch)
- An event organizer needs a signup form for a conference. By providing a prompt like "Create a signup form for a tech conference," the AI generates fields such as "Name," "Email Address," "Company," and "Job Title." The organizer uses the drag-and-drop builder to add a "Dietary Preferences" field and preview the final form before publishing.
3. Data Request Form for a Service (Stretch)
- A service provider wants a form to collect client data for onboarding. They prompt the AI with "Create a data request form for onboarding clients." The AI generates a form with fields like "Client Name," "Contact Information," and "Service Requirements." The provider customizes the form and integrates it into their website.
Deliverables
- Fully functional AI-powered form builder application.
- API documentation for CRUD operations and data export.
- User guide for creating, managing, and analyzing forms.
- Stretch Goal: Integration setup with Snowflake for data analysis
Technologies and Other Constraints
We envision a web application that takes natural language input to generate a JSON Schema. This schema is stored in a database and can be rendered as a form. Form submissions are also stored in a database, visible to the form creator. As an example of a JSON schema-based form renderer, see https://jsonforms.io/
Backend
Required:
- Cloud Provider: AWS
Flexible:
- Programming Language: Node.js, Python, or Java.
- Database: PostgreSQL, or MongoDB for form and submission data.
- API Framework: Express.js (Node.js) or Flask (Python).
Frontend
Required:
- Framework: React.js
- Prompt Interface: Integrate a conversational UI for AI-driven form generation.
AI Integration
Flexible:
- Models: OpenAI API, any open-source model, or custom-trained NLP models.
- Frameworks: TensorFlow, PyTorch, or Hugging Face for custom solutions.
Data Analytics (Stretch Goal)
Flexible:
- Data Pipeline: AWS Glue, Apache Airflow, or custom ETL scripts.
Required:
- Analytics Tool: Snowflake.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Dr. Stallmann is a professor (NCSU-CSC) whose primary research interests include graph algorithms, graph drawing, and algorithm animation. His main contribution to graph algorithm animation has been to make the development of compelling animations accessible to students and researchers. See mfms.wordpress.ncsu.edu for more information about Dr. Stallmann.
Background and Problem Statement
Background.
Galant (Graph algorithm animation tool) is a general-purpose tool for writing animations of graph algorithms. More than 50 algorithms have been implemented using Galant, both for classroom use and for research.
The primary advantage of Galant is the ease of developing new animations using a language that resembles algorithm pseudocode and includes simple function calls to create animation effects.
Problem statement.
There are currently two versions of Galant: (a) a sophisticated, complex Java version that requires git, Apache ant, and runtime access to a Java compiler; (b) a web-based version, galant-js, accessible at https://galant.csc.ncsu.edu/ or via the github repository galant-js (https://github.com/mfms-ncsu/galant-js). The latter was developed by a Spring 2023 Senior Design Team and enhanced by teams in Fall 2023, Spring 2024, and Fall 2024. It has been used in the classroom (Discrete Math) and several algorithms have been successfully implemented. However, there are some major (and minor) inconveniences from a usability perspective.
Project Description
Some enhancements are required to put the useability of galant-js on par with the original Java version. The Java version has been used extensively in the classroom and in Dr. Stallmann’s research. The JavaScript version already has clear advantages, particularly when it comes to the rendering of graphs.
All teams working on the project are expected to produce transparent code and detailed developer documentation. It is essential that the sponsor, Dr. Stallmann, be able to continue development on his own or with the help of other students and future teams. To that end, he expects to be directly involved in the development, actively participating in coding and documentation.
One major challenge, related to the use of Cytoscape to render graphs, is to establish a mapping between physical positions of nodes on the screen and logical positions of nodes in a text file that describes a graph. For most graphs this is simply a matter of keeping track of a scale factor and doing the appropriate transformations during editing (and when an algorithm moves nodes). There are, however, special graphs whose nodes are points on an integer grid. The mapping must be maintained both during editing and algorithm execution. To complicate matters further, some of the algorithms require movement of nodes.
To address this challenge directly, the team will create a standalone graph editor that reads text in the format supported by galant-js, allows a user to move nodes on the Cytoscape display, and then exports the new positions to text, preserving the scale. If the integer node coordinates in the original text are smaller than those of the Cytoscape rendering, node coordinates must be mapped to the nearest integer in the text. This may require a mechanism for handling nodes mapped to the same location.
Once the node mapping functionality has been successfully implemented it can be integrated into the galant-js code base in collaboration with the team working directly on galant-js.
Technologies and Other Constraints
Students are required to learn and use JavaScript effectively. The current JavaScript implementation uses React and Cytoscape for user interaction and graph drawing, respectively. An understanding of Cytoscape is required to address the challenge related to node positions on the screen.
Sponsor Background
Blue Cross and Blue Shield of North Carolina (Blue Cross NC) is the largest health insurer in the state. We have more than 5,000 employees and about five million members. This includes about one million served on behalf of other Blue Plans. Our campuses are in Durham and Winston-Salem. Blue Cross NC has been committed to making healthcare better, simpler and more affordable since 1933. And we've been driving better health in North Carolina for generations, working to tackle our communities’ greatest health challenges
Background and Problem Statement
Blue Cross NC’s public website (bluecrossnc.com) serves as a critical touchpoint for our customers and providers seeking information about health insurance plans, benefits, and services. Our customers may have trouble in finding relevant information on our public website if they enter from a keyword search (google, bing, etc) and have to scan the page for the information relevant to their query. They may also have difficulty navigating the site’s menu and overall architecture due to it being complex and difficult to quickly parse which leads to frustration and abandonment.
Our public website aims to effectively communicate to prospective members seeking a new policy or current member finding information pertinent to their health needs. Our information architecture is crafted to aid in discovery, ease of use and simplicity. Our mission is to educate and inform to the best of our ability, which leads us to the need to re-evaluate the effectiveness of our overall content strategy.
This project will be essential in discovering content gaps that pose a reputational risk to Blue Cross Blue Shield of NC. The outcome from this project’s discovery and reporting will influence future content strategy, and aid in an enhanced user experience.
Project Description
This project aims to identify the gaps in the information architecture and ease of use navigating BlueCrossNC.com. By leveraging AI, we will evaluate the website’s effectiveness in educating and informing users based on their queries, or browsing session, as well as provide a user session specific widget on the public website to enhance the customer’s journey.
Objective #1
The team will be provided access to a benchmark LLM powered agent that is trained on only the public content available through bluecrossnc.com. This agent should respond to specific queries (e.g. “ongoing palliative care” or “post injury therapy”) with helpful information as well as a summary (links) as to where that information resides on the website.
Using the top 5 search queries (provided by the analytics team), the agent’s response be informative and provide source references. Based on the number of sources, as well as their presence in the site’s hierarchy, the team will rate the site’s overall effectiveness in communicating to the organic user who does not have AI assistance. Factors to consider include content structure, navigation depth, and relevance to the site’s navigation. This score will indicate the balance between providing relevant information to customers in an intuitive way, and the ease by which a user can navigate to that content. Determining content relevance is not subjective, but should be driven by the query (keyword matching, synonyms, audience relevance). For example, `Medicare` based searches should reference content labelled `over 65`.
The team will deliver a system capable of ingesting a series of search strings and process them according to the above parameters. The result should be a dashboard detailing the analysis report for each query string.
Objective #2
Using the agent, the team will build an embeddable widget that can be installed on the public site to aid in content discovery. This widget ‘s presence on the website should be opt in (explicit consent given by the site user), and all interactions and session data should be ephemeral and bound to a temporary session. Once enabled by the consenting customer, the widget should analyze URL history for the session and provide links to relevant content.
The team will deliver a dynamic client-side widget that interacts with the agent via an established API. This widget is non-interactive and should be dismissible.
Objective #3 – stretch goal
Using the top 5 search queries, and the top 5 abandoned session paths (given to us by analytics), the tool will be used to summarize content regarding each query, and based on these summaries’ effectiveness we can determine whether there is content gap. For instance, if a query only returns links to other portals and systems, then that would be a failed test indicating that our public content doesn’t suffice in that scenario. If a query returns a helpful and thorough answer as well as relevant links if applicable, then that would indicate a successful test. Key parameters that determine a successful test would be thorough responses, minimal sources for aforementioned responses, as well as location in content structure for the referenced sources.
The team will deliver a system dashboard that analyzes agent responses with the above parameters, detailing the results per agent response.
Technologies and Other Constraints
Agent Stack:
The team will be provided access to an agent trained on bluecrossnc.com, hosted through Copilot Studio.
Sandbox site:
The team will be provided with a snapshot instance of bluecrossnc.com that they can modify without restraint. This instance will be reserved for NCSU use exclusively. This will allow NCSU to make any code changes necessary.
Widget Constraints:
The embeddable widget should be self-contained and installed by including a script tag. All transactions to the agent should be client side. The interface itself should be REACT powered. The only session artifacts used should be the `history` and an opt-in cookie consenting to the widget’s use. Once enabled, the `history` object should be populated with each navigated URL. When window.unload is called, all history is to be cleared, as well as the cookie consent removed.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
FreeFlow Networks is a startup pursuing innovative technologies for potential commercialization. Our current working idea is the use of crypto technologies to create a 100% transparent and democratic platform for the promotion of ideas.
Background and Problem Statement
We have seen the rise of social media affect public discourse in profound ways. In the USA, the effect on elections, product marketing, and cultural zeitgeist (ex: fads, celebrity) has been remarkable. Social media platforms and their inherent advertising dynamics have evolved rapidly over the last 20 years. Today’s landscape of X, TikTok and Instagram could not be more different than the 2012 Facebook arena. But the fundamental elements have not changed. Influencers (independent content creators) gain attention through viral content, amplified by mass user views & likes, while commercial advertisers pay to attach their messages to the reach of influencers.
One could argue that in the latest evolutions of Instagram and X, the difference between advertisers and influencers has become almost indistinguishable. Populism is more diverse than ever before. Algorithms on TikTok and Instagram sort users into highly customized echo chambers of their desires and beliefs. With those finely tuned user attributes teased out, marketing of goods and services to target demographics is more efficient than ever before, creating a boom in the launch of national and global small businesses. For every fad diet pushed by a physically attractive influencer, there is also a beloved product developed for an audience that could never have found product market fit in a world before social media.
While these trends in social media have produced amazing opportunities for upstart capitalist activity, their effects on political discourse have been less, shall we say… celebrated. Political marketing (lobbying and campaigning) is treated no differently by social media from any other form of marketing. Special interest groups and candidates can now target audiences with customized messages designed to garner the audience’s support more efficiently than ever before. But have audiences (constituents and voters) gained an equivalent increase in influence?
Could there be value in the creation of a transparent “idea economy” that any citizen / constituent could contribute to? One where discussion, shaping and promotion of ideas is done transparently (in the open with verified identity) and limited by economics (with actual money at stake). Could such an economy create transparent citizen lobbies that could become their own special interests? And could such an economy then finance “traditional” (aka social) media content and advertising?
How would this work? Who would choose to participate? Would it be any more or less “fair” than traditional lobbying methods? Could it be more “fun”? Does the advent of crypto currency technologies enable such an idea economy? Shall we find out?
Project Description
The working hypothesis of this project is as follows:
- Meme Coins (eg: DOGE coin) have proven to be a popular segment of the cryptocurrency landscape. Their prices tend to be very low and highly volatile, with price moves seemingly correlated with public sentiment.
- Cryptocurrency Exchanges have been forced to implement Know Your Customer (KYC) controls in most countries, establishing a link between human identity and the exchange of crypto currency for fiat currency.
- We could create an Idea Economy that functions as a combination Crypto Exchange (the Idea Exchange) and Web3 Application (the Idea Application).
- The Idea Exchange would accept Meme Coin deposits into a user’s account, and then further enable the one-way exchange of Meme Coin for Idea Tokens (utility tokens).
- The Idea Exchange would implement KYC controls to verify the identity of participants and limit user onboarding to valid constituencies (ex: USA residents).
- Idea Tokens would thus have full chain of custody through verified user identities.
- The Idea Exchange might, for example, accept DOGE Coin and exchange it for DOLO Tokens (short for DOGE Lobby). It might only do this for USA residents. It might use other meme coin and utility token combinations for different jurisdictions, with each jurisdiction having a unique utility token.
- The Idea Application functions much like a “go fund me” or “kickstarter” type environment with “discord” type features.
- Users must spend Idea Tokens to post an idea and create a discussion forum around it, as well as stake Idea Tokens to it.
- This puts a sponsor citizen in the driver’s seat of the idea, with real funds on the line.
- Tokens spent to post the idea are forfeited to fund operation of the Application.
- Users can support an idea by staking further Idea Tokens to the idea.
- Staked tokens are locked to the idea’s economy for a period of time.
- Staked tokens are returned to the idea sponsor only if they shut down the idea.
- Staked tokens are returned to supporters if the idea is shut down by the sponsor, or their stake period elapses.
- Staked tokens can be spent in a manner proposed by the idea creator at any time, by vote of the idea supporters.
- Participation in the discussion of the idea might be open to all, or require a minimal stake of Idea Tokens.
- Users must spend Idea Tokens to post an idea and create a discussion forum around it, as well as stake Idea Tokens to it.
- When an idea’s supporters vote to spend their collective staked tokens, the Idea Exchange and Application collaborate to facilitate the transaction.
- Staked Idea Tokens are exchanged for Meme Coins.
- Meme Coins are exchanged for Fiat Currency.
- Fiat Currency is reliably funneled into the financed activity.
- To ensure funds are only used as expected, the types of activities that can be financed could be limited.
- Ex: Funding of a specific Instagram Advertising Campaign could be a very reliable supported activity, with the Idea Exchange transferring USD funds directly to a specific Instagram campaign.
- Ex: Giving DOGE coin directly back to an Idea Sponsor to spend in a way they promise would be a very risky activity, but it might be the will of the idea’s supporters, and it would at least be returning money to a verified individual who could later be prosecuted for fraud by supporters if they did not use the funds as voted on and instructed by the supporters.
There is no doubt this is an ambitious project, and unlikely one that students can tackle in a single semester. Students are encouraged to define an initial scope for this semester’s project, and provide a recommended scope for the next semester’s team.
Students are encouraged to riff on this idea with the project sponsor, modifying and enhancing it with their unique perspective as users of social media and constituents of national, local and student government.
Technologies and Other Constraints
Use of crypto currency and blockchain technology is believed by the project sponsor to be required for the trustworthy operation of the final platform.
A working prototype might not fully implement such technology if it allows a working increment of progress that can be tested with end users.
Final project code should be published under BSD license and made freely available on github.com.
Sponsor Background
Dr. Rizwan Manji is a cardiac surgeon and critical care medicine (ICU) doctor as well as an Associate Professor in the Departments of Surgery and Anesthesia at the University of Manitoba. Dr. Manji has an interest in decreasing medical error/improving patient safety as well as decreasing health professional burnout and improving wellness. Dr. Manji is interested in using computer science/ AI to help achieve some of these goals.
Dr. Celine Latulipe is a human-computer interaction researcher in the Department of Computer Science at the University of Manitoba in Canada where they co-direct the Human Computer Interaction lab. Dr. Latulipe conducts research on education in Computer Science and creativity support.
Dr. Tiffany Barnes leads computer science AI and education research in the Department of Computer Science at NC State University. Dr. Barnes uses AI and data-driven insights to develop tools that assist learners’ skills and knowledge acquisition.
Dr. DK Xu is an Assistant Professor in the CS Department at NC State University and leads the NCSU Generative Intelligent Computing Lab. His research is fundamentally grounded in advancing Artificial General Intelligence, particularly the automated planning, reliable reasoning, and efficient computing of generative AI systems.
Background and Problem Statement
Medical training is intensive and stressful – medical trainees have very limited time to learn huge amounts of information and understand how to apply medical knowledge in patient care. Diagnostic reasoning is a high-risk task, as misdiagnosing could cause health issues to worsen, or even lead to death. This is why it is crucial to provide medical trainees with effective resources that allow them to practice and improve their diagnostic reasoning skills in a low-risk environment.
Serious games can generate high levels of student engagement and motivation leading to effective learning. Using serious games for diagnostic reasoning has a variety of potential benefits: they can provide low-risk environments, provide students with autonomy on when to practice, and allow students to practice collaboration across medical specialties. Our research to date has shown that a mobile app that has quick-play daily options (like the NYT Wordle) is preferred by medical trainees as it requires no specialized equipment and would fit into their busy schedules. However, they also want the option for longer-form play with more involved cases.
Project Description
We have an initial prototype of a mobile game that allows medical trainees to practice diagnostic reasoning at three levels:
- quick daily games that take < 5 minutes
- short games that are slightly more involved and may take ~15 minutes to play.
- (a different project team will work on designing the UX for a third level of longer form, complex cases).
For this team, the goal is to develop technology to populate the game with accurate and relevant cases across a variety of medical specialties, with a variety of presenting symptoms.
Data from focus groups held with medical trainees provide the following requirements:
- Each case should have feedback and links to more information: feedback would be about why the specific details of the case lead to a specific diagnosis, and links for more information should be to trusted and up-to-date medical references about the diagnosis (or how that symptom manifests for that diagnosis)
- Games should track user progress with a point system and users should be able to ‘level up’ as they earn points
- For daily quick-play games, users should get two chances, with fewer points awarded if they get the answer right on the first attempt
- Hints should be available when a user is stuck or makes a wrong diagnosis, but penalties should be applied for asking for hints too early, especially as the user levels up
- Points should be given for asking for collaboration help from colleagues in other specialties for longer form complex cases
- Leaderboards and other competitive aspects should be opt-in, as not all trainees want their progress to be public
- A user should be able to see their own avatar at all times and dress up the avatar with reward features
Games should be categorized by both specialty and initial main symptom, with these categories allowing a trainee to select what area of specialty or symptom they want to practice.
The team working on this project will be guided by the following goals:
- Choose and integrate LLM tools that will allow a database of diagnostic cases to be built up.
- Develop the back end of the game by developing methods to scrape medical cases from the Internet, and use LLMs to elaborate diagnostic decision trees in order to assign and subtract game points based on the path trainees take through the decision trees.
Technologies and Other Constraints
- Technologies likely required for the back-end development (more details to come here)
- MySQL, JavaScript, possibly Angular or Node.js, or React
- Possibly unity3D for mobile, or other game dev platform suitable for somewhat text-oriented game.
- Current Technologies in use for the prototype:
- Swift
Sponsor Background
Dr. Rizwan Manji is a cardiac surgeon and critical care medicine (ICU) doctor as well as an Associate Professor in the Departments of Surgery and Anesthesia at the University of Manitoba. Dr. Manji has an interest in decreasing medical error/improving patient safety as well as decreasing health professional burnout and improving wellness. Dr. Manji is interested in using computer science/ AI to help achieve some of these goals.
Dr. Celine Latulipe is a human-computer interaction researcher in the Department of Computer Science at the University of Manitoba in Canada where they co-direct the Human Computer Interaction lab. Dr. Latulipe conducts research on education in Computer Science and creativity support.
Dr. Tiffany Barnes leads computer science AI and education research in the Department of Computer Science at NC State University. Dr. Barnes uses AI and data-driven insights to develop tools that assist learners’ skills and knowledge acquisition.
Dr. DK Xu is an Assistant Professor in the CS Department at NC State University and leads the NCSU Generative Intelligent Computing Lab. His research is fundamentally grounded in advancing Artificial General Intelligence, particularly the automated planning, reliable reasoning, and efficient computing of generative AI systems.
Background and Problem Statement
Medical training is intensive and stressful – medical trainees have very limited time to learn huge amounts of information and understand how to apply medical knowledge in patient care. Diagnostic reasoning is a high-risk task, as misdiagnosing could cause health issues to worsen, or even lead to death. This is why it is crucial to provide medical trainees with effective resources that allow them to practice and improve their diagnostic reasoning skills in a low-risk environment.
Serious games can generate high levels of student engagement and motivation leading to effective learning. Using serious games for diagnostic reasoning has a variety of potential benefits: they can provide low-risk environments, provide students with autonomy on when to practice, and allow students to practice collaboration across medical specialties. Our research to date has shown that a mobile app that has quick-play daily options (like the NYT Wordle) is preferred by medical trainees as it requires no specialized equipment and would fit into their busy schedules. However, they also want the option for longer-form play with more involved cases.
Project Description
We have a prototype of a mobile game that allows medical trainees to practice diagnostic reasoning at two levels:
- quick daily games that take < 5 minutes
- short games that are slightly more involved and may take ~15 minutes to play.
What we want to add is a third level of longer form games that span several days of intermittent play with data relating to the case being released slowly over time in response to player decisions. This is a more complex form of game play, but also more closely mimics real world, complex medical cases.
Data from focus groups held with medical trainees provided the following requirements:
- Each case (at all levels) should have feedback and links to more information: feedback would be about why the specific details of the case lead to a specific diagnosis, and links for more information should be to trusted and up-to-date medical references about the diagnosis (or how that symptom manifests for that diagnosis)
- Games should track user progress with a point system and users should be able to ‘level up’ as they earn points
- Hints should be available when a user is stuck or makes a wrong diagnosis, but penalties should be applied for asking for hints too early, especially as the user levels up
- Points should be given for asking for collaboration help from colleagues in other specialties for longer form complex cases
- Leaderboards and other competitive aspects should be opt-in, as not all trainees want their progress to be public
- A user should be able to see their own avatar at all times and dress up the avatar with reward features
Games (other than the daily cases) should be categorized by both specialty and initial main symptom, with these categories allowing a trainee to select what area of specialty or symptom they want to practice.
The team working on this project will be guided by the following goals:
- Transform initial findings from our research and our initial prototype (built in Swift) into a more robust prototype, with a backend server to store player and game data.
- Design interaction, including the buildup presentation of symptoms, time delays, and hints to encompass the case complexity, working with Dr. Manji for appropriate case data using 2-3 sample cases.
- Expand the prototype and develop backend support to enable collaboration from players with varied specialties for longer-form games.
Technologies and Other Constraints
- Technologies likely required for the back-end development (more details to come here)
- MySQL, JavaScript, possibly Angular or Node.js, or React
- Possibly unity3D for mobile, or other game dev platform suitable for somewhat text-oriented game.
- Current Technologies in use for the prototype:
- Swift
Sponsor Background
Dr. Rizwan Manji is a cardiac surgeon and critical care medicine (ICU) doctor as well as an Associate Professor in the Departments of Surgery and Anesthesia at the University of Manitoba. Dr. Manji has an interest in decreasing medical error/improving patient safety as well as decreasing health professional burnout and improving wellness. Dr. Manji is interested in using computer science/ AI to help achieve some of these goals.
Dr. Celine Latulipe is a human-computer interaction researcher in the Department of Computer Science at the University of Manitoba in Canada where they co-direct the Human Computer Interaction lab. Dr. Latulipe conducts research on education in Computer Science and creativity support.
Dr. Tiffany Barnes leads computer science AI and education research in the Department of Computer Science at NC State University. Dr. Barnes uses AI and data-driven insights to develop tools that assist learners’ skills and knowledge acquisition.
Dr. DK Xu is an Assistant Professor in the CS Department at NC State University and leads the NCSU Generative Intelligent Computing Lab. His research is fundamentally grounded in advancing Artificial General Intelligence, particularly the automated planning, reliable reasoning, and efficient computing of generative AI systems.
Background and Problem Statement
Medical training is intensive and stressful – medical trainees have very limited time to learn huge amounts of information and understand how to apply medical knowledge in patient care. Diagnostic reasoning is a high-risk task, as misdiagnosing could cause health issues to worsen, or even lead to death. This is why it is crucial to provide medical trainees with effective resources that allow them to practice and improve their diagnostic reasoning skills in a low-risk environment.
Serious games can generate high levels of student engagement and motivation leading to effective learning. Using serious games for diagnostic reasoning has a variety of potential benefits: they can provide low-risk environments, provide students with autonomy on when to practice, and allow students to practice collaboration across medical specialties. Our research to date has shown that a mobile app that has quick-play daily options (like the NYT Wordle) is preferred by medical trainees as it requires no specialized equipment and would fit into their busy schedules. However, they also want the option for longer-form play with more involved cases.
Project Description
We have developed a prototype of a mobile game that allows medical trainees to practice diagnostic reasoning at three levels:
- quick daily games that take < 5 minutes
- short games that are slightly more involved and may take ~15 minutes to play.
- (a different project team will work on designing the UX for a third level of longer form, complex cases).
Data from focus groups held with medical trainees provide the following requirements:
- Each case should have feedback and links to more information: feedback would be about why the specific details of the case lead to a specific diagnosis, and links for more information should be to trusted and up-to-date medical references about the diagnosis (or how that symptom manifests for that diagnosis)
- Games should track user progress with a point system and users should be able to ‘level up’ as they earn points
- For daily quick-play games, users should get two chances, with fewer points awarded if they get the answer right on the first attempt
- Hints should be available when a user is stuck or makes a wrong diagnosis, but penalties should be applied for asking for hints too early, especially as the user levels up
- Points should be given for asking for collaboration help from colleagues in other specialties for longer form complex cases
- Leaderboards and other competitive aspects should be opt-in, as not all trainees want their progress to be public
- A user should be able to see their own avatar at all times and dress up the avatar with reward features
Games should be categorized by both specialty and initial main symptom, with these categories allowing a trainee to select what area of specialty or symptom they want to practice.
The team working on this project will be guided by the following goals:
- Ensure Diagnostic Trustworthiness: Develop and implement mechanisms to ensure the reliability and accuracy of diagnostic cases, using medical expert reviews and AI-based validation techniques to confirm that all game scenarios reflect up-to-date, evidence-based medical practices.
- Transparent Decision-Making: Integrate features that transparently explain the diagnostic reasoning process for each case, highlighting the critical factors that led to specific diagnoses. Provide clear justifications for both correct and incorrect choices to build users' trust in the game’s feedback.
- Feedback Consistency and Reliability: Design a consistent and reliable feedback system that delivers medically accurate explanations and links to trusted references. Ensure the game maintains high standards for reliability across various medical specialties and case complexities.
Technologies and Other Constraints
- Technologies required for the back-end development (more details to come here)
- Current Technologies in use for the prototype:
- Swift
Sponsor Background
The Laboratory for Analytic Sciences is a research organization in support of the U.S. Government, working to develop new analytic tradecraft, techniques, and technology that help intelligence analysts better perform complex tasks. Processing large volumes of data is a foundational capability in support of many analysis tools and workflows. Any improvements to existing processes and procedures, whether they are measured in time, efficiency, or stability, can have significant and broad reaching impact on the intelligence community’s ability to supply decision-makers and operational stakeholders with accurate and timely information.
Background and Problem Statement
Artificial Intelligence (AI) has revolutionized many application domains. As AI continues to evolve, the complexity and diversity of tasks it tackles have grown exponentially. This underscores the importance of benchmarking AI systems to help test and communicate their performance, reliability, and efficiency across the wide array of tasks they are expected to perform. An effective benchmarking framework provides developers, researchers, and stakeholders with insights into model strengths and weaknesses, fostering innovation and transparency. Establishing a comprehensive leaderboard to evaluate AI models across diverse tasks and metrics addresses the need for standardization and facilitates informed decision-making in selecting and deploying AI solutions.
Project Description
The LAS would like a Senior Design team to develop a prototype AI leaderboard system, a user interface (UI) with a backend database, to communicate how an AI model performs against a corpus of benchmarks. Drawing inspiration from the Huggingface Leaderboard, this project involves designing and implementing a robust user interface (UI) that will show to users the different models available, the benchmarks that exist (with descriptions of what they test against), and the results of the benchmark. The user will have the ability to search, sort, and filter across the models and tests that are part of the leaderboard. In addition, each benchmark will have a link to a details page to show more information about the benchmark. Each benchmark consists of a dataset, an evaluation measure (and potentially another model) and a resulting score. This details page will include this information as well as links to where to get copies of this information as well as links to code that shows how to run the benchmark.
The leaderboard itself, as the central element, is designed to offer not just rankings but also nuanced insights into model performance. It aims to incorporate visual representations of variability in test results and evaluations on the compute costs and energy usage of the model. By highlighting the trade-offs between performance and cost, the leaderboard provides a holistic view, enabling stakeholders to make balanced decisions when choosing AI models for specific applications.
An API will also be designed that will allow a user to submit a new model or benchmark to the leaderboard or benchmark. There will also be an administrator role who will verify and approve each submitted model or benchmark before inclusion to the leaderboard.
Note: a stretch goal will be to include integration into a model deployment service that will allow one to not just submit a model or benchmark, but to automatically run a newly submitted model or benchmark against the current set of benchmarks or models to update the leaderboard with the new results.
Regarding the architecture of the solution, the team is asked to explore, investigate, and design the system in consultation with LAS sponsors. To bound the problem, we may assume that all associated databases are SQL-based, and that visualizations that may be produced from common python-based software libraries are sufficient to meet the users’ needs.
Technologies and Other Constraints
Regarding technology choices, the team will again have great freedom to explore, investigate, and design the prototype. However, the methodology employed should not have any restrictions (e.g. no license required). In general, we will need this technology to operate on commodity hardware and software environments. Beyond these constraints, technology choices will generally be considered design decisions left to the student team, in consultation with LAS sponsors. Existing solutions in this space may already exist (or be developed during the term) in the commercial or open-source environment. The LAS does not see this as a negative. The problem presented above is complex enough that many potential manners of approach are possible, and it is likely that even approaches that appear to work well will yet admit improvements. The student team will be free (within legal confines of course) to learn from what
others in the technology world are doing, and adapt the solution developed in this project accordingly to best achieve results, even if it includes building off of existing open-source code-bases rather than building from scratch. LAS will provide the team with access to AWS resources (EC2, S3, etc) for development, testing and experimentation.
ALSO NOTE: Public distributions of research performed in conjunction with USG persons or groups are subject to pre-publication review by the USG. In the case of the LAS, typically this review process is performed with great expediency, is transparent to research partners, and is of little to no consequence to the students.
Sponsor Background
The North Carolina Department of Health and Human Services manages the delivery of health and human related services for all North Carolinians, especially our most vulnerable people – children, elderly, disabled and low-income families. The Department works closely with health care professionals, community leaders, advocacy groups, local, state and federal entities and many other stakeholders to make this happen.
Background and Problem Statement
As part of the Centers For Medicaid/Medicare Services (CMS) guidelines overseen by the Data System Group (DSG), the current Medicaid Management Information System (MMIS) is being redesigned into a modular Medicaid Enterprise System (MES). As part of this modularization, the Medicaid Integration Services (MIS) platform serves to facilitate data exchange integrations across the various modules and with Medicaid Trading Partner systems. Both scheduled batch and real time data exchange integrations will be routed through MIS using Managed File Transfer (MFT) protocol and Application Programming Interface (API) Management solutions to coordinate the various information exchanges across all integrations and systems This introduces a level of complexity into managing the timeliness, frequency, and accuracy of the exchanges which are critical to the overall operations of the MES. The impact of these transfers not occurring can lead to denial of services and potential patient harm if not managed adequately.
Project Description
The Medicaid Integration Services (MIS) framework has the following capabilities:
- Using GoAnywhere MFT software, the MFT capability provides the ability to securely transfer files, disperse a single file to multiple partners, and will allow dashboards to monitor integrations.
- Using Boomi API Management the API capability provides the ability to host and monitor API invocations. This will allow the modules and partners to connect to a central tool to send and receive API calls vs. point to point.
- MES Landing Page provides single sign on (SSO) for the various MES modules using North Carolina Identity Management (NCID)
MES comprises of modules and vendors. Lots of data files must be exchanged between modules to modules, modules to vendors, vendors to modules. All file exchange must be tracked and managed efficiently and some of the files will have time constraints.
As part of the MIS capabilities implementation, there is a need to develop a web application to:
- produce a Master Integration (data files) repository function which maintains Integration and Interfaces with smart search capabilities
- display file exchange logs with smart search capabilities
- provide automatic notifications to partners for missing files
- create dashboards to track and monitor all the interfaces and integrations to support the Operations teams.
Technologies and Other Constraints
Here are the preferred technologies for use:
Web applications could be developed using Next JS https://nextjs.org/ along with any compatible User Interface (UI) components such as Bootstrap https://www.bootstrap-ui.com/ Chakra https://www.chakra-ui.com/ for accessibility features, Mantine https://ui.mantine.dev/ for look and feel, and Semantic UI React https://react.semantic-ui.com/ for responsive UI.
REST API for backend
PostgresSQL https://www.postgresql.org/ for database
Security Assertion Markup Language (SAML) based Single Sign On (SSO) authentication
Container-based software deployment.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
SAS provides technology that is used around the world to transform data into intelligence. A key component of SAS technology is providing access to good, clean, curated data. The SAS Data Management business unit is responsible for helping users create standard, repeatable methods for integrating, improving, and enriching data. This project is being sponsored by the SAS Data Management business unit in order to help users better leverage their data assets.
Background and Problem Statement
An increasingly prevalent and accelerating problem for businesses is dealing with the vast amount of information they are collecting and generating. Combined with lacking data governance, enterprises are faced with conflicting use of domain-specific terminology, varying levels of data quality/trustworthiness, and fragmented access. The end result is a struggle to timely and accurately answer domain-specific business problems and potentially a situation where a business is put at regulatory risk.
The solution is either building, or buying, a data governance solution to allow you to holistically identify and govern an enterprise's data assets. At SAS we've developed a data catalog product which enables customers to inventory the assets within their SAS Viya ecosystem. The product also allows users to discover various assets, explore their metadata, and visualize how the assets are used throughout the platform.
Now we have established the lay of the land, let's consider two cases which expose some of the weaknesses of a data catalog:
- As part of some financial reporting, an enterprise has some number of data tables upon which an ETL (exchange-transfer-load) flow is performed to generate a report-ready data table that is used in displaying or generating the content for a report. Currently in our data catalog, we have the ability to identify these individual assets, but only via their lineage are we able to understand their connection. Additionally, we don't have the ability to govern (in terms of authorization, versioning, etc.) all the assets involved in this process (input data tables, ETL flow, report-ready table, report) as a unit, but only as individual assets.
- In an enterprise, data assets are typically owned by a given business unit and for another party/business unit to make use of their data they'll need to go through some type of request process and then get a copy/tailored version of the data asset(s) for the requestor's use case. Currently in our data catalog, you may be able to identify a set of assets and who the owner of those assets is within your enterprise, but there is no formal mechanism for gaining and governing access.
This brings us to a burgeoning concept known as "data as a product "and "data products" in industry (see terminology below). A data product is a combination or set of reusable data assets curated to solve a specific business problem for a data consumer. If we could create the concept of a data product and data product catalog on top of our existing data catalog, we could realize the connections of existing assets and govern their entire lifecycle as one unit.
Terminology
Data as a product is the concept of applying product management principles to data to enhance its use and value.
Data product is a combination of curated, reusable assets (likely datasets, reports, etc.) engineered to deliver trusted data (and metadata) for downstream data consumers to solve domain-specific business problems. A more technical definition of a data product would be a self-describing object containing one or more data assets with its own lifecycle.
Data catalog is a centralized inventory of an organization/ecosystem's data assets and metadata to help them discover, explore, and govern their data.
Data product catalog is similar to a data catalog, but the inventory doesn't consist of an organization's data assets, but it's product. The focus of a data product catalog is to reduce the gap between data producers and consumers to help data consumers solve their domain-specific problems.
Project Description
As part of this project, you'll begin the work of creating a data product catalog. The tool must allow users to define a blueprint/template for a data product (i.e. name, description, shape/characteristics of assets, etc.). After a blueprint is defined, the user must be able to perform an analysis of available metadata and receive suggestions of potentially existing data products in the metadata. If a user believes one or many of the suggestions are accurate, they must be able to create a data product object based on the suggestion.
Data Product Blueprint and Instances
The tool must be able to define a blueprint for a data product (`data product blueprint`) and allow for instances of the blueprint (`a data product`) to be created.
The tool must also support the remaining basic CRUD (create, read, update, delete) operations for blueprints and instances of the blueprints. The tool may support versioning.
As a suggestion, see the following model: https://docs.open-metadata.org/v1.4.x/main-concepts/metadata-standard/schemas/entity/domains/dataproduct
Metadata
The sponsor will provide a script for the generation of synthetic metadata based off the Open Metadata schema (https://docs.open-metadata.org/v1.4.x/main-concepts/metadata-standard/schemas). The generated metadata will be available in a CSV format and the tool must be able to upload or otherwise ingest the metadata.
Identification
Given metadata and a data product blueprint, the tool must allow the user to run a identification algorithm to provide suggestions from the metadata for assets matching the blueprint.
The implementation of the identification algorithm is up to the team, but the algorithm:
- should be performant (to be defined by team in collaboration with sponsors). On a small amount of metadata, the algorithm should run in seconds.
- must provide results as suggestions with some type of ranking/score
- may provide the ability for the user to define any configuration properties for the algorithm
Manual Assignment
Given metadata and a data product blueprint, a user with knowledge of a data product must be able to use the tool to manually create a data product (an instance of a data product blueprint). The creation process must include mapping of metadata to the data assets defined in data product blueprint.
Technologies and Other Constraints
- Any open source library/packages may be used.
- This should be a web application. While the design should be responsive, it does not need to run as a mobile application.
- React must be used for UI.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Clariant is a multinational specialty chemical producer. Clariant is a leader in the sustainability transformation of the chemical industry. This is reflected in our purpose “Greater Chemistry – between People and Planet”. It has been rated as among the top 4% of its industry peers, according to the Dow Jones Sustainability Index. Our ambitious Greenhouse Gas reduction targets have been approved by the Science Based Targets initiative (SBTi).
Background and Problem Statement
Climate Change is already causing catastrophic events in all parts of the world: in 2023 alone, 53,685 fires burned nearly 2.61 million acres, the Worst Flood in Decades Rocked Somalia and Kenya, Melting Glacier Lake Caused Extensive Flooding in India, Storm Ciarán proved deadly through Western Europe, and Thousands were Displaced by Floods in Ghana as Dams Overflowed, to name only a fee examples.
Clariant wants our employees to be aware of the problem, and be part of the solution. We would like to create a sense of urgency among each and every one of our employees, their families, and visitors to our sites.
However, lecturing, and talking about dooms-day prophecies only numbs and disengages the audience. Also, many people believe they don’t have much of a role to play in fighting Climate Change. But for an employee of a specialty chemicals company, there is plenty of opportunity. We want to convey this message to our employees, and achieve several other goals at the same time:
- Do it in a way, without preaching, blaming, but in a fun and interactive way
- Put the audience in a driving seat of fighting Climate Change, instead of being a silent spectator
- In a fun way, educate the audience about sustainability, and give them the experience of making decisions that affect Climate Change, their cost impacts and the dilemma built therein
- Inform and build pride about the progress Clariant is making towards emissions reduction
- Allow employees to submit real ideas during the game
Project Description
We would like to build a web-based game showing a simulated city (isometric view), where the player can make decisions affecting Greenhouse Gas (GHG) emissions. The game link will be sent to every employee, and also offered on a big screen in the reception area of each of our sites.
The City will have the following structures (also depicted in isometric view):
- Coal fired power plant: present at the start of the game
- Solar panel farm: can be added by user
- Wheat + Sugarcane farms: present at the start of the game
- Ethanol plant: present at the start of the game
- An oil field: present at the start of the game
- A palm plantation
- A forest
- The Clariant tower holding a display of our annual Scope 1, 2 and 3 emissions
- Other moving parts of Clariant’s sustainability journey, to be discussed during the course of the project
The player can make some interactive decisions such as:
- Converting part of the electricity purchases from the coal fired power plant to
- a solar plant; or
- a renewable Power Purchase Agreement (PPA),
- purchase of Renewable Energy Credits (REC), or
- Use of biomass (displayed on the screen as trimming down of a forest area, which will grow back over time).
- Converting part of natural gas fuel purchases to biomass based fuel
- Replacing petrochemical feedstocks with biobased feedstock
- Increase biofuels production
- Insulate our factories to prevent loss of heat
- Other actions representing various ideas in our pipeline: the software should make it easy to expand this list of options
Employees will be encouraged to play in pairs or groups, to foster communication and ideation.
Each action that the player takes will lead to:
- Revision of the estimated annual emissions of Clariant
- Audio or visual explanation of the flagship activities going on in Clariant related to the action taken by the player.
- Hyperlinks to jargon (eg: PPA, REC, etc) to help the player learn more about what these are,
- Explanation of regrettable consequences of overdoing the action, or other pitfalls (eg: over-harvesting of forests, wheat straw, etc.) and what Clariant is doing to avoid them
- The cost impact of implementing that action throughout Clariant.

Technologies and Other Constraints
The game should be deployable over the web. I suggest the team divide and conquer the project by working on multiple topics in parallel:
- Subteam 1 develops the backend calculation engine, that
- maintains a tally of variables such as
- Date (starts at Jan 1st, 2025 and increments by one day per second, or another customizable rate)
- Current production volume: increases every year by 3% of another customizable rate
- Current electricity, natural gas, steam and biomass consumption and their prices: prices increase every year
- Current fossil based raw materials consumption
- Production Costs
- Investments made
- Market price of a solar plant: decreases with time
- calculates and displays (on demand, or constantly on a billboard), values such as
- Emissions (Scope 1, Scope 2 and Scope 3)
- Other variables
- seeks inputs from the user on actions to take, and recalculates the above variables. A menu of possible actions for the user to take (about 30), and their impact on the above variables will be provided at the start of the project.
This should be capable of running independently even without graphics, eg: via a text interface or command prompt. This development need not depend upon or be delayed by the development of the graphical interface. - maintains a tally of variables such as
- Subteam 2 develops the graphical interface to
- seek inputs from the player
- convey the results of the actions, and
- display the scoreboard (current statistics of the company such as emissions, production, investments made, product cost, and all the variables being tracked by the backend).
Start with a rough graphic, and connect to the backend calculation engine around week 3 or 4, and then keep refining the graphics.
Add General Knowledge tidbits that show up upon hovering. For example, hovering on a forest would produce the pop-up: “We cant count on forests to do our job. It will take 1.5 million acres of forests to absorb the emissions caused by Clariant’s businesses”.
News ticker that will display climate related news headlines, such as “Hottest summer recorded in Las Vegas”. Headlines should be sourced from a CSV file, with 2 columns: Date, and Headline.
Sponsor Background
Impartial is a three-year-old 501c3 that serves US criminal justice non-profits. The way we do that is through programs like: criminal justice video games, prison artwork, memberships, and more. Our vision is for Americans to evolve the US criminal justice system to align more closely with truth and justice. We want to teach law students and others the real issues and conditions of our existing criminal justice system to prepare them for leadership and involvement.
Background and Problem Statement
The US criminal justice system is fraught with inconsistencies and inequities that we have created or allowed. Criminal justice non-profits are agents of change that often give the best results to fill in the gaps and correct errors. The next generation of criminal justice leaders need to be apprised of what the criminal justice playing field is. We are using an actual prosecution to create this game.
Experiencing an actual prosecution gives those interested parties firsthand knowledge of all the twists, turns and opportunities. It affords people practicing to be attorneys a chance to make mistakes and correct them. It affords people who don’t understand our criminal justice system a chance to get involved in issues they didn’t know existed. When you begin to break down the criminal justice system into pieces and choices, you begin to understand where the problem and opportunities lie.
We have previously created an Investigation game, Grand jury game and an Arraignment/Plea Deal game. Concurrently, we are working on jury selection and Motions to dismiss. This game is the Prosecution’s Case.
There are seven people testifying and evidence to be presented. The people testifying are two experts and three government witnesses and two investor witnesses.
The experts for the Prosecution are a Securities and Exchange auditor and a Government forensic financial expert. Three witnesses are “cooperating Government witnesses” meaning that they have admitted guilt and agreed to cooperate with the Government in exchange for a more positive sentence/outcome. Two witnesses were investors in the VC Fund at issue and describe how they came to know about the Fund and their investment experience.
There is actual trial testimony used in this game from the witnesses, prosecutor and defense attorney. When a witness testifies, you have their words, the questions and comments from both the prosecutor and the defense attorney. How they say, what they say and what they can “prove” is on display for the jury and judge. The witnesses are under oath to tell the truth.
Project Description
The best solution for players is to experience what decisions affect the outcomes of justice. This game sets the stage for the decision makers of the case. As a player, you make choices and in time, learn the far-reaching effects of those decisions.
Again, this game is based on an actual prosecution.
There are seven witnesses for the prosecution - two government experts, three are cooperating government witnesses and two are investors of the Fund at issue. Each witness has or does not have influence over the outcome of the case, you/we choose.
Government experts should know their trade well and be able to explain both their methods and their conclusions. For example, the financial forensic expert - Can you explain the methodology and processes you used to analyze the financial data related to this case? Based on your forensic analysis, what specific financial irregularities or evidence of money laundering did you uncover?
The Securities and Exchange Auditor might ask - Can you detail the discrepancies you found during your audit of the securities/firm involved in this case or did you find any? Based on your expertise, were there any discrepancies that violated an investor’s rights? Have you audited the firm or fund previously and if so, what were your findings?
Govt Witness #1 - Tim - Did you conspire with anyone to deceive investors? Did you talk to any investors? Did you carry out your professional responsibilities well in the role assigned to you as CFO?
Govt Witness #2 - Scotty - How were decisions made for the 5 person management team as it related to investing in portfolio companies? Were you always truthful to your investors? Govt Witness #3 - Jonathan - Were you always truthful to your investors? Did you vote to include the portfolio companies that comprised the VC Fund? Do you have any regrets about the VC Fund?
Investor #1 - Strickland - Did you read the Offering Circular and sign the documents related to the VC Fund? Did the defendant help you in any way to make a decision or give you information about investing in the VC fund? Did you understand and accept the risk level of the investment? Investor #2 - Dwyer - Did you read the Offering Circular and sign the documents related to the VC Fund? Who or what did you rely on to make your investment decisions and stay informed? Did you understand and accept the risk level of the investment?
All the witnesses are questioned by the prosecutor and it is likely that the prosecutor can accurately anticipate their answer because it is their witness. However, the criminal defense attorney has an opportunity to cross-examine each witness, as needed. There can be surprises for each question. Maybe a deposition will give an impeachment opportunity. Maybe someone will commit perjury. Maybe people remember something the way they wanted it to be instead of as it was.
Technologies and Other Constraints
We will pick up where the prior games (Investigation, Grand Jury, Plea Deals/Arraignment) left off. The same technology can/will continue from the Plea Deal/Arraignment game unless there is a compelling reason to choose otherwise. We are open to supplementing the technology with additional selections as needed or warranted.
The assets built in prior games can continue to be used. These include conference rooms, offices, airport scenes and all the characters (about 6) from the Investigation game. Additional assets can/will be added to ensure that the game is well supported.
Justice Well Played will be featured on our website when it is playable and/or when opportunities for others to join in on its development (testing, for example) are available.
The game is owned by Impartial and will be used as a source of revenue for Impartial’s operation or donated to other criminal justice non-profits. Students will be able to use the game to demonstrate their participation and credentials but not to make income or allow anyone or any entity to do so. We will need a written agreement substantiating that understanding.
To the extent that any student has ideas that add value to the existing or potential game, we are very interested in your thoughts. This is an extremely collaborative endeavor. Thank you.
Sponsor Background
Impartial is a three-year-old 501c3 that serves US criminal justice non-profits. The way we do that is through programs like: criminal justice video games, prison artwork, memberships, and more. Our vision is for Americans to evolve the US criminal justice system to align more closely with truth and justice. We want to teach law students and others the real issues and conditions of our existing criminal justice system to prepare them for leadership and involvement.
Background and Problem Statement
The US criminal justice system is fraught with inconsistencies and inequities that we have created or allowed. Criminal justice non-profits are agents of change that often give the best results to fill in the gaps and correct errors. The next generation of criminal justice leaders need to be apprised of what the criminal justice playing field is.
Experiencing an actual prosecution gives those interested parties firsthand knowledge of all the twists, turns and opportunities. It affords people practicing to be attorneys a chance to make mistakes and correct them. It affords people who don’t understand our criminal justice system a chance to get involved in issues they didn’t know existed. When you begin to break down the criminal justice system into pieces and choices, you begin to understand where the problem and opportunities lie.
We have previously created an Investigation game, Grand jury game and an Arraignment/Plea Deal game. This game is the Jury Selection/Judge Instruction/Opening statement game.
Jury selection in a criminal trial, also known as voir dire, involves attorneys from both the prosecution and defense questioning a pool of potential jurors to assess their suitability and impartiality regarding the case at hand. This process ensures the selection of a fair and unbiased jury by allowing both sides to challenge prospective jurors for cause, where legal justification is provided, and through peremptory challenges, which do not require any reason.
A federal judge's instructions to the jury provide the legal standards that jurors should follow when deciding a case. These instructions cover the relevant laws, how to assess evidence, and the criteria for determining the defendant's guilt or innocence, guiding the jury on applying the law impartially and reaching a verdict.
Opening statements in a federal criminal trial are the initial remarks made by both the prosecution and the defense to the jury, outlining their cases. These statements set the stage for the evidence that will be presented, providing a roadmap of what each side intends to prove, without arguing the case or presenting opinions.
Project Description
The best solution for players is to experience what decisions affect the outcomes of justice. This game sets the stage for the decision makers of the case. As a player, you make choices and in time, learn the far-reaching effects of those decisions.
This game is focused on an actual prosecution.
Picking a jury is a serious matter. Do you have any personal experiences with the legal or criminal justice system that might affect your judgment in this case? Are you acquainted with anyone involved in this case, including witnesses, lawyers, or the defendant? Do you have any preconceived notions about the guilt or innocence of the defendant? Is there anything in your background or beliefs that would prevent you from rendering a fair and impartial verdict based solely on the evidence presented and the judge’s instructions? Can you commit to serving for the entire duration of the trial, which is expected to last a week? Have you seen or read any media coverage of this case, and if so, has it influenced your perspective in any way? Do you have any biases against or strong feelings towards the laws involved in this case? Are you comfortable evaluating potentially evidence without letting it affect your impartiality? What if the potential is wrong about their self assessment? How would anyone know if they don’t say?
Are the judge’s instructions clear, taken seriously and how do we know that they are understood and followed throughout the entire case? What if a Juror has a question? What if a Juror doesn’t follow the Judges instructions? How do we know that the Jury is doing what has been asked of them?
What are the primary objectives of the prosecution and defense during their opening statements in a criminal case? How do attorneys use opening statements to frame the narrative of the case for the jury? What weight should be put on opening statements and why?
Technologies and Other Constraints
We will pick up where the prior games (Investigation, Grand Jury, Plea Deals) left off. The same technology can/will continue in the Motion to Dismiss game unless there is a compelling reason to choose otherwise. We are open to supplementing the technology with additional selections as needed or warranted.
The assets built in prior games can continue to be used. These include conference rooms, offices, airport scenes and all the characters (about 6) from the Investigation game. Additional assets can/will be added to ensure that the game is well supported.
Justice Well Played will be featured on our website when it is playable and/or when opportunities for others to join in on its development (testing, for example) are available.
The game is owned by Impartial and will be used as a source of revenue for Impartial’s operation or donated to other criminal justice non-profits. Students will be able to use the game to demonstrate their participation and credentials but not to make income or allow anyone or any entity to do so. We will need a written agreement substantiating that understanding.
To the extent that any student has ideas that add value to the existing or potential game, we are very interested in your thoughts. This is an extremely collaborative endeavor. Thank you.
Sponsor Background
Impartial is a three-year-old 501c3 that serves US criminal justice non-profits. The way we do that is through programs like: criminal justice video games, prison artwork, memberships, and more. Our vision is for Americans to evolve the US criminal justice system to align more closely with truth and justice. We want to teach law students and others the real issues and conditions of our existing criminal justice system to prepare them for leadership and involvement.
Background and Problem Statement
The US criminal justice system is fraught with inconsistencies and inequities that we have created or allowed. Criminal justice non-profits are agents of change that often give the best results to fill in the gaps and correct errors. The next generation of criminal justice leaders need to be apprised of what the criminal justice playing field is.
Experiencing an actual prosecution gives those interested parties firsthand knowledge of all the twists, turns and opportunities. It affords people practicing to be attorneys a chance to make mistakes and correct them. It affords people who don’t understand our criminal justice system a chance to get involved in issues they didn’t know existed. When you begin to break down the criminal justice system into pieces and choices, you begin to understand where the problem and opportunities lie.
We have previously created an Investigation game, Grand jury game and an Arraignment/Plea Deal game. This game is (two) Motions to Dismiss due to destruction of all the original business records related to the charges and perjured Grand Jury testimony. .
In a criminal case, a motion to dismiss is a formal request made by the defense, asking the court to dismiss the charges against the defendant. This motion argues that there are legal or procedural reasons why the case should not proceed to trial. If granted, the charges are dropped, and the defendant is released from those charges without further prosecution on those specific grounds. Common reasons for a motion to dismiss include:
- Violation of Rights: The defendant’s rights may have been violated (e.g., unlawful search or seizure).
- Procedural Errors: Errors in how the case was handled, such as mishandling of evidence, may invalidate the charges.
If original business records were destroyed, a motion to dismiss may be filed on the grounds of spoliation of evidence or insufficient evidence. Here’s how these reasons are typically argued:
- Spoliation of Evidence: The destruction of original business records may be considered spoliation if it is found that these records were deliberately or negligently destroyed. The defense could argue that the absence of these records prevents a fair trial, as it removes potentially exculpatory evidence (evidence that could prove the defendant's innocence).
- Insufficient Evidence: If the prosecution’s case relies heavily on these records or testimony, their destruction or perjury could mean there is insufficient evidence to support the charges. Without the records and credible testimony, the prosecution may lack the necessary proof to meet the burden of establishing guilt beyond a reasonable doubt.
A motion to dismiss due to perjured testimony is a legal request made by a defense attorney when it is discovered that false statements, knowingly made under oath by a witness or party involved, have potentially influenced the case's proceedings. This motion argues that the integrity of the judicial process has been compromised, making it unjust to continue with the prosecution. If granted, the motion results in the dismissal of charges against the accused, based on the premise that the prosecution's case is irrevocably tainted by dishonesty. The defense must provide evidence of the perjury and demonstrate its impact on the proceedings, compelling the court to reassess the fairness and validity of the case.
If the judge finds that the destruction of records and/or perjury impairs the defendant's right to a fair trial or significantly weakens the prosecution's case, they may grant the motion to dismiss…or not.
Project Description
The best solution for players is to experience what decisions affect the outcomes of justice. This game is specifically the Motion to Dismiss for destruction of original business records. As a player, you make choices and in time, learn the far-reaching effects of those decisions.
This game is focused on an actual prosecution.
Setting up the Motion to Dismiss game is deciding what choices are most compelling and logical to create fun and teachable moments.
Destruction of Documents: Who had possession of the documents? How do we know what were in the documents? How significant were those documents to proving the case? Why would anyone want the documents destroyed? Who last saw the documents? Was permission granted to destroy them during an active investigation? Who is being truthful? What weight would the documents have been in proving guilt or innocence? Was there some logical time that the documents would have normally been destroyed irrespective of the case? Who was responsible for the documents safekeeping and will they be held accountable? If you don’t have the original business records, are there substitute documents that could be used?
Perjured Testimony: Who perjured themselves at the Grand Jury? How much weight should be allocated to that person’s testimony relative to others that testified? What did they perjure themselves about? Who else testified and were they credible? How and when was it discovered that the witness lied? Who knew prior to the Grand Jury testimony what the answers to the questions being asked were or might be? If one person lies at the Grand Jury, what is the best course of action in fairness to all involved or should it be only in fairness to the defendant? Does it matter if 10 people testified or 2 people testified as to what the decision should be? What factors should go into making this decision to continue the case or dismiss the charges? How often are charges dismissed?
Choose the wrong path and you are locked up. Choose the right path and you may be locked up too.
Technologies and Other Constraints
We will pick up where the prior games (Investigation, Grand Jury, Plea Deals/Arraignment) left off. The same technology can/will continue in the Motions to Dismiss game unless there is a compelling reason to choose otherwise. We are open to supplementing the technology with additional selections as needed or warranted.
The assets built in prior games can continue to be used. These include conference rooms, offices, airport scenes and all the characters (about 6) from the Investigation game. Additional assets can/will be added to ensure that the game is well supported.
Justice Well Played will be featured on our website when it is playable and/or when opportunities for others to join in on its development (testing, for example) are available.
The game is owned by Impartial and will be used as a source of revenue for Impartial’s operation or donated to other criminal justice non-profits. Students will be able to use the game to demonstrate their participation and credentials but not to make income or allow anyone or any entity to do so. We will need a written agreement substantiating that understanding.
To the extent that any student has ideas that add value to the existing or potential game, we are very interested in your thoughts. This is an extremely collaborative endeavor. Thank you.
Sponsor Background
Katabasis is a non-profit organization that specializes in developing educational software for children ages 8-15. Our mission is to facilitate learning, inspire curiosity, and catalyze growth in every member of our community by building a digital learning ecosystem that adapts to the individual, fosters collaboration, and cultivates a mindset of growth and reflection.
Background and Problem Statement
It can be difficult for everyone to consider the long-term effects of their decisions in the moment, but particularly difficult for students with emotional and behavioral disorders (EBD). Students with EBD will often have increased rates of office discipline, suspension from school, and poor academic performance. Long-term outcomes for students with EBD also suffer as a result, including a significantly greater likelihood for school dropout, high unemployment, low participation in postsecondary education, increased social isolation, and increased levels of juvenile and adult crime.
By encouraging these students to give structure to and reflect on their decisions, we can empower students with EBD to take control over their thought processes and incentive structures. To this end, Decision Intelligence provides an excellent framework for decision modelling, and is highly scalable to all levels of technical fluency.
Project Description
We are seeking a group of students to develop a web interface for middle school students sent out of the classroom (or otherwise dealing with emotional or behavioural issues) to interact with to attempt to better understand their actions, external factors, and outcomes.
Developing an intuitive and approachable interface will be the key to success in this project. It should consist of an elicitation portion, display portion, and editing portion. For the elicitation portion, there should be a gamified way of getting the details of the situation from the student. This can take the form of a literal browser game, or be more indirect, such as phrasing questions in a more whimsical fashion with engaging graphics. The key is to make it approachable and intuitive. For the display portion, we want to see a clear flow from actions to outcomes, as established by the decision intelligence framework (which we will provide the team further details on). The goal here is to make it clear to the users how different actions can lead to different outcomes. We recommend a causal decision diagram (which we can again provide more documentation for), but are open to creative ways to display the same information. Finally for the editing portion, we want to make sure users are able to tweak and adjust the display that has been generated to better match their reality. The elicitation will likely never generate a perfectly accurate display, so we want to make sure users are able to refine the display until it best matches their actual real life circumstances.
In summary, the game should be developed around the following core feature set:
- Gamified and Intuitive Interface: The web platform created must be highly approachable and intuitive, given its target users are likely to have short attention spans and high potential for bouncing off or getting frustrated with systems they can’t understand. Making sure the experience
- Decision Intelligence Framework: The backbone of the system is the Decision Intelligence framework. This consists of a way of structuring the decision making process by identifying levers (or actions), external factors affecting your decision, intermediate factors that act as stepping stones to the final factor, outcomes, the things you are measuring as an end result. Ensuring the interface developed highlights and clearly communicates these factors is essential.
- OpenDI Toolset: The team will adhere to the open source OpenDI standards, which has some data protocols and initial codebases to branch off of. This will provide the team with some initial guidance on DI software development toolsets, and also give experience in working with open source projects.
Technologies and Other Constraints
We encourage students to utilize, adhere to, and potentially contribute to the OpenDI framework.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Dr. Srougi is an associate professor (NCSU- Biotechnology Program/Dept of Molecular Biomedical Sciences) whose research interests are to enhance STEM laboratory skills training through use of innovative pedagogical strategies. Most recently, she has worked with a team to develop an interactive, immersive and accessible virtual simulation to aid in the development of student competencies in modern molecular biotechnology laboratory techniques.
Background and Problem Statement
Biopharmaceutical manufacturing requires specialized expertise, both to design and implement processes that are compliant with good manufacturing practice (GMP). Design and execution of these processes, therefore, requires that the current and future biopharmaceutical workforce understands the fundamentals of both molecular biology and biotechnology. While there is significant value in teaching lab techniques in a hands-on environment, the necessary lab infrastructure is not always available to students. Moreover, it is clear that while online learning works well for conceptual knowledge, there are still challenges on how to best convey traditional ‘hands-on’ skills to a virtual workforce to support current and future biotechnology requirements. The need for highly skilled employees in these areas is only increasing. Therefore, to address current and future needs, we seek to develop virtual reality minigames of key laboratory and biotechnology skills geared towards workforce training for both students and professionals.
Project Description
The project team has previously created an interactive browser based simulation in a key biotechnology laboratory skill set: sterile cell culture techniques. This learning tool is geared towards university students and professionals. In the proposed project, we intend to develop 3 virtual reality minigames using the Unity game engine to reinforce the fundamental skills required to perform more advanced laboratory procedures that are represented in the simulation. The game interactions occur through the Meta Quest 3 VR system. This project will be a Phase II of a previous senior design project. Considerable progress was made by the team in the development of one minigame (i.e. use of a pipet aid, see below) and one biohaptic device for use in the minigame. This current project proposal will seek to focus on the refinement of that mini game, integration of the biohaptic as well as the creation of the other two minigames.
Minigame content: All minigames will feature the following core laboratory competencies that would benefit exclusively from advanced interactivity and realism: 1) how to accurately use a single-channel set of pipettes, 2) how to accurately use a pipet aid (minigame that has been created), and 3) how to accurately load samples into an SDS-PAGE gel.
Length and Interactivity: Minigames should aim to be around a 10-15 min experience. The games should allow users free choice to explore and engage in the technique while providing real-time feedback to correct any errors in user behavior. They should be adaptable for future use with biohaptic feedback technology to provide a ‘real world’ digital training experience. A prototype biohaptic pipet aid has been created and is available to iterate upon and improve.
Cohesion: The set of minigames should connect to themes and design represented in the virtual browser-based simulation previously developed. Therefore, the visual design of the minigames should closely match the real-world laboratory environment.
Technologies and Other Constraints
Students working on this project do not need to have the content knowledge of biotechnology or biotechnology laboratory skills. However, a basic interest in the biological sciences and/or biotechnology is preferred. This project will be a virtual reality extension of a browser based interactive simulation written in 3JS within a GitHub repository. Development of the minigames should be built in Unity. Games should be designed to be run on relatively low-end computer systems. Proper licensing permissions are required if art and/or other assets are used in game development.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Dr. Stallmann is a professor (NCSU-CSC) whose primary research interests include graph algorithms, graph drawing, and algorithm animation. His main contribution to graph algorithm animation has been to make the development of compelling animations accessible to students and researchers. See mfms.wordpress.ncsu.edu for more information about Dr. Stallmann.
Background and Problem Statement
Background.
Galant (Graph algorithm animation tool) is a general-purpose tool for writing animations of graph algorithms. More than 50 algorithms have been implemented using Galant, both for classroom use and for research.
The primary advantage of Galant is the ease of developing new animations using a language that resembles algorithm pseudocode and includes simple function calls to create animation effects.
Problem statement.
There are currently two versions of Galant: (a) a sophisticated, complex Java version that requires git, Apache ant, and runtime access to a Java compiler; (b) a web-based version, galant-js, accessible at https://galant.csc.ncsu.edu/ or via the github repository galant-js (https://github.com/mfms-ncsu/galant-js). The latter was developed by a Spring 2023 Senior Design Team and enhanced by teams in Fall 2023, Spring 2024, and Fall 2024. It has been used in the classroom (Discrete Math) and several algorithms have been successfully implemented. However, there are some major (and minor) inconveniences from a usability perspective.
Project Description
Some enhancements are required to put the useability of galant-js on par with the original Java version. The Java version has been used extensively in the classroom and in Dr. Stallmann’s research. The JavaScript version already has clear advantages, particularly when it comes to the rendering of graphs.
All teams working on the project are expected to produce transparent code and detailed developer documentation. It is essential that the sponsor, Dr. Stallmann, be able to continue development on his own or with the help of other students and future teams. To that end, he expects to be directly involved in the development, actively participating in coding and documentation.
The Fall 2024 team greatly simplified the back end of the code, replacing an opaque and difficult to modify mechanism with a much simpler, transparent one. However, some of the front end (user facing) functionality of the previous implementation are now missing and some bugs were introduced. The goal for Spring 2025 is to restore all functionality of the version currently at https://github.com/mfms-ncsu/galant-js and to implement additional functionality described in feature-requests.md at the root of the repository https://github.com/mfms-ncsu/galant-js in the sd-2024-8 branch.
Technologies and Other Constraints
Students are required to learn and use JavaScript effectively. The current JavaScript implementation uses React and Cytoscape for user interaction and graph drawing, respectively. An understanding of Cytoscape is required to address the challenge related to node positions on the screen.
The tailwind plugin in used for style sheets that determine screen positions, colors, fonts, and other features of buttons and other user interface elements.
Project Archives
| 2026 | Spring | Fall | |
| 2025 | Spring | Fall | |
| 2024 | Spring | Fall | |
| 2023 | Spring | Fall | |
| 2022 | Spring | Fall | |
| 2021 | Spring | Fall | |
| 2020 | Spring | Fall | |
| 2019 | Spring | Fall | |
| 2018 | Spring | Fall | |
| 2017 | Spring | Fall | |
| 2016 | Spring | Fall | |
| 2015 | Spring | Fall | |
| 2014 | Spring | Fall | |
| 2013 | Spring | Fall | |
| 2012 | Spring | Fall | |
| 2011 | Spring | Fall | |
| 2010 | Spring | Fall | |
| 2009 | Spring | Fall | |
| 2008 | Spring | Fall | |
| 2007 | Spring | Fall | Summer |
| 2006 | Spring | Fall | |
| 2005 | Spring | Fall | |
| 2004 | Spring | Fall | Summer |
| 2003 | Spring | Fall | |
| 2002 | Spring | Fall | |
| 2001 | Spring | Fall |