Projects – Fall 2019
Click on a project to read its description.
Background and Problem
Over the past decade, scientists and the public have become increasingly aware of declines in the health of managed honey bees, as well as populations of wild bees such as bumble bees. To help counteract these declines, many programs encourage individuals to install “pollinator gardens” on their properties. These habitats typically draw on lists of recommended, perennial plants known to provide pollen and nectar for bees. Although these habitats can be effective, in our local outreach and extension work, we have noted that garden design remains a barrier for many homeowners who are unsure how to create an aesthetically appealing garden using recommended pollinator plants.
To overcome this barrier, we would like to offer a web-based garden visualization app that lets homeowners map recommended plants into a garden space and view the virtual planting in three dimensions prior to installation. While similar apps do exist (for example, here https://www.bhg.com/gardening/design/nature-lovers/welcome-to-plan-a-garden/), they include few if any suitable plants and lack other desirable features, such as being able to view a garden in both side view and map/top view.
Solution Description
Based on work with the Senior Design Center in two previous semesters, a foundation for the envisioned app now exists. It allows users to:
- Filter available plants by height, bloom color, bloom season, soil type, shade tolerance, and plant type (vine, shrub, etc.)
- Drag and drop plants into garden space
- Switch between top view and side view of a garden
- Initial implementation of drawing tools to allow users to define a garden space
Working from this foundation, we would like to add the following functions:
- Fully implement user account creation, user authentication, and saving a garden design
- Fully implement drawing tools to allow users to define a garden space into which plants are placed (max size might be 70’x70’ or so)
- Update the view for different seasons, for example to visualize which flowers will bloom together or which season lacks flowers (distinct seasonal illustrations will ultimately be available for each plant)
- CALS IT has requested that there be regression tests for use in applying security upgrades to the packages used by the application, and requires that the app meet WCAG AA accessibility standards
Additional Considerations
- We would like the app to work in any browser and be mobile responsive. (Many existing garden design apps don’t run in Chrome, which is frustrating.)
- We envision an NC-centric app whose source code could be modified by/for Extension educators in other regions to operate based on their own available plant lists. Under what license could the source code be released?
- When ready for public use, the app will be hosted at NCSU with file storage on the CALS server and a MariaDB database hosted by OIT and managed by Michelle Jewell in Applied Ecology using a cPanel account; related technical specifications are available here https://docs.google.com/document/d/1yQBV1NLkMWYY4NkuCYrGTVlvtA_JA-cN0rOGl-aGvMo/edit#
Future Development
In time, we would like to add additional features to the app/website. In case it is useful to have these on the table from the start, they include the following functions for users
- Provide a way to pull up an information box about a plant by clicking on it, to show other information about that plant in the database (what species use the plant, what soil requirements it has, etc.)
- Generate a shopping list based on plants in a garden design
- Implement “check garden” function, which alerts a user when their design does not meet all biological or design recommendations (e.g., your design lacks flowers in July, or all your plants are the same height.)
- Optionally (for the truly design-timid user), select a garden style (e.g., English cottage vs. modern) and preferred bloom colors, to produce an automatically populated garden, which they can then modify by dragging/replacing plants
- Input their own data and observations about rates of insect visits to different plants
- Upload a background image (e.g., their house) against which the garden could be viewed
- Add or request their own custom plants
- Summarize garden attributes--e.g. provide charts/visualizations that summarizes bloom color, timing, shape, and other attributes associated with the check garden feature
Weekly Meetings
During weekly sponsor meetings, we will review new developments in the app and provide feedback and clarification related to the goal of making it possible for anyone to design an attractive, bee-friendly garden.
Students will be required to sign over IP to Sponsor when team is formed.
Problem Statement
BlackBerry QNX technology includes QNX Neutrino OS and many middleware components. BlackBerry has decades of experience in powering mission-critical embedded systems in automotive and other industries. As the leader in safety-certified, secure, and reliable software for the automotive industry, BlackBerry currently provides OEMs around the world with state-of-the-art technology to protect hardware, software, applications and end-to-end systems from cyberattacks.
For Self-Driving Cars, functional safety is part of the overall safety of a system or piece of equipment and generally focuses on electronics and related software. As vehicles become increasingly connected and reliant on software, new threats emerge. Therefore, it is imperative that a vehicle operates safely, even when things go wrong. A self-driving car is an extremely complex system with state-of-the-art technologies. Proving that the system does what it is designed to do is a great challenge. And it must do so in a wide range of situations and weather conditions. This requires a stable, secure and efficient operating system.
To ensure mission critical reliability, BlackBerry QNX continually performs extensive automated testing of their software components by executing hundreds of thousands of tests daily. The current process of identifying trends, issues and generating charts and reports from these tests consume a tremendous amount of human effort.
Automating this process and generating visual representations of trends and issues would help to identify software issues as early as possible and enable employees to focus on other tasks.
The current dashboard web application, “BlackFish”, is a Single-Page Application (SPA) developed using the Angular framework, from previous semester's senior design projects at NCSU. The SPA has provided us with a good starting platform, however, with the current structure of the project, all components must be known at build time, which does not scale well when many pages (tools) are being developed. We expect the number of tools to grow to many dozens over time, but typically an individual user will only work with a handful, so there is no need for the dashboard to load 100% of the components for a user. We would like to have a more fluid, modularized platform that allows for smaller pieces of the dashboard to be dynamically added or updated without affecting the whole dashboard.
Project Description
Previous NC State senior design teams have built the framework for the BlackFish Web Application using a Single Page Application in Angular 7 for the front end, with a Node.js/Express backend, connecting to a MongoDB server (where the test results are stored).
The goal of this semester’s project is to identify an efficient way to convert the existing SPA BlackFish Web Application into a modularized platform that allows for smaller pieces of the dashboard to be dynamically added or updated without affecting or restarting the whole dashboard. This would also have the additional benefit of minimizing the initial load size and time (lazy loading).
One possible solution may be to go from one large single-page application (SPA) into a wrapper SPA made up of multiple individual SPA's. However, the team should identify and propose alternative solutions to accomplish this goal during the first few design meetings. The mentors, together with the team, will discuss the pros and cons of each solution and together determine the best implementation. At that point the team should develop the selected option using the existing BlackFish Web Application as a base.
The team will be expected to:
- Utilize the BlackFish (Central Test Management) Web Application that hosts the dashboard adapted from the solution provided by previous NC State senior design teams.
- Enable the existing web application to accept newly constructed tools or updated tools at runtime without taking down the main server.
- Enable Lazy Loading of Tools: Minimize the initial page load size on startup by only loading the necessary components.
- Develop a workflow or best practices on how to add tools dynamically to a live server.
- Convert the existing 'Aggregate Tool', from last year's senior design team, to be dynamically loaded onto the live server as a proof of concept.
- Document the proposed workflow and best practices on how to add tools dynamically to a live server.
- Hold frequent design meetings to discuss the progress and design propositions. With the short semester project schedule, we recommend weekly meetings to ensure that the visions and design propositions scale well to support parallel development by BlackBerry engineering teams.
- Frequently commit code changes to the shared Git repository to allow the sponsors to follow the work and enable constructive feedback. With the short semester project schedule, we recommend that commits be performed on at least a semi-monthly frequency to ensure that the visions and design propositions blend.
- If time permits, create admin and user pages to enable editing and configuration of user settings and preferences that are stored as JSON documents in the Mongo Database.
- The web application must be able to support permalinks for reloading specific modules.
- All client-side applications should be capable of running in any modern web browser without requiring additional extensions.
Skills, Technologies & Constraints
Some prior experience developing web (server-client) applications is strongly recommended for this project.
Members of the team would be expected to have or learn some of the following skills:
- JavaScript/Node.js
- Angular
- JSON
- HTML
- REST API
- MongoDB (Basic database experience suggested)
- Version Control System (Git)
The client-side dashboard must be written in a language supported by modern web browsers; a modern JavaScript framework is strongly suggested. Any additions or updates to current code base must run on Linux and Windows OSes.
Support
BlackBerry QNX mentors will provide support at the beginning of the project for a project overview, initial setup, and assistance in the software tool selection.
The students will also be provided with:
- Previous semester's senior design team code base
- Sample data in a MongoDB database containing test data
- Demonstration of current proof of concepts developed
- Guidance on setting up development environment and supporting tools
Mentors will be available to provide support, planning sessions, Q & A, technical discussions and general guidance throughout the project. Mentors will also be available for meetings on campus as necessary.
About BlackBerry
BlackBerry is an enterprise software and services company focused on securing and managing IoT endpoints. The company does this with BlackBerry Secure, an end-to-end Enterprise of Things platform, comprised of its enterprise communication and collaboration software and safety-certified embedded solutions.
Based in Waterloo, Ontario, BlackBerry was founded in 1984 and operates in North America, Europe, Asia, Australia, Middle East, Latin America and Africa. For more information visit BlackBerry.com
About QNX
Customers rely on QNX to help build products that enhance their brand characteristics – innovative, high-quality, dependable. Global leaders like Cisco, Delphi, General Electric, Siemens, and Thales have discovered QNX Software Systems gives them the only software platform upon which to build reliable, scalable, and high-performance applications for markets such as telecommunications, automotive, medical instrumentation, automation, security, and more.
QNX software is now embedded in 120 million cars that are on the road today. Automotive OEMs and tier ones use BlackBerry QNX technology in the advanced driver assistance systems, digital instrument clusters, connectivity modules, handsfree systems, and infotainment systems that appear in car brands, including Audi, BMW, Ford, GM, Honda, Hyundai, Jaguar Land Rover, KIA, Maserati, Mercedes-Benz, Porsche, Toyota, and Volkswagen.
Students will be required to sign Non-Disclosure Agreements and sign over IP to BlackBerry when the team is formed.
The Assignment
Several commercial products are available for Optical Character Recognition (OCR) data extraction. Vendor products however tend to be expensive. Moreover, as is true with any third party offering, consumers have limited influence over the evolution of the product and are forced to adapt internal processes to operate within the constraints of a generically designed product. Development of internal technology to support this function would not only benefit Deutsche Bank on several fronts, but also affords exploration into several different areas of cutting edge technology such as Optical Character Recognition and Machine learning.
Please review the following high level specifications and requirements.
Sample Use Cases
- Mobile banking check deposits
- Fraud detection and prevention
The below will be refined in greater detail during scoping with the team.
- Starting with an input image (i.e. a check), extract the following data points:
Signature Extraction - Routing / Account Number
- Date
- Payable to
- Amount (numeric and text)
- Memo
- Perform reasonability checks/edits on extracted data [to be further defined and prioritized in requirements gathering – examples include match between amounts (numeric/textual), signature consistency (sample signatures are required to help model algorithm), date, etc…]
- Generate an output JSON file of select data points for further process.
Create a web interface to perform the following:
- Upload image and invoke process
- Display uploaded image
- Display results of the reasonability check
- Link to html file of the JSON file output
2019 Fall Semester
Students will use their course knowledge, creativity, and technical expertise to delve deep into the exciting domains of optical character recognition and machine learning. DBGT will thought leadership, direction, guidelines, technical expertise (as needed) and support in refining the project scope. The DBGT team is here to aid and guide the student workflow, processes, and design ideas. We support and encourage the students’ input on this project. Use of open source and readily available OCR or ML libraries is permitted. Students may use technologies of their choice when completing this project.
The NCSU Student Experience
Senior Design students in the College of Engineering Department of Computer Science will have a unique opportunity to partner together over the course of the semester to explore the exciting and developing field of OCR/ML with direct application to a real business problem. Additionally, students will have access to industry professionals to assist in the software design, agile practices, and the overall code development and testing. Students will be allowed to share the final product as part of their own portfolio while job seeking.
The Dell/EMC senior design project will give the team a chance to develop software that improves the real-world performance of Dell/EMC backup and restore software. The team will identify optimal strategies for handling different types of backup / restore loads, then apply those strategies to new applications to automatically improve their performance.
Background
Data Domain is the brand name of a line of backup products from Dell/EMC that provide fast, reliable and space-efficient online backup of files, file systems and databases ranging in size up to terabytes of data. These products provide network-based access for saving, replicating and restoring data via a variety of network protocols (CIFS, NFS, OST). Using advanced compression and data de-duplication technology, gigabytes of data can be backed up to a Data Domain server in just a few minutes and reduced in size by a factor of ten to thirty or more.
Our RTP Software Development Center develops a wide range of software for performing backups to, and restoring data from, Data Domain systems, including the Data Domain Boost libraries used by application software to perform complete, partial, and incremental backups and restores.
As Data Domain makes its way into even more data centers, the need to accommodate additional workloads is increased. Customers must be able to backup their data efficiently to meet constantly decreasing backup time periods.
This concept or requirement also applies to the restoring of the data/databases. Dell/EMC has developed technology for increasing efficiency and decreasing the time for data to be backed up and for the data to be protected.
The focus of this project is to determine the optimum behavior of the Data Domain software for several data restore access patterns. Depending on the behavior of the application performing the data restore, we need to determine the optimum settings for several parameters that will modify the behavior of our internal software library.
Students will use predefined access methods to restore data files from a Data Domain Virtual System and, based on the time / throughput of the restore, modify one or more parameters to decrease the time of the restore, improve the throughput of the restore, or both.
These parameters (collectively called a profile) will be used by our DD Boost software to optimize the restore process.
Project Scope
We want to determine the optimum parameters of workflow profiles for different read access patterns. Dell/EMC did a project with the Senior Design Class in spring 2019 that determined a “golden” profile for a specified set of workflows. The output of this project was a ReadOp system, which used guided Linear Regression analysis to arrive at an optimal access pattern profile for a specified workload.
In this project we want to build on that previous work and enhance this ReadOp system.
The previous work determined optimal settings for 3 specific access patterns:
- Sequential – data is read from the beginning to the end sequentially
- Random – all reads are random
- Sequential w/random “hops” – Most reads are sequential with a small percentage random
In the previous work the NCSU Senior Design team used supplied tools and developed software to restore a database and, based on the results, modified one or more of the profile parameters to reduce the time of the restore. The results for each individual test were stored using an internal database and data-mined to help identify the best parameter values for each profile.
This work was done “statically” or “off-line” in that the parameters for each test run were set before the run and remained constant during the run. Each run would modify the parameters based on the results of previous test runs. Analysis of the results and determination of good parameter values was then done after the runs using data mining.
The runs used a Data Domain network optimization protocol for backup/restore of data called DD Boost. DD Boost includes an Access Pattern Detection (APD) algorithm that can identify most use cases that are supported. The APD logic can be applied to DD Boost to control read-ahead cache. If the access pattern is detected to be Sequential, read ahead caching will be enabled/re-enabled. If the access pattern is detected to be Random, read ahead caching will be disabled.
In this project the team will use an enhanced DD Boost and APD that adjusts and modifies the input APD thresholds during a single restore run, to account for changes in access patterns during a restore workload. This will dynamically adjust the APD parameters based on the history of reads during the run. The purpose of this is to determine how quickly the parameters converge to optimal or near optimal values. The parameters that control when the original input values are modified and by how much will be varied on each run to determine overall optimal system performance.
The advantages of implementing this dynamic version of APD in DD Boost are:
- Intelligent Read ahead caching, based on actual ongoing access pattern detection and modified as the backup access pattern changes
- DD Boost access pattern will not be biased towards sequential reads nor by read ahead heuristics that may be either over-aggressive or not aggressive enough
The project being proposed consists of three phases: (1) Become familiar with the products and results from Spring 2019 (2) Determine the optimum dynamic access pattern profile for sequential restores (3) Determine the optimum dynamic access pattern profiles for other profiles as time permits: random restore access, sequential / random “hops” access pattern, others to be determined.
Phase One
- Use the software products from the Spring 2019 project to become familiar with Boost, APD, and how to run tests, save results, and mine the results
- May want to reproduce and verify one of the results from Spring 2019
Phase Two
Using the software supplied by Dell/EMC & from the Spring 2019 Senior Design project:
- Execute sequential restore operations and modify one or more dynamic profile parameters to attempt to improve the restore performance
- Record each dataset (parameters and results) in the MDTAG database on the DDVE
- Determine the optimum dynamic restore parameters for the profile and store the results in the database on the DDVE system
- Document the method to determine the optimum profile
- Document the parameters that impacted the performance most positively and negatively
- Document the optimum profile parameters
- Use Python/R machine learning
Phase Three
Using the software supplied by Dell/EMC & from the Spring 2019 Senior Design project:
- Repeat the steps in Phase Two for additional access patterns:
- Random access pattern
- Random “hops” access pattern
- Others to be determined as time permits
Materials Provided
- A Data Domain DDVE software package to be used for the duration of the project. This is the Data Domain virtual system that will receive and store backups.
- A set of binary tools with documented interfaces to be used for the profiles and test results.
- A test binary (“ddboost_stress”) that acts as a test backup application and that calls the standard Boost APIs. ddboost_stress allows for writing/reading multiple files simultaneously and, thus, allows for generating the necessary load to test and stress the Boost interfaces and can be used for data restore or generation.
- The products of the Spring 2019 project to be used as a starting point.
Materials Needed from NCSU
- Hardware and storage to host the DDVE (DDOS Virtual addition)
- A physical or virtual Linux client to be used for the restore testing using the DDVE over TCP/IP
Benefits to NCSU Students
This project provides an opportunity to attack a real-life problem covering the full engineering spectrum from requirements gathering through research, design and implementation and finally usage and analysis. This project will provide opportunities for creativity and innovation. Dell/EMC will work with the team closely to provide guidance and give customer feedback as necessary to maintain project scope and size. The project will give team members an exposure to commercial software development on state-of-the-art industry backup systems.
Benefits to Dell/EMC
The data generated from this engagement will allow Dell/EMC to increase the performance of the DDBoost product set and identify future architecture or design changes to the product offerings.
Company Background
Dell/EMC Corporation is the world's leading developer and provider of information infrastructure technology and solutions. We help organizations of every size around the world keep their most essential digital information protected, secure, and continuously available.
We help enterprises of all sizes manage their growing volumes of information—from creation to disposal—according to its changing value to the business through big data analysis tools, information lifecycle management (ILM) strategies, and data protection solutions. We combine our best-of-breed platforms, software, and services into high-value, low-risk information infrastructure solutions that help organizations maximize the value of their information assets, improve service levels, lower costs, react quickly to change, achieve compliance with regulations, protect information from loss and unauthorized access, and manage, analyze, and automate more of their overall infrastructure. These solutions integrate networked storage technologies, storage systems, analytics engines, software, and services.
Dell/EMC’s mission is to help organizations of all sizes get the most value from their information and their relationships with our company.
The Research Triangle Park Software Design Center is an Dell/EMC software design center. We develop world-class software that is used in our VNX storage, Data Domain backup, and RSA security products.
Background
Siemens Healthineers
Siemens Healthineers develops innovations that support better patient outcomes with greater efficiencies, giving providers the confidence they need to meet the clinical, operational and financial challenges of a changing healthcare landscape. As a global leader in medical imaging, laboratory diagnostics, and healthcare information technology, we have a keen understanding of the entire patient care continuum—from prevention and early detection to diagnosis and treatment.
At Siemens Healthineers, our purpose is to enable healthcare providers to increase value by empowering them on their journey towards expanding precision medicine, transforming care delivery, and improving patient experience, all enabled by digitalizing healthcare. An estimated 5 million patients globally benefit every day from our innovative technologies and services in the areas of diagnostic and therapeutic imaging, laboratory diagnostics and molecular medicine, as well as digital health and enterprise services. We are a leading medical technology company with over 170 years of experience and 18,000 patents globally. Through the dedication of more than 48,000 colleagues in over 70 countries, we will continue to innovate and shape the future of healthcare.
Managed Logistics
Our service engineers perform planned and unplanned maintenance on our imaging and diagnostic machines at hospitals and other facilities around the world. Frequently, the engineers order replacement parts. The job of Managed Logistics is to make the process of sending these parts to the engineer as efficient as possible. We help to deliver confidence by getting the right part to the right place at the right time.
Problem
Customer Order Discrepancies
Despite our best efforts, occasionally things go wrong somewhere along the supply chain, and we fail to fulfill an engineer’s order in a timely and correct manner. To reduce the number of times this happens, we keep track of these orders, analyze them, and discuss them. Our goal with this process is to identify and address an underlying root cause.
We use a third-party logistics team to help run our warehouse efficiently. We include them in our problem-identifying discussions when a warehouse issue leads to unsatisfactory orders. We call these warehouse-related issues Customer Order Discrepancies (COD). Currently, both our team and the third-party team keep track of information about these CODs in excel spreadsheets, and there are email chains for each issue.
Goals
Goal 1: Customizable Dashboard Generator
A dashboard provides a way to visualize and interact with a complex set of data. In addition to the CODs, the Managed Logistics team is in the process of transferring a lot of other spreadsheet-and-email-based processes into a web portal that will serve as a “one stop shop” for communication and issue tracking. [The Senior Design teaching staff expects that the student team will have access to the in-progress web portal code, and the flexibility to revise it in the process of building the Customizable Dashboard Generator.]
We are seeking a streamlined way to rapidly develop live, interactive, updatable dashboards for these processes. Our vision is that we could define some parameters for a new dashboard and have it quickly ready for deployment.
Goal 2: COD Live Dashboard
With the dashboard generator in place, we would like to create a dashboard for the COD process. With this web dashboard the ML team and 3rd Party team will be able to have more efficient problem-solving sessions because they will be interacting with the same real-time data in the same format. [The Senior Design teaching staff expects this important goal to involve data and process modeling as well as user experience design.]
Weekly Meetings
Students will get the opportunity to communicate frequently with our development team and a key end-user. At first, these meetings will be useful to define what we expect in terms of parameters and customization for the dashboard generator and to mutually agree on a more concrete set of requirements. Later, we will provide clarification and feedback to ensure both goals of the project are achieved.
Useful Knowledge
To get the most out of this project, experience with front-end development and Python is preferred.
Founded in Roanoke, VA in 1932, Advance Auto Parts (AAP) is a leading automotive aftermarket parts provider that serves both professional installer and do-it-yourself customers. Our family of companies operate more than 5,100 stores across the United States, Canada, Puerto Rico and the Virgin Islands under four brands, Advance Auto Parts, Carquest Auto Parts, WORLDPAC and Autopart International. Adapting the latest in data and computer science technology, the Advance AI team aims to bring machine learning and artificial intelligence to the automotive aftermarket parts market to turbo drive it forward into the digital era.
Project Overview
As AAP looks ahead to what the future of auto-parts retail might look like. One certain element will be maximizing the usage of mobile technology to deliver an amazing customer experience. To this end, we would propose a project to enable a fleet of independent mobile mechanics to provide common maintenance and repair services in an on-demand, ad hoc, and completely customer-centric manner (e.g. oil change or wiper-blade replacement while the customer is at work and the vehicle is in a parking lot).
Project Scope
The bulk of this project should center on an Android and iOS-compatible mobile app experience focused on the mobile mechanic(s). For the purposes of this project, the backend can be setup as a simple API server that would enable an eventual rollover to a full suite of services without a dramatic redesign or recode of the app.
Key Software Components
- Mobile Mechanic’s App - The primary interface for mobile mechanic service-providers to manage jobs.
- User Registration
- User Info
- Job Preferences/Qualifications
- Location Preferences
- Job Management
- Proposal/Acceptance
- Scheduling
- Pre-Job
- Tool/Part pickup
- Routing to customer’s vehicle
- Job Execution
- Start Job
- Unlock customer’s vehicle
- Access to online knowledge base/videos
- Provide photos of key job components
Lock customer’s vehicle - Finish Job
- Post-Job
- Return tools, old parts
- Receive Payment
- User Registration
- Backend Server
- User Setup
- User login/authentication
- Job Matchmaking
- Authorize Job Start
- Confirm Job Finish
STUDENTS WILL BE REQUIRED TO SIGN OVER IP TO SPONSOR WHEN TEAM IS FORMED.
Founded in Roanoke, VA in 1932, Advance Auto Parts (AAP) is a leading automotive aftermarket parts provider that serves both professional installer and do-it-yourself customers. Our family of companies operate more than 5,100 stores across the United States, Canada, Puerto Rico and the Virgin Islands under four brands, Advance Auto Parts, Carquest Auto Parts, WORLDPAC and Autopart International. Adapting the latest in data and computer science technology, the Advance AI team aims to bring machine learning and artificial intelligence to the automotive aftermarket parts market to turbo drive it forward into the digital era.
Project Overview
The customers that flow through AAP’s 5000+ retail locations form the lifeblood of our retail operations. So much of our value proposition for our DIY customers revolves around our ability to offer same-day pickup, a wide variety of parts, and friendly, expert advice, all in a convenient, nearby location. Stores play a critical part in our business and we want to make sure that we are using technology to maximize our ability to offer an outstanding customer experience. To this end, we would propose a project to create a secure, extensible Internet of Things (IOT) platform based on a Raspberry Pi that could be deployed into an AAP store and be used to collect data, run image-recognition or other computer vision tasks, and report back to an AWS-based data store.
Project Scope
The bulk of this project should center on the design and implementation of the AWS-based IOT backend network to centrally manage deployed Raspberry Pi(s), deliver instructions and updates, download and upload data, as well as manage memory and compute resources - all while maintaining tight security controls. We are very open to creative solutions on how best to satisfy the various requirements (see details below). For the purposes of this project, the students will be provided with an open source object detection model, and will need to implement simple wrapper code to perform inference on frame grabs from a USB webcam or similar device on the Raspberry Pi(s) for the use case of measuring in-store traffic as outlined below.
AAP will provide all appropriate hardware and access to cloud-based services
Key Software Components/Requirements
For the backend, our only hard requirement is that it is AWS-based. We would welcome student input and ideas on whether it takes advantage of all the AWS native IoT services, or takes the form of a lightweight EC2 machine (or two) coupled with S3. On the Raspberry Pi, our strong preference would be for a linux-based OS of some kind but we would entertain impassioned and/or well-reasoned arguments for other options (such as Windows IoT Core).
In-Store Traffic Counting
The Pi’s camera should capture images at a set (and tunable) interval to be processed by the object detection model. Data to be captured and shipped back:
- Time of grab
- Frame/image (scaled down to a reasonable size). Because sending the image back is a relatively bandwidth-intensive and may not always be necessary, each counting event should have a tunable probability of including the image in the data sent home.
- Bounding box coordinates for all model detections of class “Person” (or equivalent, depending on the specific model used)
This use case is just one of many possible uses/tasks for in-store Pi devices which could be run instead of, or simultaneously with, the traffic counting task. When designing the wrapper code to run the model and collect results, consideration should be given to modularity and reuse to simplify the addition of other tasks and functionality.
Security
The system must be very secure, with best-practices in encrypted communication and endpoint authentication implemented. Creative solutions for protecting against threats from unauthorized physical access are welcome but would not be as high of a priority.
Call back
The Raspberry Pi must be able to operate within the store’s network and will not be directly reachable from the Internet. It must be able to call out and establish a connection to backend infrastructure for any communications, both inbound and outbound. Lightweight records of device callbacks should be recorded in some fashion independent of any data collection tasks (such as the traffic counting use case, above)
Data download/upload
The Raspberry Pi must be able to connect to AWS-based data stores in order to download and upload data.
- Most downloads would likely center around bash scripts (or similar) that could:
- update device settings
- install/update packages and/or ML models
- configure/setup the Pi for additional tasks/functionality
- Potential data uploads could include:
- Results of ML models or other data collection tasks (see “In-Store Traffic Counting” above)
- Reporting system health/status
- The form of data communications could be as simple as reading and writing text files in S3
To the extent possible, the Raspberry Pi should minimize the number of writes it makes to its storage media during normal operations and use in-memory solutions wherever possible to support information security and help preserve the lifespan of the SD card. To the extent possible given memory and other constraints, the Pi should defer uploads and downloads until after business hours.
Device Management, Resiliency, and Scalability
The Raspberry Pi will need a minimum capacity for self-management to overcome minor issues and minimize downtime (e.g. the device may have set thresholds for temperature and cpu/memory usage and automatically shut down processes or reboot, as appropriate). This system would need to be able to be deployed in over 5000 different locations by non-technical personnel, potentially in places that are difficult to reach (mounted high up or on ceilings, etc.). As such, even requiring a power cycle for a single device could result in days of downtime – needing to replace the SD card would easily be multiple weeks.
Although it would not be feasible to individually administer all Pi’s in this distributed system, in (hopefully infrequent) cases of individual units requiring manual intervention/attention from an administrator, we would need a solution for establishing an interactive connection to that individual device (which cannot be reached directly from the Internet)
AAP administrators will need an interface to manage the tasking, updates, configuration, and security settings of all, some, or just one of the in-store devices. Such settings could include:
- Timing and target (url) of callback connections
- Turning on/off hardware interfaces or data collection tasks
- Temperature thresholds for just the Pis in Florida stores
Given the asynchronous, distributed nature of the data flow and the high downtime created by issues that may be easy to solve under normal conditions, students should consider how to test new tasking/update scripts before deployment to minimize this risk.
Students will be required to sign Non-Disclosure Agreements and to sign over IP to Sponsor when team is formed.
Interested in building a new strategy game concept to teach power engineering to High School & Middle School STEM students, as well as summer camps around Wake County? The FREEDM Systems Center at NC State is sponsoring the Smart Grid Video Game project in order to improve awareness and attitudes toward power engineering through 4X strategic gameplay. Taking inspiration from proven games in turn-based, 4X strategy like Civilization VI, Cities Skylines. Using open-source game engines like Unity, artwork software like Aseprite, & sound tools, we believe it is possible to quickly prototype a highly engaging game about power engineering.
Concept
The player will play as the CEO of their very own power company, starting from the mid-19th Century as they operate coal plants all the way until today. The player shall solve the fundamental engineering challenges of siting their power plants such that they produce the most power for the least amount of money, balancing generation with load in pseudo-real time order to supply a customer demands. This game will play out in a turn-based setting, ideally against competing AI-controlled companies.
Procedurally Generated Maps
Game maps will include a hexagonal tile system with distinctive appearances per region. This map can be 2D or 3D, depending on the complexity of making a sprite-based system vs. a space-based one. This map should be simple, attractive, and provide a nice home for the player’s assets & customers. The size of these tiles relative to the real world & the size of the game map shall be left up to the design team.
Maps can contain terrain features like forests, mountains, oceans, and rivers, which can provide buffs or obstacles to players that can be programmed later in the development cycle. The procedural map generation takes inspiration from Civilization VI, although a very simplified version is desirable.
Turn Structure
During the player’s turn, they shall have several decisions to make:
- How to dispatch their generators
- Buying fuel for their generators
- Purchasing or building assets (generators & power lines), paying connecting costs for loads.
This simple turn structure would be appropriate for making the game easy to learn and play. The turn-based gameplay makes it easy to manage a company spread over a large geographical region, and allows the player time to optimize their decisions. In comparison to a real-time game, a turn-based game focuses less on real-time grid operations and more on the experiences of system planning and running the power company.
Assets
For an initial prototype, the player will have 2 types of assets:
- Generators, which the player will site on the game map, and are managed individually or as a fleet, depending on what the player is doing(upgrading vs. dispatching power).
- Power Lines, which connect generators & loads to the player’s grid network.
Generators can have several different types, fuel sources, power ratings, operating costs, and ramp rates. Smart Grid is meant to be educational, and as such the generators will reflect their real-world counterparts. A brief summary is as follows:
- Natural Gas: NG generators are very effective “load toppers,” able to handle very rapid and dynamic power changes. They have a very high ramp rate, and usually a high maximum power output. In the 2000s & 2010s, advances in hydraulic fracturing have made it a viable base load option. NG produces fewer GHGs than coal and other fossil fuels. Natural gas play strategies can be either centralized sources farther away from the loads, or smaller generators that are closer to loads, which can save on infrastructure costs.
- Coal: A staple of the industry since it began, coal plants are massive sources specializing in supplying large base loads. Coal is cheap and plentiful, although is among the dirtiest fuel sources. A strategy around using col to supply large loads would typically center around building large centralized plants and a sprawling power grid connecting large cities & industrial centers, with a few topper generators to handle peaking loads.
- Solar & Wind: The renewables in this game can be distinguished by their negligent fuel cost. These generators are very weather dependent, and as such are intermittent. Battery storage is a means to smooth output of these generators. Both of these generator sources require a large land area, with wind having the highest energy sprawl of any generation source. Wind has an advantage in building offshore turbines & producing power at night, and solar PV usually has a low capital cost. Wind generators are stronger in regions with lots of wind, whereas solar is better in sunnier areas. Strategies using solar and wind would typically favor distributed resources close to their loads, building lots of generators in highly desirable weather areas, and investing a lot in real estate acquisition.
- Nuclear: Nuclear has the highest volume of power generation among any source, as well as a very low pollution output. However, due to the highly regulated nature of nuclear energy, nuclear is extremely cost prohibitive and time consuming in games where nuclear is regulated. Nuclear fuel is cheap and abundant, although the thermodynamics of plants make them limited in their ramping capability. Nuclear strategies would be similar to coal, with nuclear’s distinctive advantage in volume and fuel and coal’s advantage in construction time and capital cost create tradeoffs for the player to consider.
- Hydro: Built along rivers, hydro provided large volumes of power back in the early days of power engineering. Nowadays hydro produces far less power, although it is still a competitor in highly rivered areas. Hydro features pumped storage, which can ramp very quickly to handle peaking loads. It is also environmentally friendly in terms of pollution output, although it affects watersheds and can flood habitats in ways that can’t be overlooked. Hydro players will stick to rivers with high head, and stick to centralized sources.
Loads
In the game, the player will need to connect their generators to supply dynamic loads by matching a generation profile of their fleet with the load profile of their grid. These loads will consume different amounts of power depending on the time of day. In the real world, loads can be defined by statistics like customer satisfaction, system fault rates, $ per kWh, peak load & base load. There are also qualitative descriptions, such as residential loads, commercial loads, industrial loads, & power quality-sensitive loads. Loads can be a public city or private enterprise. In addition, loads can be impacted by local policies.
Loads will serve as a primary source of revenue for the player, paying a certain rate per kWh consumed. This revenue model will likely be a challenging aspect of the Smart Grid game, and as such will require more coordination with the Subject Matter Expert to make it work effectively.
Resource Markets
The player will need to purchase resources in order to fuel their generators. Three fueled generators will be playable in-game, including Coal, Nuclear, and Natural Gas. The resource markets for these fuels will model scarcity & increasing prices, and are heavily inspired by the board game “Power Grid”. While in power grid, the player’s turn order determined when the player will get resources, we will have a bidding system in which the player will submit a request for resources, and the game will distribute them according to a round-robin turn system on a turn-by-turn basis, with players rotating whoever gets the first resources at the lowest price. A system like this is meant to be simple & easy to program, as well as visually appealing.
Getting Started
Since you will only have one semester to complete a rapid prototype, it's important for you to have a good starting point and a clear direction for your project. Here are some tips to get started:
- Quickly adopt an agile development cycle like Scrum or Kanban. Create tickets in a software like Jira or Trello, & spend your meetings going over tickets to define their scope & blockers and closing. Take turns being sprint leaders, so that each team member will get a chance to lead the team through a sprint. Development sprints need to be done quickly, such that the team can accomplish more with their time and use it most effectively. Finally, all of your builds should go into the enterprise github set up for this game project.
- Establish what software to use. The sponsors recommend using open-source Unity, Unreal, or Coscos2D, and developing the game as a 2D 4X strategy game. Youtube tutorials for Unity can turn you into a full-fledged game developer in as little as one week. Sprite-based graphics are desirable, and game music & sfx are desirable but optional. Graphics, audio, & any other artwork should use open-licenses, or be created in-house. Paid licenses are not allowed unless they can be used for free for academic or non-commercial purposes.
- Quickly develop a base game together, and then separate into individualized roles. It would be great to start on the game map first together. Over the first month, a model of the load interacting with a generator could probably be developed in parallel with another major task. Everyone needs to be involved in the programming. The mentor will serve as the Subject Matter Expert for the game, and will provide material and instruction about power systems that is relevant for your game.
Background
Our research team at NCSU and Intel Corporation is developing decision support tools to help management understand the issues arising in capacity management during new product introductions. This project seeks to develop a prototype of a role-playing game where managers of different organizations involved in new product introductions can assess the impact of their own decisions on the performance of their organization, that of other organizations, and the firm as a whole.
Problem Statement
The two principal organizational units involved in new product introductions in high tech firms, such as semiconductor manufacturers, are the Manufacturing (MFG) unit and a number of Product Engineering (ENG) units. Each Product Engineering unit is charged with developing new products for a different market segment, such as microprocessors, memory, mobile etc. The Manufacturing unit receives demand forecasts from the Sales organization, and is charged with producing devices to meet demand in a timely manner. The primary constraint on the Manufacturing unit is limited production capacity; no more than a specified number of devices of all sorts can be manufactured in a given month. The Product Engineering units have limited development resources in the form of computing capability (for circuit simulation) and number of skilled engineers to carry out design work. Each of these constraints can, to a first approximation, be expressed as a limited number of hours of each resource available in a given month.
The Product Engineering groups design new products based on requests from their Sales group. The first phase of this process takes place in design space, beginning with transistor layout and culminating in full product simulation. The second phase, post-silicon validation, is initiated by a request to Manufacturing to build a number of hardware prototypes. Once Manufacturing delivers these prototypes, the Engineering group can begin testing. This usually results in bug detection and design repair, followed by a second request to Manufacturing for prototypes of the improved design. Two cycles of prototype testing, bug detection and design repair are usually enough to initiate high-volume production of the new product. Some complex products, or those containing new technology, may require more than two cycles.
The Manufacturing and Product Engineering groups are thus mutually dependent. Capacity allocated by Manufacturing to prototypes for the Product Engineering groups consumes capacity that could be used for revenue-generating products, reducing short-term revenue. On the other hand, if the development of new products is delayed by lack of access to capacity for prototype fabrication, new products will not complete development on time, leaving the firm without saleable products and vulnerable to competition.
The Product
We seek the development of an educational computer game where students assume the roles of MFG or ENG managers to make resource allocation decisions. The initial module of the game would focus on a single MFG and ENG units. Resource allocation decisions will be made manually, giving the players of the game a feel for the unanticipated effects of seemingly obvious decisions.
The Project
During the Spring 2019 semester, a Senior Design team (Callis, Callis, Davis & Deaton) developed an initial implementation of this game designed as a turn-based web-based game with a user interface allowing each player to:
- See the state of their own progress
- Communicate with other players
- Record the history of each player in a database
- A ‘spectator” user who can observe the state of all players.
This environment successfully allows a basic level of play, which we would now like to enhance in the following directions:
- Configurable parameters: The current version of the game has hard-coded system parameters, such as the level of resources available to each player, the external demand for the different products, and the amount of each resource required to move a project to completion at the different stages of its development. The system needs to be extended such that different game configurations, representing different industrial environments, can be read from a database. The game should either select a configuration randomly, or allow the spectator user to select the configuration to be used.
- UI to configure and generate parameters: To build upon this capability to read system configurations, we would like to build a library of configuration generators that given a subset of the parameters can randomly generate configurations with a desired structure. Some initial examples of this are available in our research papers which we will be glad to share, along with some others from the relevant literature.
- Dynamic gameplay: We would like to incorporate uncertainty into several dimensions of the game. These aspects would include, at a minimum, the amount and timing of market demand for the different products the firm manufactures; the amount of resources (engineering and manufacturing capacity) needed to move a product to the next stage of development; and the number of resources available to a player at any time.
- Improve playtrace logging: We would like to enhance the capability of the game to record the course of play in a database that can then be mined to extract successful strategies that can be employed by the players, or to restart the game from a particular state of play.
- AI players: We would like to have the capability to replace one or more players with an algorithm or optimization model that can read the state of play, along with predictions of demand and system state for some specified number of future periods, and return a set of decisions for the player which can then be executed and presented to other players.
- Game and UI improvements: We would like to enhance the user interface so that each player has access to their own history of play as well as forecasts of future events, to an extent specified in the configuration file. This will also entail organizing the interface so the players can see different views of their own situation, and perhaps limited information on the state of other players.
About LexisNexis
LexisNexis® InterAction® is a flexible and uniquely-designed CRM platform that drives business development, marketing and increased client satisfaction for legal and professional services firms.
Background
Not every action has an equal value. Timing is critical.
Tabbi is a partner of a nationally relevant law firm. She heads a practice group known for their work in intellectual property. With a challenging workload, she always aims to leverage technology to make the best use of her time.
Besides leading litigation, she needs to ensure that her relationships with prior and prospective clients are maintained. This is how business growth opportunities are developed.
Knowing which relationships would benefit from action to maintain their relevance and value is key to her using her time optimally.
By providing Tabbi with a daily actionable list of those clients that have fallen off her radar, seamlessly integrated into her email workflow, she can schedule a meeting or a call with a single click, reinforcing that client relationship.
Project Description
We will provide a test instance of our InterAction® GraphQL API (secured by OIDC; credentials will also be provided), that provides access to an example customer database together with historical activity records, including details of phone calls, meetings etc.
By examining these activity data, the system will identify customer relationships that require attention. The user will be notified when relationship activity falls below a healthy level via daily Actionable Messages (aka Adaptive Cards), leveraging the Office 365 email workflow, allowing the user to initiate new actions to help improve the relationship health.
The system will determine what a healthy activity level should be by mining historical data. A subjective, empirical formula for activity health exists, but students are expected to explore a Machine Learning approach to algorithmically derive this threshold.
Data Sources
- LexisNexis InterAction® GraphQL API
- LexisNexis provided historical activity data
- Generated data sets.
Technology
The team may choose their technology stack with any mix of Javascript, Python, and C#. The Actionable Message technology is from Microsoft; they have extensive documentation and a designer the team should leverage.
PRA Health Sciences provides innovative drug development solutions across all phases and therapeutic areas. But innovation just for the sake of innovation isn’t why we do it. Side by side with our clients, we strive to move drug discovery forward, to help them develop life-saving and life-improving drugs. We help change people’s lives for the better every day. It’s who we are. Innovating to help people is at the heart of our process, but it’s even more than that. It’s also our privilege.
PRA Health Sciences has been enhancing its cyber security program and would like NC State students’ assistance building a honeypot technology to help identify adversaries in restricted networks as they begin probing the network for vulnerabilities.
Honeypots are systems that behave like production systems but have less attack surface, less resource requirements, and are designed to capture information about how potential attackers interact with it. Their intent is to trick an adversary with network access to believe that they are a real system with potentially valuable information on it. The adversary’s effort to break into the honeypot can reveal a lot of information about the adversary and enable defenders to detect and gain an advantage on this threat.
In this project, students will create low-Interaction production honeypots, which can be configured and deployed easily, remaining cost effective in large numbers. There are two parts to this project: 1) a central management system to configure, deploy, and track honeypots and their data, and 2) the honeypots themselves, who will report back to the management console with their status and attacker interaction data.
Central Management System
The central management system provides a way to monitor and control honeypots and serves as a central repository of data collected by each honeypot it controls. Users should be able to view, modify, and create honeypot configurations. Students are encouraged to leverage existing technologies, such as Modern Honey Network. This system needs to be able to deploy honeypots on virtual hosts using all kinds of virtualization technologies and support a wide variety of hardware such as normal PCs, Arduino Boards or Raspberry Pis.
Honeypots
The initial configuration of a honeypot will consist of an Nmap scan of another system that the honeypot must attempt to replicate. With this input, the honeypot should configure its simulated services so that an Nmap scan to the honeypot produces no detectable differences, while having as little attack surface as possible. Additional configuration options will allow:
- Activation/de-activation of port/protocol simulation on a per port/protocol basis
- Configuration of the following variables: IP address, hostname, MAC
- Export/save a honeypot’s configuration to be used on a separate honeypot.
- Stretch Goal: Introduce custom variables (e.g. software version numbers)
To be effective, a honeypot must allow connections and simulate protocols from different layers:
- Fully participate in layer 1-3 traffic to appear as normal network device
- Engage in TCP, UDP and ICMP traffic and replay previously recorded payload
- Stretch Goal: Ability to obtain DHCP configuration
- Stretch Goal: Engage in commonly used encrypted protocols that Nmap supports, such as TLS
Each honeypot is expected to have data collection capabilities to be able to detect when it’s scanned or connected to and report the follow information to the central management system or SIEM:
- Timestamps, ports and protocols, and IPs.
- Other valuable information depending on situation (e.g. MAC address, hostname).
- The honeypots need to offer a configuration to record all or selected traffic received as pcap (packet capture).
- Stretch Goal: Detect the type of attack or configuration of scan (given known attack types).
To test the successful configuration of a honeypot, Nmap scans with varying configurations of both the honeypot and the original system can be compared. To aid in testing and reduce false positives, the honeypots need to be able to “whitelist” traffic or IP addresses. As a stretch goal, a single honeypot should be able to acquire more than one configuration and network address to simulate multiple systems at the same time using the same hardware/virtual machine.
Additional Requests
Modern Honey Network is the preferred central management system and Python the preferred development language. Students should use best practices for the development of secure software and document in great detail. Student should also strive to design honeypots to be modular so that additional protocols can be introduced, and additional functionality can be created, e.g. RDP, SSH, SMB Honeypots, Honey Websites and active beaconing. This Project is intended to be released as an open source project on GitHub and continued after the team has finished.
PRA Health Sciences will provide:
- Nmap scan result and configuration
- PCAP of Nmap scan
- ISO of original system for comparison/testing
Students will be required to sign over IP to Sponsor when team is formed
Deep learning has revolutionized the field of computer vision, with new algorithm advancements constantly pushing the state-of-the-art further and further. The fuel for these algorithms is data, and more specifically data for which the ground-truth reality is known and specified. In the case of computer vision applications, this means having images available which are classified (classification), in which object locations are identified and labeled (object detection), or even in which each pixel is assigned to a specific object (instance segmentation). Annotating images with labels is tedious and quite time consuming, but having a good tool can facilitate the process.
The goal of this project is to design and develop a modular, web-based, interactive tool for annotating data instances (images) so that they can be used for training deep learning models. The specific focus will be annotation of images used to train models for computer vision applications, but the design should account for future extension to annotating text and audio data as well. With the ultimate objective being to significantly improve the ease and speed of annotation, this project should incorporate usability features with deep learning models that can augment the annotation process by suggesting bounding boxes. An addendum will be provided to the formed team working on this project.
Objectives
To provide a good understanding of the desired tool, students should spend some initial time researching the capabilities of other image annotation tools, including RectLabel (https://rectlabel.com/), Supervisely (https://supervise.ly/), and Intel's CVAT (https://github.com/opencv/cvat).
The implemented tool will enable the user to:
- load an image from the folder that the user specifies
- present the image and provide tools for graphically interacting with the image
- perform image classification labeling/multi-labeling and save the label
- perform object detection labeling (bounding box) and save the labels (Note: Any models required for this, and a platform for invoking them, will be made accessible to the students early in the project.)
- save the user's choice after the tool is suggesting a label
- automatically load the next image in the selected folder when the annotation of the current image is completed and saved
Stretch goals:
- perform instance segmentation labeling and save the labels
- incorporate SAS Deep Learning models to make suggestions while the user is labeling
In addition to the items above, the labeling time must be calculated for each task.
If time permits, students should perform studies comparing the time to perform labeling of a certain number of images (e.g. 100) with those of the other tools researched. Possible reasons for being better or worse compared to the other tools should be discussed in a report.
Overall, this project is a combination of (1) software engineering (e.g., use cases, stakeholders, design, frequent deployments, test driven development, robustness, etc.) and (2) data science (e.g., training an object detection model and use it to help for the annotation).
Related Knowledge
Familiarity with modern javascript frameworks is important to build an interactive Web-based system. Further, familiarity with supervised machine learning methods is beneficial to understand the content. Particularly, experience with deep learning methods to solve computer vision problems such as object detection is nice to have. Python will be used to invoke SAS Deep Learning models for suggested labels.
Dataset
The target users of this project are internal and external customers. However, the customer data usually are protected. Therefore, to measure the performance of this tool, the SAS Deep Learning Team will be providing a custom dataset that has no copyright issues so that the team can utilize it without any issues. The dataset will have roughly 10,000 images and the task will be object detection.
Bandwidth Inc. owns and operates a nationwide voice over IP network and offers APIs for voice, messaging, 9-1-1, and phone numbers. Bandwidth R&D is currently exploring emerging technologies in real-time communications using WebRTC coupled with our core services. Primary technologies include (but not limited to): WebRTC, AWS Lambda, Java, SIP, OpenVidu, React, and AWS Cognito.
This project provides an exciting opportunity to develop a best-in-class user experience for managing sessions on a real-time communications (RTC) platform. The platform APIs provide data about sessions, packet loss, jitter, and various network conditions as well as session and client state. We need a component-based web application that consumes these APIs and displays session information in both high-level and detailed views. Early in the semester, we will provide a more complete requirements document and a working example of a similar web application, but in a nutshell the major components/features will be:
- Secure Login & Role-Based Permissions
- Users need to be authenticated and authorized to perform specific actions using AWS Cognito.
- Active Session Grid/List
- Ability to search and sort a list of active sessions.
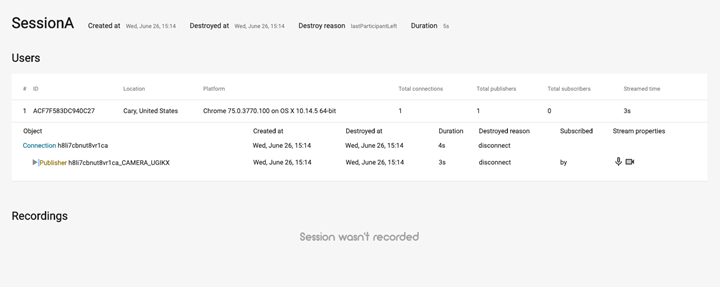
- Ability to drill down into a session object to inspect session properties.
- Ability to execute various session API calls allowed by the user’s role.
- Ability to list recordings or transcriptions associated with a session.
- Active Session Graph
- A graphical view of a session (see example below) that shows client connections.
- Elements of the Session Graph should be clickable to drill down into client/session properties.
- Session History Grid/List
- Ability for user to mine expired session logs.
- Ability to apply machine learning or predictive analytics to forecast platform behavior.
- Ability to generate meaningful graphs and analytics from historical data.
- Configuration Panel
- Ability for admin role user to change system configurations via configuration APIs.
Example 1 - Session Graph UI
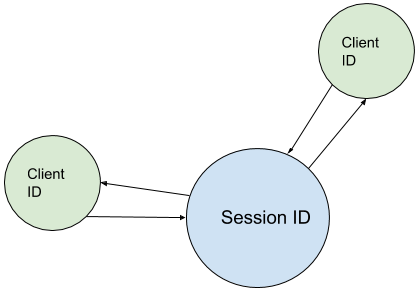
Example 2 - Session List/Grid
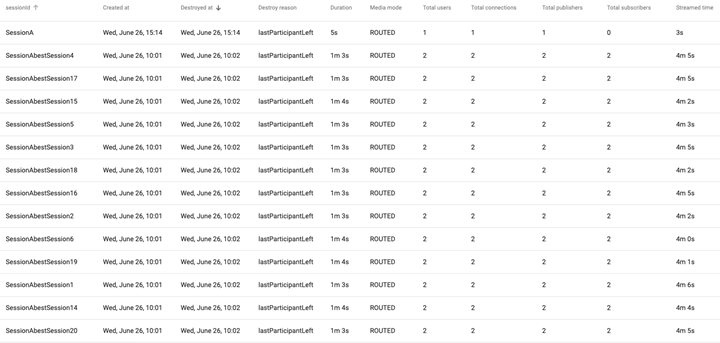
Example 3 - Drill Down
Project Goal
The goal of this project is to detect lateral phishing attacks. A normal
phishing attack occurs when an external attacker tries to get a target's
credentials by sending them an email that attempts to get the target to
click on a link that contains malware. In contrast, in lateral phishing
the attacker already has access to the credentials of an employee of the
target organization. In this case they are leveraging their access to
perform phishing attacks within the target organization to gain additional
credentials. As with normal phishing, the degree of sophistication and
targeting varies, from wide email blasts to very targeted spear-phishing.
The team will develop an approach to detecting lateral phishing attacks.
Previous work in this area has used supervised learning approaches
(specifically, a random forest classifier). In this case, we will focus
on a combination of detecting unusual activity from individual users based
on a social network graph, along with an analysis of the content of the
email itself. That is, the team will develop social network graphs that
represent user interactions based on email communication. Thus an email
that is addressed to a target that is outside the user's social network
would be anomalous. Similarly, if a user sends email to a group of
people who are not normally grouped together (e.g., that represent two
different projects or two different parts of the organization), then this
should be flagged as anomalous. From the email content perspective, the
features of interest would include that there is a link provided in the
email and the reputation of the target domain (e.g., cnn.com versus
xfwer8uiydf.org) of the link. The algorithms should be easily extensible
to include new data and features (e.g., user roles).
Public datasets will be used for developing and testing the approach. More
specifically, we will leverage the Enron data set at:
https://www.cs.cmu.edu/~./enron/
This dataset does not contain any lateral attacks, and so the team will need
to hypothesize some lateral attacks and inject those into the dataset to use
for training and testing the algorithm. The dataset will be divided into
two subsets - one for training and one for testing. Two types of testing
will be performed: (1) testing the performance of the algorithm in terms of
detection capabilities, and (2) testing the robustness of the algorithm. In
this latter case, we will inject errors in the testing dataset (e.g., malformed
header information) to ensure that the algorithm handles these gracefully.
The output from the algorithm should identify any accounts that appear to
perform a lateral phishing attack, along with an explanation for why that
account was flagged (where possible). The output should be provided as a
dashboard that includes other summary statistics (e.g., number of emails
processed, number of unique senders, average number of recipients per email)
In addition to the classification performance for detecting lateral phishing,
the team will also need to consider the scale at which the final classifier
will need to perform, ensuring that any developed algorithms are sufficienty
fast and lightweight.
The development environment will include Python3, Jupyter Notebooks, Anaconda
(scikit-learn, tensor-flow, etc.)
The following provides a high-level overview of the project steps, which will
be refined during project scoping with the team.
Understand project background
- Read papers and articles on lateral phishing
- Read any other related work (e.g., business email compromise)
Prepare data source
- Become familiar with the Enron dataset
- Hyptohesize lateral phishing attack scenarios
- Develop a library of lateral phishing attacks that can be injected into
the Enron dataset - Develop a library of emails containing other errors (e.g., malformed
headers, special characters) that can be injected into the Enron dataset
Train and test the algorithm
- Implement the algorithms and train them using the Enron data
- Potentially modify algorithms to include additional data or approaches
as determined during team meetings - Test the trained models to determine how well they generalize to unseen
data and present the results using precision, recall, and F1
Present results
- Develop a dashboard to present summary statistics and any suspected
lateral phishing - Identify weaknesses in the approaches (e.g., number of emails required
per account to train, concept drift) - Make suggestions for how to improve the detection performance
- Discuss performance in terms of CPU requirements and how the algorithm
scales (e.g., using big-O notation)
Stretch Goals
Once a classifier has been developed to process data as a one-time action,
the stretch goal would be to convert this to a version that runs continuously,
analyzing email as it is received.
Additional Information
Recent academic papers in this space include
- https://www.usenix.org/conference/usenixsecurity19/presentation/ho
- https://www.usenix.org/conference/usenixsecurity19/presentation/cidon
- https://hugogascon.com/publications/gascon_raid2018.pdf
Objective
While mental health awareness is increasing, there is still a stigma associated for individuals who seek help. Traditional options for treating mental health conditions are expensive and possess a large barrier to entry, particularly for younger generations. Blue Cross NC sees an opportunity to change the way mental health is approached by bringing awareness and treatment through an easy and accessible medium. We at Blue Cross NC want to partner with North Carolina State University to develop a mobile app to change the way mental health awareness and treatment is provided.
Solution
Develop a cross-platform mobile app to bring awareness and strategies to improve mental health. The app must be easy to use for young adults (the initial target audience). Features the app can include are:
Expected Features:
- Anonymity (username_based accounts)
- Communities for support of various mental health conditions (anxiety, depression, adhd, etc.) with resources around methodology and techniques to combat that type of disorder
- Training on mental health first aid (https://www.mentalhealthfirstaid.org/)
- A peer to peer interface – peers interacting in an open forum, direct messaging not an expected feature
Stretch Goals:
- A web-interface in addition to the mobile app
Blue Cross NC welcomes and encourages feedback from students during all phases of development to positively impact as many people as possible!
Learning
The team will strengthen their technical and soft skills during this project. Students will utilize their skills in programming languages / UI expertise to develop the raw framework of a cross platform app. This group will also get the opportunity to develop their soft skills as they will need to be peer facing and collaborative with many different parties as they partake in build-measure-learn feedback loops.
Project Outline
Gather user requirements and understand what the college aged consumers of a mental health application would want to see.
Build a cross platform app framework to begin testing user requirements and monitoring actionable metrics.
The Company
Burlington Carpet One has been owned and operated by the same family since 1972. We are a full-service flooring company catering to retail customers, contractors, commercial companies, and realtors. Currently under the guidance of our second generation, we have joined the Carpet One Co-Op (CCA Global), the largest co-op in the world, comprised of over 1000 like-minded flooring store owners, committed to positively impacting the flooring industry as well as our local communities. Unlike the majority of flooring companies, we employ in-house flooring technicians, not subcontractors.
Background (perceived problem)
While many industries have access to text/email and schedule-based customer communication/scheduling platforms, i.e: physicians, dentists and hair stylists - the flooring industry is lacking in this arena. While we are currently using a scheduling dashboard by “FullSlate ”, it only addresses approximately 50% of the features needed by our industry. A web-based application specifically for the flooring industry would facilitate maintaining a scheduling dashboard also equipped to communicate scheduling dates to customers with multiple precursory reminders, as well as follow up maintenance reminders. All communication will be delivered via email and/or texts, based on customer preference. In addition, each scheduled block should allow for the assignment of an installation in-house, or sub-contractor, technician, as well as flooring material assignments and retail sales associate assignments. It is important that the dashboard accommodate several functions:
- Schedule customer installation dates
- Send schedule reminders/follow up maintenance reminders
- Send on the way messaging
- Assign an installation technician/crew
- Assign a flooring type
- Assign a sales associate
Solution
Design & build a web based dashboard to maintain an installation schedule similar to below:
Each time slot should have the ability to book multiple installations, not just one (the problem with current dashboard options). Multiple crews will begin their day in the 8 am time slot. Some jobs last an entire day, some do not. Some crews may have 1-3 assignments daily – while most will only have one daily.
Each entry will need to connect with a database of installation technicians, both in-house and sub-contractors (from drop down menu).
Each entry will need to connect with a database of retail sales associates (RSA) (from drop down menu)
Each entry will need to connect to a flooring category: LVP, LVT, Ceramic, Carpet, Engineered Hardwood, Solid Hardwood, Sand & Finish, etc. (from drop down menu),
Each scheduled time slot should notify the customer of the scheduled installation date using preset templates (email/text ).
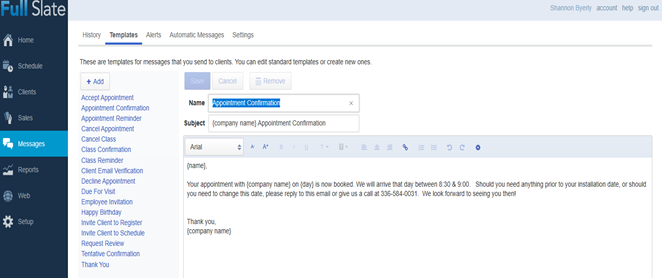
Preset templates through automatic messages will be set for 1 week prior as well as 1 day prior to the installation, which will be associated with each customer and time slot
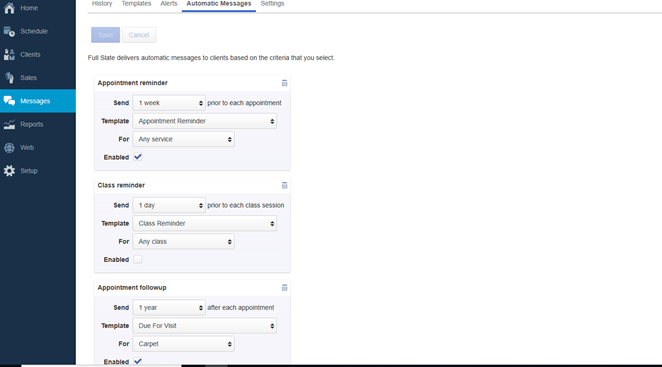
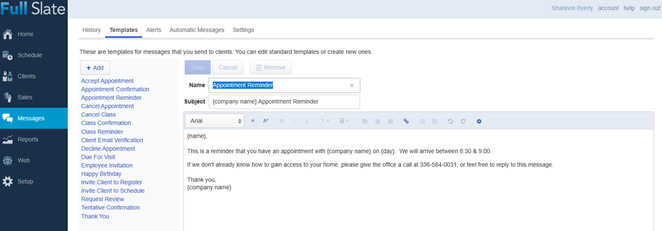
The day of installation should have an easy to use OTW (on the way) message option, notifying the customer that their crew is on the way, along with a photo of the assigned installation technician.
A preset template should follow the completed installation and request a company review by being directed to grade.us (online review platform)
Optional
Allow for multiple location coordination using separate or shared staff/calendars.
Allow for synching with Quick Books & RFMS accounting software eliminating double entry of customer information.
Calendar should offer viewing by different screen options: 1) customer calendar 2) installation calendar 3) RSA calendar.
Recommended Student Skills
Web design experience would be helpful . Students are free to use any appropriate technologies to build this system.
Students will be required to sign over IP to Sponsor when team is formed.
Background
NTP is a widely used protocol that provides time synchronization for endpoints worldwide. NTP implementations have suffered from weak security and various implementation flaws for a long time. The IETF is standardizing two new options for symmetric (draft-ietf-ntp-mac) and asymmetric (draft-ietf-ntp-using-nts-for-ntp) authentication of NTP. These drafts, when standardized, aim to address many of the security concerns and drawbacks that existed in older NTP authentication methods.
The drafts are implemented by major open-source vendors that provide NTP implementations. Cisco specifically funded open-source project NTPsec to accelerate the faster implementation of these standards and plans to use these implementations in its products and offerings. It is something that our customers expect, so products need to provide.
Description
For this project, we want to integrate and test the NTPsec implementation of these two new standards. Students will need to read the NTPv4 protocol and these two standards so that they can make use of their implementation by NTPsec. The NTPsec implementation would need to be tested and its compliance with draft-ietf-ntp-mac and draft-ietf-ntp-using-nts-for-ntp needs to be verified.
The students are expected to first design and deploy an infrastructure for testing their code. That infrastructure will include:
- Two NTS servers. One of them will be an NTP / NTS-KE server running in AWS or Google Cloud (If necessary, Cisco will cover the expenses for a simple host in AWS or Google Cloud). Let's Encrypt certificates would need to be used for that server. The other server will be Cloudflare's time.cloudflare.com:1234.
- Three NTS clients from NTPsec. A C client (Client1) that has the AWS or Google Cloud server configured as its NTS server and Client2 as its peer. A Python client (Client2) that has Client 1 as its peer. A Python client (Client 3) that has both servers configured as its NTS servers.
Students are expected to make use of this infrastructure to ensure that all three clients are synching time with the servers configured and their peers. They need to confirm that NTS authentication works and see clock convergence and collect statistics.
Students will also have to design and implement two configurable “wrapper” programs that make use of the library to demonstrate how someone would integrate a client and server with it. The programs do not have to be written in C. They could be written in Python or any other common language. They will be a client and a server that allow for command configurable options, like role (client, server), authentication type, size of the keys etc. For example, we would run command ‘nts-wrapper-client nts_server xyz’ to configure the NTS server in the ntpd configuration file and restart the service. The server wrapper program should run in the AWS or Google Cloud server and the client wrapper program should run in Client1. Both programs should be shown to configure the service correctly and demonstrate that clocks are synchronizing. Students are also expected to identify the applicable library configuration lines that adopters of the library would make use of to integrate in their code.
Required Student Skills
Students must have
- Some experience in C programming, Python and Linux.
- familiarity with git and github.
- taken at least one course in security.
- some familiarity cryptography and the TLS protocol.
motivation to work on an interesting topic and an opportunity to make an impact.
Motivation
Students will be able to work on a practical industry problem. Security is a hot topic today and NTP is a fundamental protocol for the operation of the Internet. Students will have a chance to see how important protocol security is and what practical industry problems it can create. They will also get a chance to contribute back to a very useful library used in almost every operating system and vendor product.
Cisco has been looking into secure NTP for some time. We want to ensure that our products and offerings can make use of the NTPsec implementation to secure how they synchronize time. It is something that our customers expect and products need to provide.
Deliverables
- The design and deployment of the AWS or Google Cloud server and the 3 clients.
- A guide that includes:
- A summary of the standards and the message workflows. That includes a description of common architectures of how the NTS standard would be deployed, for example NTS-KE server co-existing with NTS server or separate and limitations of the NTS protocol.
- Documentation of the process to build and configure the AWS or Google Cloud server and Client1, Client2 and Client3. Also documentation of common issues faced when configuring and installing the libraries.
- The configurable client and server wrapper programs.
- A developer’s guide with the wrapper programs available command options and all the applicable ntpd library configuration lines that adopters of the library would make use of to integrate in their code.
Background
Across different organizations in Fidelity on certain nights, many teams will come together to release new features into a Production environment for customers. There is a central team that is responsible for the coordination (Ops) and then other teams that are responsible for ensuring that, as the install is in progress at different stages, the applications or services that they own are validated/certified and signed off on. During this night you could have upwards of 100 teams that are introducing new features and needing to certify their features as part of the install.
At the moment, this coordination for specific groupings of teams is done via a chat room, spreadsheets, telephone, and email for a specific grouping of teams, which makes it extremely tedious to maintain. Furthermore, it becomes the sole responsibility of a few that lead their groupings of teams to make sure and request status updates for sign off of the applications. This manual process is not ideal and takes away from the few individuals monitoring for their group.
Potential Solution
It would be useful for the various teams to have a dashboard that serves as a central location for all the teams in order to communicate during and around the production release. Furthermore, as folks may need to look back on prior installs, having an audit of the events from the install and essentially a history of the dashboard from prior months would be helpful.
At a high level a platform could have an admin page and a general user page. These pages would allow users of different roles to view the stages that are open for validation and sign off validation for their respective team. This would create a much more manageable way to verify sign off from the teams and potentially even allow for auditing in the future.
Personas
- Ops Engineer – An Ops Engineer is someone who will use the dashboard in order to establish the install night coordination, the active stage for the install during the night phase, and overall the person who has the most access in order to make sure everything gets handled and completed.
- Team Member – A team member is part of a team that is installing changes for the install and needs to be sure to validate in each stage their release. Additionally, they will need to know what phase or stage the install is at.
- View Only User – Is a person who may or may not be logged in that only has view access to the page. They are not allowed to perform any update functions, but they are allowed to see the status.
Technologies
The vision is a web-based application that would allow many different people to access the site in order to work together in filling out, updating the necessary information that is needed for communicating the Install plan. These technologies are also specifically chosen as it is most common to what Digital Platforms developers use today and would lead to a good transition for enhancements in the future.
The system mentions an authentication and authorization system based on different types of users; for the purposes of this project we would like that capability stubbed out (simple is fine here) and done in a plug and play way so that when the project is handed over, we can incorporate the Fidelity authorization system.
For information about what teams are installing for a given release, Fidelity has a system already in place that exposes an API for this data. What we would like to do is have the NCSU team take the contract and stub this data out for their prototype so that it later can also be incorporated on the hand over.
API Layer
- Java 8 or higher
- Tomcat 8.5 or higher
- Spring boot 2.1 or higher (Optional)
- JSON Response Structure/REST
- Open API 2/3, Swagger (Optional)
Database Layer
- Must be a relational database (i.e. no NoSQL)
- You choose the vendor (e.g. MySQL, Postgres, etc.) but be prepared to tell us why you chose it
Experience Layer
- Angular 8
- HTML5
- CSS3/SASS
How Will this Help Users?
Having a common platform that will allow users to be able to understand and communicate the accurate status of where we are in the install/release night process will ensure that we take steps to reducing a tedious manual process for folks and allow for more folks to use chat to focus on the current issues and how we can tackle them during the night.
Project Collaboration
- Use Agile for software development
- Form a Scrum team and have 2 week sprints
- Weekly meeting with Sponsors to review the progress and help answer questions related to requirements
Additional Information and Use Cases will be provided once team is formed.
About Microsoft
For more than 40 years Microsoft has been a world leader in software solutions, driven by the goal of empowering every person and organization to achieve more. They are a world leader in open-source contributions and, despite being one of the most valuable companies in the world, have made philanthropy a cornerstone of their corporate culture.
While primarily known for their software products, Microsoft has delved more and more into hardware development over the years with the release of the Xbox game consoles, HoloLens, Surface Books and laptops, and Azure cloud platform. They are currently undertaking the development of the world’s only scalable quantum computing solution. This revolutionary technology will allow the computation of problems that would take a lifetime to solve on todays most advanced computers, allowing people to find answers to scientific questions previously thought unanswerable.
Description/Goal
SystemVerilog is a hardware description and hardware verification language used to model, design, simulate, test and implement electronic systems. Currently, there exists some extensions for Visual Studio code to support SystemVerilog entry. Of them, we've identified one that seems best, and would like to contribute to it and add features that would make it a compelling tool for all hardware engineers at Microsoft. The features to the extension will make it easier and more user-friendly to write/navigate SystemVerilog.
This project will allow students to gain experience in not only designing, coding, and testing the features added to this extension but also collaborating with resources on various teams and sharing the designs and tests of these features. The students on this project will work on multiple features that they will then bring together and ensure effective communication is taking place so that they can learn what the other is designing, coding, and testing.
The following Github Repository will be used throughout this project:
https://github.com/eirikpre/VSCode-SystemVerilog
Link to existing extension:
https://marketplace.visualstudio.com/items?itemName=eirikpre.systemverilog
The development team will be provided with details on the existing features, details on additional features being requested, and sample inputs to test features.
Features
- Lexing and parsing SystemVerilog grammar
- Build an external configuration tool
- Symbol/Variable tracing
- Syntax validation (variable/field reference checking)
- Back-end Language server for SystemVerilog – building language symbols
- Incremental compiles
- Tree view of module hierarchy
- IntelliSense support
- Long term, additional support for compiling and linting
Student Skills
- Compiler knowledge required
- Typescript and Javascript required to code extensions to Visual Studio Code
Background
StorageGRID is NetApp’s software-defined object storage solution for web applications and rich-content data repositories. It uses a distributed shared-nothing architecture, centered around the open-source Cassandra NoSQL database, to achieve massive scalability and geographic redundancy, while presenting a single global object namespace to all clients.
Supporting a scale-out distributed system like StorageGRID presents a unique set of challenges. If something goes wrong, the root cause analysis may require piecing together clues scattered amongst log files on dozens of individual nodes. Due to the complexity involved, a lot of information is recorded for every transaction, but this leads to an embarrassment of riches – often, identifying what information is relevant is the hardest part of solving a problem.
Indeed, one of the most common questions someone asks when reviewing reams of StorageGRID logs is, “Is this normal?”. Would I see this set of log messages occasionally on a healthy system, or are they unusual, and therefore possibly related to the problem I’m investigating?
In 2018 StorageGRID sponsored an NCSU Senior Design project that became known as “Logjam” – a log ingest, indexing, and analysis dashboard for StorageGRID based on ELK (elasticsearch/logstash/kibana). The primary goal of Logjam is to provide quick, evidence-based, statistical answers to “Is this normal?”
To do so, Logjam must derive value from a large set of unstructured data. NetApp’s 24x7 Technical Support team collects gigabytes of log files from many different NetApp products every day. This material goes into two NFS file shares (one in North America, the other in Europe), which today contain petabytes of historical log data. The only consistent organizational elements in this log repository are the top-level directories, which have names that match the “ticket numbers” of the customer cases that necessitated collecting the data underneath that directory. Descend into a numbered case directory, and you might find virtually anything.
This introduces the first problem Logjam needs to solve – separating useful data from junk, and applying structure to it to make it easier to work with. You have petabytes of data, loosely organized into thousands of numbered case directories, which is being updated constantly. A lot of this data is compressed or otherwise obfuscated – it is difficult to work with. Most of the cases relate to other NetApp products (not StorageGRID) – these cases should be ignored. However, there is no accurate way to tell from the case number whether StorageGRID data was collected – the only way to determine this is to look at some of the data.
Clearly there is a need to do a one-time full scan of the entire multi-petabyte repository looking for StorageGRID cases, but doing regular full scans is unlikely to result in acceptable performance. Instead, after the initial scan, Logjam should be able to keep itself current by doing incremental updates – finding and indexing files and directories that have changed since the last scan. This problem is not well-solved by the current Logjam implementation.
The second problem Logjam needs to solve is what structure to apply to the StorageGRID case data to make it easier to work with, specifically to help answer the question “is this normal”? This is a categorization and indexing problem, and to some extent a parsing problem. The current Logjam implementation includes a decent solution to this problem, but enhancements are certainly possible.
The third problem Logjam needs to solve is, how can average users, who are neither StorageGRID nor ElasticSearch experts, take full advantage of the cleaned and structured case data. One element of the solution here might be to literally add an “Is this normal?” button to the Kibana-based UI, allowing users to paste in the log they’re questioning, click the button, and get information on frequency, cross-references to case numbers, perhaps a visualization. This is a query formulation and UI / UX problem. The current Logjam implementation makes a good attempt at solving this problem, but would benefit from additional work.
The fourth problem Logjam needs to solve is, how can users get access to Logjam? StorageGRID has support engineers in Vancouver, RTP, Amsterdam, and various locations in Asia.
One centralized Logjam instance is unlikely to be the best solution from a performance or reliability perspective; instead, it should be easy to spin up Logjam instances on user-provided compute clusters, so the tool can be deployed close to where it’s being used. This is a DevOps problem. The current implementation makes an attempt at solving this problem, but there’s a lot of room for improvement.
Project Goals
- Design and implement a practical and performant solution for incremental batch updates of the log database. Given that the source log bundles are stored in multiple NFS file shares containing petabytes of historical log data, only a small fraction of which is relevant to StorageGRID, only a small fraction of that will typically have changed since the last batch update, no external information on what has changed is available, and the log bundles may contain recursively compressed content.
- Design and implement a mechanism for automated deployment of the Logjam application onto one or more servers (VM or bare metal) running Ubuntu 18.04.2 LTS (assume basic server install plus ssh). Ansible preferred; other orchestration frameworks negotiable.
- Add additional queries and visualizations to the Kibana UI, specific requirements to be determined as development progresses (assuming Agile development methodology)
Deliverables
- Logjam.next deployment package that we can spin up on Ubuntu 18.04.2 LTS clusters in our RTP and Vancouver offices, and perhaps elsewhere. The system should require minimal to no training to deploy and use, so the documentation requirements here are minor – a simple user guide should be sufficient. (the less documentation needed, the better; we’d rather the software take care of everything)
Development Environment
- On-premise or cloud-based Ubuntu 18.04.2 LTS cluster
- Exemplar log directory tree provided by NetApp
- Logjam deliverables from 2018 NCSU Senior Design project, including source, unit test, and documentation
Project Archives
| 2026 | Spring | Fall | |
| 2025 | Spring | Fall | |
| 2024 | Spring | Fall | |
| 2023 | Spring | Fall | |
| 2022 | Spring | Fall | |
| 2021 | Spring | Fall | |
| 2020 | Spring | Fall | |
| 2019 | Spring | Fall | |
| 2018 | Spring | Fall | |
| 2017 | Spring | Fall | |
| 2016 | Spring | Fall | |
| 2015 | Spring | Fall | |
| 2014 | Spring | Fall | |
| 2013 | Spring | Fall | |
| 2012 | Spring | Fall | |
| 2011 | Spring | Fall | |
| 2010 | Spring | Fall | |
| 2009 | Spring | Fall | |
| 2008 | Spring | Fall | |
| 2007 | Spring | Fall | Summer |
| 2006 | Spring | Fall | |
| 2005 | Spring | Fall | |
| 2004 | Spring | Fall | Summer |
| 2003 | Spring | Fall | |
| 2002 | Spring | Fall | |
| 2001 | Spring | Fall |