Projects – Spring 2023
Click on a project to read its description.
Sponsor Background
The Canine Instruction with Instrumented Gadgets Administering Rewards (CIIGAR) Lab at NCSU is among the world-leaders in Animal-Computer Interaction and Animal-Centered Computing research. Either directly or through a network of collaborations, the lab develops hardware and software that facilitates nonhuman animals interacting with, and via, computing systems. The Lab is among the top contributors to the annual Animal Computer Interaction conference, has 3-5 PhD students, and several undergraduate researchers during any given semester. Dr. David Roberts directs the lab.
Background and Problem Statement
Among the many challenges in facilitating nonhuman animal use of computing systems is the design of Animal Interface Devices (AID). AID, the equivalent of the keyboard, mouse, and screen for human computer users, are currently being investigated in many forms, including accelerometers, buttons, touch devices, strain gauges, and camera-based systems. The latter, camera-based systems, have notable advantages in terms of ergonomics and comfort for animals, but generally require advanced knowledge and implementation of computer vision techniques in order to convert raw pixels into meaningful interaction data. Many behavior and welfare researchers and practitioners deploy cameras in their work, but this advanced knowledge of computer vision is seldom available to those with interest in or knowledge of nonhuman animal behavior and welfare, creating a “have data, need help” scenario.
Project Description
The goals for this project are to build upon a proof of concept developed by a prior senior design team to enhance a self-service web portal that will enable behavior and welfare researchers and practitioners to upload camera data, re-train existing computer vision models, run inference using those models, and receive results. The system must allow:
- Users to create, share, and modify projects comprising data, models, and code.
- Storage of raw, processed, and inference data.
- Tracking of model provenance (including specific training data, hyperparameters, and performance data).
- Facilitate the execution of data preprocessing, model training, and inference using simple, non-technical controls, but also enable technically-focused users to author custom code.
- Storing, viewing, and visualizing results of training and inference.
The existing system has some baseline capabilities for all of these features, but is far from complete nor usable by non-technical users. The emphasis of this project will be to enhance the existing functionality and design some additional functionality.
- The existing system uses docker containers to execute processing pipelines. Currently containers are built on demand for every execution, leading to long-lead times. New functionality shall include 1) management of image building as distinct from execution, 2) integration with a local docker registry, and 3) support for dependencies other than pip packages (e.g., apt packages).
- The existing system supports uploading code, data, and python package requirements. New functionality shall include 1) integration with a web-based code editor (e.g., neovim) and 2) integration with github for managing code revisions.
- System configuration is currently handled primarily on the command line. New functionality for managing configurations directly in the web UI are required.
- Current functionality enables sharing processing pipeline definitions, but shared editing and execution management is limited. New functionality shall provide the ability to share data, code, and models independently, as well as share execution management and outputs.
- Current functionality for executing processing pipelines considers each step atomic, and results are only available upon completion of every step. New functionality shall enable parallel execution, fork and join, as well as real time log following, interruption of execution, and GPU affinity for containers executing GPU accelerated code.
Technologies and Other Constraints
- Django
- CSS
- Docker
- Celery
- Git
- Python
Sponsor Background
Dr. George Rouskas is the Computer Science Graduate Program Director at NC State. In this role, he coordinates the process for collecting faculty nominations for their students for external fellowships and award opportunities.
Background and Problem Statement
There are several opportunities throughout the year for faculty to nominate their students for external fellowships, awards, etc., and often we have to hold an internal selection process first. The current process involves sending an email to all faculty tailored to each opportunity, asking for nominations by an internal deadline which is often much earlier than, say, an external fellowship’s actual deadline. This process has worked OK, but emails are prone to be misplaced, and internal deadlines are missed resulting in late nominations of their students who may be well-qualified for the award/fellowship.
Project Description
A potential solution to make this process more robust and streamlined would be a web app that serves as a central point for listing all opportunities with associated info and deadlines and for uploading nominations. Specifically, the app should have these features:
- A list of common nomination opportunities, including Google/IBM/other Ph.D. fellowships and departmental/College awards, appropriately categorized
- An interface for updating the information (e.g., deadlines, links to information, etc.) and to add new opportunities (fellowships, awards) as they arise
- An interface for individual faculty to upload and update nominations for their students (i.e., individual faculty will be able to access only nominations they have submitted)
- An interface for the CSC Department Head, the awards committee, and DGP to view/download all nominations.
With such a web app, the nomination process will be streamlined. The DGP will continue sending faculty emails for each specific opportunity, but he will point to the web app. Also, faculty can log into the app early and nominate students well ahead of any internal or external deadline so that we will have the nomination even if they miss the DGP email.
Technologies and Other Constraints
The tool must be developed based on the LAMP (Linux, Apache, MySQL/MariaDB, PHP) stack that conforms to CSC IT web infrastructure standard. It must also incorporate Shibboleth authentication.
Sponsor Background
Diveplane’s mission is to make the understandable, ethical and privacy supporting AI/ML the standard approach. Diveplane Reactor is an entirely novel instance-based learning platform built entirely on information theory and probability theory that can tell exactly why every decision was made, all the way down to the data. A single model can do supervised, semisupervised, unsupervised, reinforcement, and online learning, generative and discriminative output, and predict or explain any aspect of the data. Reactor specializes on structured data with cutting edge accuracy, especially on small and sparse data sets.
Background and Problem Statement
The APIs for Reactor are currently built in and for Python. Though this covers most of our customers’ needs, some people have asked for the ability to use the R programming language for their data-science teams. As we plan to make Reactor widely available later in 2023, having support for the R programming language would help more people use it.
Project Description
Our current, Python-based software clients are relatively thin; the heavy machine learning computation is performed in the Diveplane Core, which is a binary shared-library compiled for the specific target machine’s architecture and operating system (Windows, Mac, and Linux are supported), so, our higher-level client software is a wrapper around this core.
We also offer a Kubernetes-based enterprise cloud solution which allows our customers to scale up machine learning operations across many users and to process larger data volumes. To access this capability, we have client-packages that interact with a REST API to send high-level requests to the Diveplane Platform and receive the response. We also have an OpenAPI specification for the interface, which may be used as a useful starting point for generating the base of the API.
The solution would consist of:
- A “direct” to core R client package that would work with locally available binaries.
- A “platform” R client package that would have an identical high-level interface to the aforementioned “direct” R client, but would use a remote Diveplane Platform to execute the requests and return a response, including authentication, error handling, and feedback to the user.
- Support libraries for client-side manipulation of customer datasets to prepare parameters for both direct and platform use.
- Unit tests for the R client.
- Proper documentation – the vast majority of the documentation can be transposed from the existing Python code
- A small, simple data set analysis in R using Reactor.
The resulting effort would bring Diveplane’s Understandable AI/ML capabilities to data scientists who use R around the world.
Technologies and Other Constraints
This project would require developers who are familiar with or willing to learn R and are at least capable of reading Python (for reference). The candidates should also be familiar with or willing to learn:
- R Package development
- Shared binary object (e.g., .so, .dll, .dylib) interfacing
- OpenAPI, REST APIs, and HTTP in general
- JSON
- YML
- JWT (for authentication/authorization flows)
It would be beneficial if the students had a heterogeneous mix of Windows, Linux, and Mac machines to make sure things work across all platforms, but it is not required as Diveplane can assist with nuances between platforms.
Students should use Jupyter Notebooks and other data science environments for testing the integrations.
This project will build on Diveplane’s proprietary software. Thus, it will be a requirement to use Diveplane’s software, which requires the students involved signing a free license agreement with Diveplane. The license will prohibit commercial use, has other appropriate limitations, and has confidentiality provisions.
In exchange for sponsorship, Diveplane will own the result of the project. Thus, the students must sign IP assignment agreements for the work created. No guarantees, but it is Diveplane’s plan to eventually open source and / or make freely available the results of the project.
Students will be required to sign over IP to, and sign a confidentiality agreement with, sponsors when the team is formed
Sponsor Background
Pinball Wizard is the working title of a pinball machine ecosystem envisioned by FreeFlow Networks, a startup led by CJ Saretto, an NCSU CSC Alumnus and Alumni Hall of Fame member. FreeFlow Networks was created by CJ to explore passion projects with commercial potential.
CJ has had a life-long interest in arcade format entertainment. CJ was captivated by pinball in the 1990s when titles from Bally / Midway were pushing the boundaries of electromechanical functionality and video game style narrative progression. Recent market resurgence of the pinball industry has re-ignited CJ’s passion in the space, and inspired him to imagine a modern app-based ecosystem around physical pinball tables.
Background and Problem Statement
Pinball is one of the few arcade game formats that remain a commercial success in the US. With the decline of US video arcades in the late 1990s, pinball receded to a cottage industry. However, recent market trends are transforming local craft breweries, tap rooms and bars into social gathering spaces with arcade format entertainment, many featuring new and vintage pinball machines. This trend sparked the industry, which is now producing a steady flow of new pinball titles from the likes of Stern and Jersey Jack. There are even at-home models being created for big-box retail by companies such as Arcade1up.
Despite the market resurgence, finding playable commercial machines requires local knowledge. Finding a title you want to play is even harder. Further, the online ecosystem we’ve come to expect around modern gaming entertainment is nearly non-existent.
FreeFlow networks seeks to stoke, and capitalize on, the revitalized pinball market by creating an app-based ecosystem around commercial pinball machines, known as Pinball Wizard. This ecosystem will benefit players by wrapping their physical play in the online competition and progression they have come to expect from at-home video games. Commercial operators will benefit from increased revenue per machine, as more players discover their games online and stay to play for longer.
Project Description
Pinball Wizard is conceptualized as an ecosystem with the following components:
- Pinball Machine Hardware Interfaces: Pinball Wizard expects to partner with a number of aftermarket pinball machine modification providers (ex: ColorDMD) to connect vintage tables to its cloud platform. Further, Pinball Wizard hopes to create partnerships with modern table manufacturers (ex: Stern Pinball) that are manufacturing new tables with out-of-the-box internet connectivity. Only tables with supported internet connectivity would be supported for advertisement on Pinball Wizard. All connected tables would support a simple QR-code style linking mechanism that connects a player’s physical game on the machine with their online player account, via the Player-Focused Mobile Application.
- Player-Focused Mobile Application: A native mobile application that provides an experience where players can find pinball machines available for commercial play near their physical location. Upon arrival, players can scan a pinball machine , linking the details of their play such as scores and in-game accomplishments with their online Pinball Wizard player account. As players discover and play machines, they rank in online leaderboards, receive achievements, and progress their player profiles. For players, the goal is an experience similar to Xbox Live or PlayStation Network.
- Operator-Focused Online Portal: An online website allows operators of commercial pinball machines to advertise their pinball machines with Pinball Wizard. Operators would register their specific locations of business, select which supported tables are present, post hours of operations and prices.
- Cloud Platform: A custom software service interconnecting and enabling the Pinball Wizard ecosystem experience. The Cloud Platform would be hosted on commodity public cloud infrastructure.
The scope for this semester’s project is limited to delivering a prototype of the Player-Focused Mobile Application connected to a barebones Cloud Platform. Exact scope and requirements will be discussed and agreed between the assembled Project Team and Project Sponsor during the requirements phase of the project.
Technologies and Other Constraints
The Project Sponsor is flexible with technologies to be utilized in the solution. In fact, Sponsor actively seeks input from Project Team on technologies most suited to purpose. That said, a few guardrails for technology selection are provided:
- All technologies should be well documented, open source, and have a sizable community of users and maintainers.
- Player-Focused Mobile Application is meant to be a native mobile application so that it can feature the smoothest possible player experience including custom QR-code scanning UI, push notifications, precise geo-location monitoring during use, and background application processing when the phone is locked. While these capabilities are not required for the prototype delivered by this project, they are desired over time. To limit scope of this prototype project, a single target mobile platform is preferred, specifically iOS, as iPhone now commands over half of the US cell phone market. Running under iPhone simulation vs physical hardware is acceptable.
- Cloud Platform should be deployable on commodity public cloud infrastructure from Amazon Web Services. To limit the scope of this prototype project, a stand-alone docker container running on NCSU provided infrastructure is acceptable. However, if students prefer to take advantage of cloud-specific services, sponsor will provide access to an AWS account with sufficient funding.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Katabasis is a non-profit organization that specializes in developing educational software for children ages 8-15. Our mission is to facilitate learning, inspire curiosity, and catalyze growth in every member of our community by building a digital learning ecosystem that adapts to the individual, fosters collaboration, and cultivates a mindset of growth and reflection.
Background and Problem Statement
AI-generated art from models like Dall-E from OpenAI and Stable Diffusion from StabilityAI are becoming not only increasingly accurate, but also entering the public eye, and becoming a topic of conversation on the evolution of art as a medium, and the ethical concerns on AI modeling and data permissions. These conversations will likely only continue and grow, and Katabasis is interested in preparing the next generation on the cores of these concepts.
Project Description
Katabasis is seeking to develop a graphical interface integrating AI-generated art technology to facilitate learning and interaction with middle to high school aged children. To this end, we want an interface that integrates with existing AI art models (specifically Stable Diffusion, due to its open-source nature), and presents a simplified and user-optimized experience to interact with the model and generate images. While there are some compelling existing interfaces (e.g., https://github.com/AUTOMATIC1111/stable-diffusion-webui), we are looking for an implementation that is accessible to non-technical users, and that leverages as many of the feature set of Stable Diffusion as possible. Furthermore, we want this interface to provide Computer Science oriented lessons but based around artistic examples and contexts. Here is a summary of the core features we are looking for:
- Stable Diffusion User-Friendly Interface: We want an interface designed to be accessible for non-technical users, and provide usability shortcuts including:
- Style Seeding: Allow selection and creation of ‘styles’ that integrate certain words and weights into a prompt behind the scenes.
- Algorithmic Bias Correction: Because of the nature of the training data used on the model, a lot of the images produced by the tool, when given no other modifiers, are of white Caucasian faces. Given the demographics in our target areas are predominantly not in this category, we want an attempt to seed the model (through tactical behind the scenes prompt editing or other methods) to try and produce a more balanced panorama.
- Advanced Mode: In order to reduce complexity present in many of the features, we want the interface to hide some values that are too complicated or involved for the average user (and can be viewed/edited by enabling ‘advanced mode’).
- Tooltips: Incorporate numerous tooltips to explain the functionality of the different options and adjustments available to users.
- Fully Featured Tutorial/User Guide: To facilitate onboarding, we’d like a fully featured interactive tutorial to guide and teach new users the functionality of the system. Using pre-generated seeds, the tutorial will demonstrate examples of generations to illustrate the function and effect of various different parameters and options such as cfg scale and denoising strength and walk users through the intricacies of prompt engineering and crafting.
- CS Learning Component: We want a series of lessons to be designed, with the goal of highlighting how use of the Stable Diffusion interface involves core CS principles, such as variable manipulation, loops, and basic NLP.
- Examples through Seeded Values: In order to properly illustrate the objectives of different lessons, specific images will be provided as part of the initial instruction and explanation, along with their seeds in order for students to be able to replicate the exact conditions of the sample image.
- Qualitative Assessment: While we do want some lessons focused around stricter quantitative elements, given the nature of the artistic medium, we also want some lessons that are more subjective to qualitative assessment and can require external intervention/evaluation. Eg. “Attempt to make a realistic looking plate of green eggs and ham, what prompts worked best? What elements can you identify about the successful prompts? Why do you think those generated more accurate images?”
- Feature-Rich: We want these lessons to help the children master all the different aspects of the tool, so thinking of creative ways to implement projects that require interaction with some of the more niche features of the interface will be highly valued. This can include exercises highlighting the differences between generation models, denoising effect, inpainting, and more.
Technologies and Other Constraints
The project will involve using the open-source Stable Diffusion model to act as the core of the technology stack. There are many supplementary modules and interfaces for the model that can be utilized at the team’s discretion for the efficacy of the project. Beyond that, there will be significant web UI effort to simplify the interface of the complex model for use by the children. This will largely utilize JavaScript and Python to facilitate interfacing with the model and the web page you design.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Department Mission:
The North Carolina Department of Natural and Cultural Resources (DNCR) oversees the state’s resources for the arts, history, libraries, and nature. Our mission is to improve quality of life by creating opportunities to experience excellence in these areas throughout North Carolina.
Division Mission:
The North Carolina Division of Parks and Recreation (DPR or the “Division”) administers a diverse system of state parks, natural areas, trails, lakes, natural and scenic rivers, and recreation areas. The Division also supports and assists other recreation providers by administering grant programs for park and trail projects, and by offering technical advice for park and trail planning and development.
DPR exists to inspire all our citizens and visitors through conservation, recreation, and education.
- Conservation: To conserve and protect representative examples of North Carolina's natural beauty, ecological features, recreational, and cultural resources within the state parks system.
- Recreation: To provide and promote safe, healthy and enjoyable outdoor recreational opportunities throughout the state.
- Education: To provide educational opportunities that promote stewardship of the state's natural and cultural heritage.
Data & Application Management Program
We support the Division, sister agencies, and nonprofits in web-based applications for various needs: personnel activity, Divisional financial transactions, field staff operations, facilities/equipment/land assets, planning/development/construction project management, incidents, natural resources, etc. Using data from these web apps, we assist program managers with reporting and analytic needs.
We have sponsored previous SDC projects, so we understand the process and how to help you complete this project in an efficient manner while learning about real-world software application development. Our team includes two NCSU graduates that worked on our last project; these two will be overseeing the project and working directly with you to fulfill your needs and make the process smooth.
Background and Problem Statement
The existing LAMP stack system was developed over the course of 25+ years, with ad-hoc application development in a production only environment (mainly using PHP and MariaDB languages) to meet immediate business operational needs of the field staff. The legacy system and upgraded web-applications have been containerized using Docker to run in parallel in the AWS cloud. Many of the legacy applications, including the Fuel application, were written as single file, undocumented, procedural applications. This makes it difficult to read, maintain, and upgrade them. These applications need to be updated with modern design patterns and documentation.
DPR manages 43 state parks and many other natural areas across the state. For the state parks to function, we need division-owned vehicles and fuel, oil, and equipment to operate these vehicles. These assets must be accounted for to manage inventory, budget, and park needs. This is where the vehicle application comes in; it stores information for vehicles, their fuel use, and related equipment across all the Division. Currently, this application is unstructured, outdated, complicated, and does not have the ability to link to other applications like budget.
Project Description
The new Fuel/Vehicle/Equipment application shall maintain the current functionality of the Fuel/Vehicle/Equipment application. The application shall allow for management of park-owned vehicles, vehicles leased from the Department of Administration, and equipment. Administrative users should be able to view and maintain all records for the Division. Users at parks must be able to record vehicle mileage and fuel consumption. They should also be able to record attributes for equipment maintenance such as service dates and equipment condition.
We would like the application to be redesigned to fit a more modern, object-oriented framework that would allow for future API connections to our budget application, standardized control of user permissions, and a more organized database structure.
We are in the process of implementing a new system that allows for continued use of the legacy applications and establishment of a next generation system. The legacy system has been modified to work with the next generation system for continued use, until all applications can be reworked and migrated appropriately into the next gen system. The new Fuel/Vehicle/Equipment application shall be seamlessly integrated into our next-gen system using Docker Compose.
Technologies and Other Constraints
Tools and assets are limited to what has been approved by the NC Division of Information Technology (NC-DIT). Most of the ‘usable’ constraints will be what is limited to NC-DPRs use through NC-DIT.
Our new modernized apps currently run on Docker. Modernized apps each run on their own containers and are written in React with Material UI. The backend consists of a MariaDB container and a unified REST API container used by all modernized apps that runs on PHP 8 and is built on top of the Slim Framework. All legacy applications run on a separate PHP 5 container.
For this project, students will create a new Vehicle application, which will run on its own container. Students are encouraged to use React and Material UI for the new version of the Vehicle application. To support the functionality of this new app, students will also extend the existing REST API and database to add functionality as needed.
Students will be required to sign an NDA related to personal and private information stored in the database and to sign over IP to sponsors when the team is formed
Sponsor Background
The NC State College of Veterinary Medicine is where compassion meets science. Its mission is to advance the veterinary profession and animal health through ongoing discovery and medical innovation; provide animals and their owners with extraordinary, compassionate medical care; and prepare the next generation of veterinarians and veterinary research scientists. With world-leading faculty and clinicians at the forefront of interdisciplinary biomedical innovation, conducting solution-driven research that defines the interconnections between animal and human health, the CVM is a national leader in veterinary research and education.
Background and Problem Statement
Medical best practices for diagnostics in many species (both human and nonhuman animals alike) involve the use of diagnostic blood work to help pinpoint which body systems are functioning properly or not. Laboratory testing of blood samples yields precise values of physiological systems and their functions across a range of measurements, which—for many species—are well documented and understood. At the push of a button lab technicians can generate a report that contains the values for the sample tested as well as a comparison to reference ranges for healthy individuals of the same species. As commonplace as this is for animals like dogs, cats, or horses, no such system is available for poultry (chicken, duck, turkey, etc.). The system currently used involves researchers entering results in a local database and calculating their own ranges, with no compilation of data from multiple farms or projects. At NCSU-CVM, all the test results from poultry blood are entered into an MS Access database hosted on a faculty members’ computer, queries are run to export results into MS Excel, and then an Excel add-on comprising macros to compute reference ranges is run to generate a report. The process is labor intensive, ripe for human error, and limits usability of the data due to lack of web-access.
In prior semesters Senior Design teams developed a React application and Flask backend to facilitate scalable, organization-wide handling of bloodwork reporting and reference calculations. The application is largely feature complete, but several quality of life features remain to be implemented.
Project Description
The existing web-based application allows researchers, practitioners, and owners to submit bloodwork results (with appropriate access controls/anonymization), review previously submitted samples, and generate diagnostic or surveillance reports indicating how an individual sample compares to reference ranges (calculated by the system). New functionality shall include:
- automatic data entry using OCR from pdfs, text files, and smartphone pictures,
- implementation of additional statistical methods for calculating reference ranges for a variety of blood chemistry parameters,
- provenance of comment histories input during data entry and review/approval,
- pagination of large database query results in the backend to improve performance,
- more robust error handling and communication,
- improved testing framework, particularly incorporating DB initialization and destruction during test runs, and
- UI and administration improvements.
The system will be deployed in a limited capacity for testing by CVM staff and collaborators based on the current state of development. Additional needs may arise as early users provide feedback.
Technologies and Other Constraints
Students will leverage the existing React/SQL implementation. The application runs in three Docker containers, with a fourth handling reverse proxy duties (NGINX). The backend REST API is handled via Flask and SQLAlchemy + Pydantic, with MySQL/MariaDB for the database.
Sponsor Background
In just a couple of sentences, describe the sponsoring entity to introduce students to your organization and mission in a way that shows how this project is relevant to you.
Strategic Interaction Video (SIV) is an upcoming online, pre-recorded video-based learning platform. One of the most innovative features of SIV is that, unlike traditional e-learning technologies, it allows learners to interrupt the video instructor at any point during a lecture, ask a lecture-related text-based question, receive an appropriate response, then resume the lecture at the point of interruption.
Background and Problem Statement
Provide background on perceived problem for the student team to solve. What is the motivation for this project?
Currently, responses to all anticipated questions are recorded by the instructor in advance as the course’s content is prepared, and the scripts (text) of these responses are stored and used to identify candidate answers to questions. This is done in a modular backend component (NLP microservice) written in Python by a previous Senior Design team that uses natural language processing (NLP) techniques to identify suitable matches to student questions provided as text input. While pre-recorded videos of the instructor with answers to questions make the learning experience much more similar to that of in-person instruction (students get to see the instructor provide an answer), this limits the range of answers the system is able to provide. For example, the instructor’s video may have recorded the answer in a way that, while accurately providing an answer, does not quite match the wording used by the student to ask the question. Or the instructor may not have a pre-recorded video answer that matches a particular question despite the topic being covered in the class.
This means that available responses are limited to just the questions the instructor was able to anticipate and are stored in the system as pre-recorded video answers. Additionally, anticipating all possible student questions and pre-recording responses to all these questions is time-consuming and makes updating the course difficult as any changes to the content of the course could render pre-recorded answers obsolete.
Project Description
What are your initial thoughts about a potential solution that addresses the problem presented above? Briefly describe your envisioned software solution to be developed by the student team. Use cases and examples are useful. Provide insight into how this potential solution will be beneficial to end users.
The goal of this project is to leverage recent advances in readily available large language models (e.g., ChatGPT, other GPT-3-based models, etc.) to produce answers to student questions that are worded appropriately to match the phrasing of the question, while also accurately addressing the nature of the question without the instructor having to anticipate questions and pre-record answers. This component will be implemented as either a replacement of the current NLP microservice or as an extension of this component.
While large language models are demonstrating high fidelity in producing natural responses, there are some limitations we would like to address:
- Format of the responses: language models produce text-based responses. We would like to use a text-to-speech engine to reproduce these responses and integrate them into our existing SIV platform through the Q&A interface.
- Accuracy of the responses: current language models are known to often introduce factual inaccuracies in the text they produce. For instructional purposes, accurate responses are of utmost importance. There are two main ways in which we would like to address this limitation. The first one is to allow the user to rate a response by clicking either a thumbs up or a thumbs down when receiving a response. The second one is to explore the possibility of training the model further on domain-specific materials provided by the instructor, such as transcripts of the course’s video lectures. This second goal has lower priority this semester.
Stretch Goal
To more closely approximate responding with a pre-recorded video of the instructor answering a question, the text-to-speech answer could be augmented with a virtual avatar. If there is sufficient time this semester, we would like students to explore replacing the instructor’s pre-recorded answer with a generated response of not just audio, but also with an avatar that would provide a visual element.
Technologies and Other Constraints
Provide a list of technologies that you expect students to use. Indicate if each technology is a requirement or a suggestion. If flexible or up to students to choose, please state that. Indicate preferred paradigms (e.g., desktop, cli, web-based, mobile, etc.) to be used in this project for each major component of the expected solution. If flexible, please state that. Indicate if there are any other limitations or constraints you would like the students to know about (e.g., licensing constraints, legal issues, IP issues, etc.), or state that there are none.
The current SIV prototype has a React front-end, with a backend consisting of a PHP REST API built on the Slim Framework, a Python NLP microservice, and a MariaDB database. Each of these components are hosted in Docker containers and orchestrated via Docker Compose.
For the large language model, we suggest students start with the OpenAI API and one of its GPT-3 models, but student input is welcome.
For the text-to-speech component, we suggest students start with the browser-native Web Speech API. Students are encouraged to explore more capable text-to-speech engines as long as they allow unlimited free commercial use.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Blue Cross and Blue Shield of North Carolina (Blue Cross NC) is the largest health insurer in the state. We have more than 5,000 employees and about five million members. This includes about one million served on behalf of other Blue Plans. Our campuses are in Durham and Winston-Salem. Blue Cross NC has been committed to making healthcare better, simpler and more affordable since 1933. And we've been driving better health in North Carolina for generations, working to tackle our communities’ greatest health challenges
Background and Problem Statement
Currently, people who have Blue Cross NC insurance (members) can register and log in to our member portal to self-serve in multiple areas. One area is to retrieve various documents about their healthcare like Explanation of Benefits (EOB), ID Cards, Insurance Plan information, etc. The current architecture traverses several API layers to either retrieve a listing of available documents in our repository to display on the member portal (Document Library) or to retrieve the document selected from the library. Multiple API layers adds complexity, slows performance, and adds cost.
The current architecture grew over time from the first, simple implementation. Over several project iterations the back-end repository solution was changed, bringing in an additional API layer and introducing Elastic. While this added stability and reliability to the repository, refactoring the end-to-end was not possible due to time and funding constraints.
Enabling member self-service generally helps Blue Cross NC to reduce costs as each call to a Customer Service Representative is expensive. In addition, by making a member’s documents available to them online, we can then offer them the choice to opt-out of receiving paper mail, which also reduces costs.
Part of the complexity arises from the entity relationships. Members don’t actually have documents—policies do. Members have policies, but policies remain active for only 12 months. And members are either subscribers (own the policy) or dependents. A subscriber can view all of the policy documents while a dependent may only view “their” documents for a given policy. The Document Library makes available three years of policy documents.
For a typical year Blue Cross NC processes 5 to 7 million EOBs and an ID card per member. These documents are stored in the document repository regardless if the member is a registered user on the member portal.
Project Description
The goal is to re-imagine the Document Library for the Member Portal from its current API based implementation into an embedded application (iFrame for example). This application should integrate more directly with the document indexing solution (Elastic Search) using native capabilities of its stack to eliminate as many API layers as possible.
Given the volume of documents, the index needs to serve for both the member portal and still enable Customer Service to search for a list or a particular document if a member calls in.
By creating a more seamless, cost-effective, and user-friendly experience this solution can reduce the company’s operating expenses which leads to reduced premiums for our members, and enables our driving mission to Make Healthcare Better for All!
Technologies and Other Constraints
Current technology stack includes:
Member Portal UI mobile and desktop: Vue JS (suggested/flexible)
API layer: Java (suggested/flexible)
Search Indexing: Elastic Search (required)
Storage: AWS S3 (suggested/flexible)
Generally:

Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
The Enterprise Infra Architecture team is a group of seasoned security professionals who use our institutional knowledge, technical expertise, and threat landscape experience to engage with our internal business partners and stakeholders to create architectural solutions to secure their business. By understanding our partner’s goals, and then helping to apply our security policies and standards to their networks, devices, and infrastructure services, we help to keep Cisco secure.
Background and Problem Statement
IT teams face the issue of proper Change Management, wherein only approved changes at approved times are implemented/deployed in their cloud environments. For example, an organization may include policies for change management similar to:
- Identity and Access Management resources
- No new role can be created without approval
- No existing role changes can be made without approval
- Compute resources
- No EC2 can be created without approval
- Storage resources
- No S3 bucket can be created without approval
- Network resources
- No new VPN or subnets can be created without approval
- No EC2 can be created on public internet facing subnets
It’s challenging to manually check and enforce these policies. However, a more automated solution could monitor the environment, flag any unapproved changes made to the environment in monitoring mode, and prevent the changes when it’s in the enforcement mode. This will help IT teams have a good Change Management process.
Project Description
Introduction
To help teams with Change Management, we would like to see how we can monitor (and possibly later enforce) this change management in an AWS public cloud environment. Similar functionality could be extended for other cloud platforms.
Users include:
- Requestors – users who can request changes on resources
- Viewers – users who can view requests
- Approvers – users who can approve the requests
Since the AWS platform is API driven, all API invocations are recorded in a cloud trail. Authorized AWS Account users could monitor these cloud trail logs, and take appropriate actions when they see events of interest.
The proposal is to build a product that would help teams in their Change Management strategy. Users of this system would be able to approve a change, and at that time any change made to the account's infrastructure are not flagged. Any changes made outside of the change window are flagged for alerting through various alerting mechanisms like SMS, Messaging systems (Webex, Teams, etc.), or via ticketing system like Jira, ServiceNow, etc.
As the product evolves, teams could pick the specific resources and specific operations that are allowed and not allowed.
Flag Change Window Violations
As mentioned above, cloud trail logs have API calls that indicate infrastructure changes. These could be used to monitor for unauthorized changes. Unauthorized changes could be:
- Changes made outside of approved Change Windows
- Changes made in the Change Window but to not-approved resources
Stretch Goal: Enforcement Mode
The above system as it evolves could be made into an enforcement mode to prevent changes outside the approved change window.
Stretch Goal: Tie into Industry Used Change Management Systems
Initially, the product may have its own change management UI, CLI, API. Eventually, the product could be tied to Industry-used change management systems like ServiceNow, etc. Be 'API first' driven, so all sorts of possibilities can be built using it.
Technologies and Other Constraints
The sponsors will provide AWS credentials/access for students to use for this project.
Here is a suggested technology list:
- AWS CloudTrail
- Various AWS Services
- In case of extension to other clouds, AWS could still be the backend SaaS that can process things, or it could be cloud specific.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
The CSC Undergraduate Curriculum Committee (UGCC) reviews courses (both new and modified), curriculum, and curricular policy for the Department of Computer Science.
Background and Problem Statement
North Carolina State University policies require specific content for course syllabi to help ensure consistent, clear communication of course information to students. However, creating a course syllabus or revising a course syllabus to meet updated university policies can be tedious, and instructors may miss small updates of mandatory text that the university may require in a course syllabus. In addition, the UGCC must review and approve course syllabi as part of the process for course actions and reviewing newly proposed special topics courses. Providing feedback or resources for instructors to guide syllabus updates can be time consuming and repetitive, especially if multiple syllabi require the same feedback and updates to meet university policies.
Project Description
The UGCC would like a web application to facilitate the creation, revision, and feedback process for course syllabi for computer science courses at NCSU. Users will include UGCC members and course instructors (where UGCC members can also be instructors of courses). The UGCC members should be able to add/update/reorder/remove required sections for a course syllabus, based on the university checklist for undergraduate course syllabi. UGCC members should be able to provide references to university policies for each syllabus section, as well as specific required text (that instructors cannot change) as outlined by university policy. UGCC members should be able to update/revise the specific required template text, as appropriate, so that these updates are pushed to all new syllabi created using the tool. Instructors should be able to use the application to create a new course syllabus, or revise/create a new version of an existing course syllabus each semester. UGCC members can then review an instructor’s syllabus in the application and provide comments/feedback on each section of the syllabus, including flagging specific sections of the syllabus for required revision by the instructor. A history of revisions should be maintained. Instructors and UGCC members should be able to download a properly formatted course syllabus in DOCX, PDF, HTML, and Markdown (since several instructors use GH Pages to host syllabus) formats.
Technologies and Other Constraints
- Java
- JavaScript
- MySQL
- The software must be accessible and usable from a web browser
Sponsor Background
The How We Evaluate Lab at NC State is a leader in Advanced Critical Thinking instruction. Working with dozens of NC State Honors Program students, the lab has developed a Moodle course to improve students’ ability to extract and evaluate the soundness of arguments found in complex essays. How We Evaluate (HWE) is associated with How We Argue, the top online site for teaching critical thinking developed by Harvard University’s Philosophy Department. Prof. Gary Comstock of the Philosophy Department directs the lab in consultation with Dr. Collin Lynch of the Computer Science Department.
Background and Problem Statement
One of the key challenges that we face in education is providing rich support for students in complex domains. In order to scale learning in writing and argumentation we must develop new technical mechanisms to provide adaptive support like on-demand hints, answer mapping, and peer feedback.
For example, after reading an essay called “Gamer Monkeys”, students might be asked, “What is the contention of this essay?”
A full credit example response and associated feedback:
- Response: “Gamer Monkeys is not a hoax.”
- Feedback: “Correct. This formulation is accurate, simple, and general. Gamer Monkeys is a reliable depiction of important research.”
A partial credit example:
- Response: “The video Gamer Monkeys shows the results of research that was actually conducted at Duke University.”
- Feedback: “Good try! This formulation is accurate and general. However, we can simplify it by saying ‘Gamer Monkeys is reliable.’ “
An example that might receive no credit:
- Response: “Life is eternal because the monkey did not need to move its arm. The research shows that we can live forever.”
- Feedback: “This formulation is roughly consistent with what the author seems to believe. However, it does not mention the author's central idea--that the video is a hoax--and it contains reasoning, as indicated by the key word ‘because.’ Finally, it consists of two sentences. The contention can only be one sentence.”
A central challenge of this work is applying Natural Language Processing (NLP) to scaffold students in HWE and to support new models of interaction. The project will develop a new learning environment for HWE that can be incorporated into Moodle classes and provide NLP-based analyses of students’ formulation of an essay’s contention, reasons, objections, and rebuttals, as well as to support peer grading, collaboration, and answer translation. Making this approach work will require that we develop tools for natural language understanding, collaborative filtering, task design, and data management.
Project Description
The goal of our project is to create software that will be capable of categorizing all students' (natural language) answers into 3 initial categories: correct, partially correct, or incorrect. Then, the software will return the appropriate feedback, categorizing wrong answers as making one or more of the following mistakes: inaccurate (not true to the author's intent); not general enough (the student's answer accurately picks out a specific claim the author makes, but the author makes more general claims that better capture the spirit of the argument); not simple enough (too complicated); more than one sentence; grammatical mistakes; spelling errors.
This project consists of two primary tasks which include platform development and AI:
- Develop task infrastructure that can be linked from Moodle (for example, as an external activity or an embedded link such that students can be identified with their student credentials) and which can be used to provide a secure interface for students to complete different types of assignments for HWE. These assignment types will include viewing and annotating key portions of a text, writing summaries of texts, and evaluating summaries provided.
- Apply NLP with the texts that we have previously collected and new student data to automatically classify student responses to questions, identify logical and rhetorical errors, and make suggestions to correct those errors. This technology will then be incorporated into the new interface to support NLP-driven interventions which will identify the mistake the student has made and direct them to further exercises for correcting that mistake. This requires designing a program that can analyze natural language text, compare it to correct and incorrect answers, and provide the correct response to a student's mistakes.
The project should apply collaborative filtering algorithms to collect peer assessments of students’ answers to argument questions and use those to support peer tutoring. Later, the peer assessment data could be used to provide peer assignments where students evaluate each others’ solutions and then get feedback based on their grades.
Achieving the goal will improve HWE’s ability to catch and correct student mistakes in real time. Stretch goals include:
- Adapt an existing prototype for argument annotation to enable students to highlight the argument structure of essays to be added to the existing HWE essays. The new prototype will support shared annotation, provide automated feedback, and grade submissions according to established standards.
- Develop a Computer Science module containing two classic, opposed, CS readings so that undergraduates in CS can learn to think critically using an exercise from their major. To achieve this goal we must: a) identify two classic argumentative essays from CS, b) integrate them into How We Evaluate, and c) identify and assist instructors intending to use them.
To seed the project, existing programs to transfer data from Moodle to data sets will be provided.
Technologies and Other Constraints
The solution must be web-based and integrated with Moodle code and is expected to leverage open-source web service and NLP tools. Python language skills are preferred.
Sponsor Background
LiveOak Bank focuses on empowering small businesses across the country. We offer Small Business Administration (SBA) 7(a) loans, lines of credit, checking and savings accounts as well as other banking products to help small businesses solve their monetary needs.
Background and Problem Statement
When building APIs, the first two considerations for security tend to be Authentication (AuthN) and Authorization (AuthZ). AuthN is making sure we know who the API caller is. AuthZ is making sure they are allowed to call the current resource (endpoint) once authenticated. Sometimes we need to be more granular when assessing what a caller can actually do beyond just “can they call endpoint X”. The granular approach is called entitlements and allows us to apply business rules based on certain criteria as to how the caller can use the endpoint.
Project Description
For this project, the team will create an entitlement engine (service) that can trap business logic and provide AuthZ decisions based on the business rules and inbound request data. Outcomes could be to allow fulfillment of the request, deny the request, or partially fulfill a request if such a scenario existed. The engine should be able to service N amount of endpoints with different rules sets for each (the solution put in place should be repeatable. If a sample single API endpoint can be instrumented with it, it should be able to be implemented – in theory – on other endpoints the same way). Ideally, there is also a simple GUI available that allows real time management of business rules. To help with testing, at least one sample endpoint will need to be available to demonstrate how the engine and the endpoint interact.
Sample Use Case:
Let’s assume there is an endpoint in a banking API that allows transferring money from one business account at a financial institution to another account.
Endpoint: POST /api/transfers
There are 3 individuals attached to the business account who have been assigned different roles.
- Sally owns 75% of the business and is assigned the role of owner
- Bob owns 25% of the business and is assigned the role of beneficial owner
- John is an attorney for the business and is assigned the role of power of attorney
The banking laws in place say that each of the roles can move the following amount of money in a single transfer:
- The Owner role can move 100% of the funds in an account at any time
- The Beneficial Owner role can move up to $10k per day
- The Power of Attorney role can move $5k per day
The endpoint implementation would need to enforce these laws (or biz rules) based on the roles held by the caller.
Technologies and Other Constraints
The technology stack you choose to solve this problem is up to the team. Below is a list of resources/technologies that are available around the AuthZ problem that you may find helpful. Ideally, the solution built by the team is 100% custom.
Sponsor Background
Dr. King is an Associate Teaching Professor in the Department of Computer Science at NCSU. As the coordinator for the CSC316 Data Structures & Algorithms course, Dr. King’s responsibilities include ensuring course assessments accurately evaluate student performance on course and departmental learning outcomes. Similarly, the CSC Accreditation coordinator helps ensure course learning outcomes are being assessed, identifies topics that have low student performance, and coordinates meetings with appropriate faculty to facilitate discussions around course improvement. For ABET accreditations, the department must show that Computing Accreditation Commission (CAC) student outcomes are addressed with course assessments. Since CAC student outcomes are broad, the department uses performance criteria (PC) to help with this mapping.
Background and Problem Statement
In CSC316, Dr. King defines topic/lecture-level learning outcomes for each lecture of the course. All course assignment questions are then mapped to specific topic/lecture-level outcomes. At the end of each unit of the course (and before each exam), Dr. King generates reports of individual student performance against each learning objective in the course. These reports help students understand their strengths and weaknesses with course topics, which can help students better prepare for exams. To facilitate the mapping of assignment questions to topic/lecture-level learning outcomes, the Learning outcomes Report software provides a way to organize grade data by course and semester and to generate and export PDF reports of individual student performance. Beyond CSC316, the current Learning outcomes Report software includes an access control mechanism that allows administrators, accreditation coordinators, course coordinators, and instructors to perform role-specific functions. For example, administrators can add/remove/update course coordinators for each course, and course coordinators can add instructors for each course. Course coordinators and instructors can create learning outcomes for a course, map assignment questions to learning outcomes, upload grade data, generate reports, and export reports. However, the current system has some significant limitations:
- the system does not support multiple sections of courses that may have different assignments. Currently, a “Course” may represent “CSC 316 – Spring 2023” that contains sections “001”, “002”, and “601” inside the Course object with separate rolls/rosters. However, all configuration of assignments and the mappings of topics/objects are handled at the Course level, not the Section level. This makes the application inflexible when different instructors for different sections of the same class during a semester want to have different assignments, or even different questions on assignments.
- the system requires instructors to create topic/lecture-level learning outcomes and map those to course-level learning outcomes, but not all instructors have topic-level outcomes for their courses. Course coordinators and instructors should still be able to map assignment questions to course-level learning outcomes, as well as CAC outcomes and PCs.
- the system’s reporting/charts functionality is a bit limited and not customizable. Based on feedback from the latest accreditation visit, different/additional types of reports and charts may be needed.
Project Description
The software system should be updated to improve existing functionality and support additional features, including:
- allow courses to have multiple sections, each with different assignments, rosters, etc.
- allow instructors to map assignment questions directly to course outcomes, departmental (CAC) student outcomes, and performance criteria (PC) used for assessment (making topic-level learning outcomes optional for a course)
- allow accreditation coordinators to create and export custom charts and reports using the data maintained by the software
Technologies and Other Constraints
The existing system uses:
- Java
- Spring Boot
- MySQL
- Angular
Sponsor Background
PositiveHire is a cloud-based human resources software company. It is tailored for experienced Black, Indigenous, and Latinx women professionals who have STEM degrees to find their next career opportunity.
To reach this mission, the PositiveHire platform has a 3-part model which includes:
- a community of Black, Latinx, and Indigenous women in STEM
- a job board option for recruiting underrepresented women in STEM
- a People Analytics solution, PH Balanced™.
Background and Problem Statement
Too often as employers are looking to diversify their employee base, they look for early career talent to fill entry-level roles. But employers overlook the current diverse talent they have in their organizations.
We’re focused on retaining mid-career Black, Indigenous, and Latinx women who are scientists, engineers, and technology professionals.
How?
We found that current employee performance evaluation processes and Human Resources software do not capture or delineate the inequity in the promotion of marginalized women in STEM.
PH Balanced, a SaaS platform, helps organizations identify their internal diverse talent prime for promotion.
About PH Balanced
PH Balanced helps organizations retain diverse talent before they start recruiting new diverse talent.
PH Balanced is a people analytics tool that employers can leverage to obtain diversity metrics about their employees, in order to create Diversity, Equity & Inclusion (DEI) goals and track the progress of their DEI plan. To take it a step further PH Balanced gives employers a chance to review their employee's professional attributes to better assess who is best fit for open roles within the organization.
Project Description
The goal of this project is to develop the PH Balanced Talent Marketplace consisting of a web application (or “dashboard”) to connect an employee to their current employers’ open or future jobs. Employees looking for an opportunity to grow within the company are given a chance to display their skills to obtain a new role. The dashboard display will be used to streamline and enhance organizational efforts in identifying employees to fill current open roles. The dashboard would be beneficial as a cross-platform solution where employees can be promoted and training needs can be easily identified.
For example, when using this software, a vice president of human resources can know how many times they have gone outside the company for talent when they had somebody inside to fill the role. In addition to presenting data about internal candidates, the software could increase internal mobility, reduce turnover costs, improve ROI, etc.
The PH Balanced Talent Marketplace will include employee information from Human Records Information Systems (HRIS), such as job title, pay/salary, demographic information, start date with employer, performance reviews, performance rating, and career development plans.
The interactive dashboard should include the following features and functionality:
- Collect, share, and display career information and data added by individual employees (including personal career goals, training records, certification/licenses, education, and resume).
- Generate a reports dashboard for open job opportunities from provided data
Stretch Goals - Change to HR view listed above
Additional features include:
- Query for open roles or jobs
- Authenticate into PositiveHire user account
Technologies and Other Constraints
Exposure or experience with the following technologies and programming languages are suggested for this project:
- HTML/JavaScript/PhP/Python/Spring or similar language for web application front/back end development
- AWS data services/backend infrastructure: MySQL Workbench
- Database: MySQL for backend
- Collaboration platform: (Miro/GitHub/Codesandbox/etc.)
Support
PositiveHire project managers will be available to lead the students throughout the project as they review requirements, develop sprints and track project burndown during the course of the semester.
PositiveHire will provide the following:
- Sample data for database population
- Wireframe/prototype demonstration of current UI
- AWS, team collaboration platform and web hosting access
- Guidance on specific development tools and framework use and configuration Meetings with the project manager will be expected weekly via virtual conferencing platform.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Truist is a purpose-driven financial services company, formed by the historic merger of equals of BB&T and SunTrust. We serve clients in a number of high-growth markets in the country, offering a wide range of financial services. This includes:
- Retail
- Commercial real estate
- Payments
- Small business and commercial banking
- Corporate and institutional banking
- Specialized lending
solutions - Asset management
- Insurance
- Wealth management
- Capital markets
- Mortgage
We're a top 10 U.S. commercial bank, headquartered in Charlotte, North Carolina.
As the manager of Truist’s Corporate Cyber Security Orchestration and Automated Response (SOAR) platform under the Cyber Development and Innovation division, I act as a product owner for an Agile DevOps team committing to automating Cyber Security alerts and their responses to drive efficacies and reduce cost.
Background and Problem Statement
Truist has several Cyber Security platforms in its environment which are not yet integrated into its Security Orchestration and Automated Response (SOAR) platform. While these systems have RESTful APIs available there are no freely available integrations. This means that Truist is not receiving full value from its Cyber investments. Some examples of these unintegrated Cyber Security platforms:
- Cisco Firepower - Intrusion Detection System
- Shape AntiBot – Antibot logon anomaly prevention platform
- Encase – Forensic investigation software
Project Description
Our internal SOAR platform utilizes containerized applications to enable swift integration, deployment, and scalability. The ideal solution would choose a non-integrated Cyber system and using its RESTful API documentation create a modern Python API overlay/wrapper accepting inputs and data into its container, submitting data, retrieving responses, and making the responses available to the SOAR application. This API broker/overlay code would then be containerized and added to our SOAR platform container repository to be utilized when the SOAR application would attempt to communicate with the cyber tool.
The Python API overlay will reside in its own version-controlled container. This container will be tested and checked into our container registry where it will be pulled as needed into our SOAR application to be used to interface with the selected application.
Technologies and Other Constraints
Python 3
Docker/Podman
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
LexisNexis® InterAction® is a flexible and uniquely designed CRM platform that drives business development, marketing, and increased client satisfaction for legal and professional services firms. InterAction provides features and functionality that dramatically improve the tracking and mapping of the firm’s key relationships – who knows whom, areas of expertise, up-to-date case work and litigation – and makes this information actionable through marketing automation, opportunity management, client meeting and activity management, matter and engagement tracking, referral management, and relationship-based business development.
Background and Problem Statement
Business development lies at the heart of the health of any company. InterAction provides a law firm with the tools to create and manage their business development opportunities and related activities. This can be complex, with business opportunities spanning multiple strategic goals and involving many people at a firm. Regular review is necessary to track progress and ensure that plans come to fruition in a timely manner.
There is a need for a tool that allows the simple oversight of the firm's business opportunities and their day-to-day management.
Project Description
The objective of this project is to produce a tool to allow the review of a law firm's business development pipeline, and the simple updating of progress towards strategic goals.
Each business Opportunity has a name, a lead, target company, estimated closed date and estimated revenue, and progresses through a sequence of Stages until considered closed.
It has associated Initiatives, Tasks and Activities.
Some examples of the tool's potential features include:
Visualize:
- Identify different Opportunity types
- Show progress of an Opportunity through a sequence of Stages in its lifecycle
- Show the total estimated revenue of the Opportunities in a Stage
- Display the state of associated Tasks
- Search/filter/highlight Opportunities by lead, date range, etc.
Interact:
- Update an Opportunity's Stage
- Update the state of a Task
Configure:
- Be able to configure the sequence of Stages for each Opportunity type
An agile development process will be utilized, agreeing a sequence for functional implementation, incrementally delivering capabilities, and adjusting future deliveries on the basis of feedback.
Technologies and Other Constraints
The team may choose their technology stack with any mix of Javascript, Python, and C#.
Angular 13 and D3 should be used for any front end and visualizations.
A structured set of business development data will be provided.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Mann+Hummel is one of the leading filter manufacturers in the world. Our core competency, filtration, is the basis of our business and our responsibility. We are convinced that filtration makes the difference, and MANN+HUMMEL provides key technologies helping to enable a cleaner planet. By separating the useful from the harmful, we are contributing to common goals.
As a family-owned company with over eight decades of experience in filtration, combined with the experience of our employees at over 80 sites worldwide and our innovative solutions, we can proudly say we are a global technology leader in filtration. Convinced by our vision of "Leadership in Filtration", we assume responsibility towards current and future generations and have successfully relied on continuity and reliability since our foundation in 1941.
Over the past few years Mann+Hummel has been working to create a line of digital products focusing on air, water, and oil filtration and quality. These digital products are created by software developers who use agile practices and support web, mobile, and cloud technologies.
Background and Problem Statement
Mann+Hummel uses scrum teams and 2-week sprints to implement agile software development. Along with these practices Mann+Hummel uses the Atlassian suite to track tasks and documentation throughout the software development lifecycle. These 3 tools represent the majority of documentation and output from our software teams:
- Bitbucket: the version control (git) tool that holds all source code, tracks all commits, branches, and pull requests, also manages deployments and CI/CD pipelines, and handles environment configurations
- JIRA: the work ticketing system that tracks all user stories, tasks, bugs, and epics created by the product owner or product management office. These tickets are meant to contain acceptance criteria or some specific description of the work needed by the software developers
- Confluence: A wiki tool that allows all team members to share and track documentation of all types.
In the short term it is easy to see the productivity of any given team through activities like sprint retrospectives or sprint demos. But, as time goes on and deadlines come and go it can be difficult to understand exactly why a team missed a milestone or is not as far along in their development as was requested.
One way to get an insight on the performance of a scrum team is to track events and conditions over the long term of a specific development project. Here are some examples of the events and conditions that could be tracked:
- The number of bug tickets in a backlog
- The number of commits to a code repo
- The number of successful or failed code-builds
- The content or structure of a development ticket in a backlog
- How often tickets are misunderstood, or the work is implemented incorrectly
Getting these statistics manually would consist of manually using JIRA filters, talking with the software development team members, and manually looking for changes in places like Confluence and Bitbucket. In the short term this manual solution could work but across many teams and over a longer period it is highly likely to create inaccurate data and thus stop providing any value to the product managers or to the developers.
Project Description
The goal of this project is to help Mann+Hummel get useful insights about the productivity or potential issues with their ongoing software development projects.
Project Goal:
- Priority 1: Use JIRA Webhooks and some database (sql or nosql) to track ticket events as they’re happening. Create querying and analytics scripts to convert these raw ticket events into summary statistics (more detail below).
- Priority 2: Use the Confluence API to run scheduled checks that look for new pages or page updates. Create querying and analytics scripts to convert these raw events ("number of new pages created", "number of existing pages updated", "amount of content generated" per day, week, month etc.) into summary statistics.
- OPTIONAL Priority 3: Use the Bitbucket API to determine metrics about a set of code repositories including the number of commits and successful or unsuccessful code-builds from Bitbucket Pipelines.
How the Project will run:
Students will be given full administrative access to a mock Atlassian account. They will have access to JIRA, Bitbucket, and Confluence as well as the ability to create their own access and API keys for these tools.
They will be assisted in getting their initial connections through each of these sources and understanding the API documentation as needed.
Once the connections are made, the students will then be tasked with writing the code to query and summarize all the data that is streaming in from these tools and convert them into statistics for a given time. Finally, this can either become available through an API or put into a dashboard that visualizes the summary of events as well as the streaming of events.
The project should have dynamic configuration such that these scripts and summary analytics can be ported into actual projects and the API or dashboard can be used as a project management tool.
Technologies and Other Constraints
Technology preference is Python for API and backend services and React or Svelte for Frontend Services. If cloud technology is needed, then AWS will be used.
Sponsor Background
Our company is an innovative, global healthcare leader committed to saving and improving lives around the world. We aspire to be the best healthcare company in the world and are dedicated in providing leading innovations and solutions for tomorrow.
Merck’s Security Analytics Team is a small team of Designers, Engineers and Data Scientists that develop innovative products and solutions for the IT Risk Management & Security organization and the broader business as a whole. Our team’s mission is to be at the forefront of cybersecurity analytics and engineering to deliver cutting-edge solutions that advance the detection and prevention of evolving cyber threats and reduce overall risk to the business.
Background and Problem Statement
Counterfeit medications are becoming a major problem all over the world and pose a serious threat to patient safety. Fake medications are manufactured with the intent to trick and confuse consumers by subtly altering features like packaging, pricing or ingredients while still imitating authentic medical products. Due to similar packaging, it becomes very difficult for users to detect the difference between genuine and fake medications.
So how can a user determine if a particular drug is counterfeit or not?
Project Description
We would like students to build a drug label verification application that analyzes a drug label image (also called Display Panel) and identifies whether it is authentic or not.
Proposed solution for the students to develop:
Part 1: Build a model that can identify the authenticity of a drug using the image of the drug label and ML/NLP techniques such as object detection and text recognition. For example, the model can detect and analyze the manufacturer's logo for authenticity, as well as extract useful text such as the medication name, composition, etc. from the label to help determine if the medication is counterfeit.
For the dataset, image samples will be collected from Daily-Med, a public database containing drug label images (jpg files). Images can be downloaded from their website: https://dailymed.nlm.nih.gov/dailymed/spl-resources.cfm.
Part 2: Create a web application that will allow users to check the authenticity by uploading an image of the drug label. For example, the app should accept the drug label image as input and return output indicating whether it looks genuine or counterfeit. If it’s flagged as potentially counterfeit, display and highlight which parts of the label look suspicious. An additional feature that would be nice to have is to optimize the web app for mobile devices which would give users the ability to use their mobile device's camera and get the result of authenticity.
The final product should be a web-based solution that will give end users the ability to verify the authenticity of their medications themselves.
Technologies and Other Constraints
The solution must be developed in AWS (provided by sponsors), and specifically leverage Amazon AI/ML Services. Preferred AI/ML services include: Amazon SageMaker, Amazon Rekognition, and/or Amazon Textract.
Amazon S3 should be used to store all project-related data and files (e.g. sample data, training/testing datasets, uploaded images, etc.).
For model and app development, students can use their language of choice (but Python is preferred).
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
The Whitehill Lab - Christmas Tree Genetics Program (CTG) at NC State is working to develop genomic tools to identify elite germplasm for use as Christmas trees. The lab is focusing on elucidation of the mechanisms involved in resistance to pests and pathogens. Understanding these mechanisms allow researchers to develop trees that are more resilient to biotic and abiotic stressors in the face of climate change.
Background and Problem Statement
Scientists in the CTG program handle a large number of plant materials such as unique individual trees, cones, seeds, embryos, cultures and clones. Currently, all the plant material inventory data is managed using Microsoft Excel, which will quickly become obsolete in the face of a growing amount of information needing to be stored, such as new seeds, new plants, or newly generated data regarding existing plant material (subculture steps, move from lab to greenhouse…). Plant material tracking is key for data integrity. We need to know what is what, where and when at any point in time. This is called Stewardship and allows rigorous traceability of our material. In the eventuality that some material is misplaced, or mislabeled, tracing it back to its origin becomes impossible and the material might need to be discarded. A database will help manage our inventory and prevent data loss and mismanagement. Such a database is referred to as a Laboratory Inventory Management System, or LIMS.
Project Description
We would like to replace our Excel spreadsheets with a web-based inventory system backed by a relational (SQL) database. The system should have the following features:
- Users should be able to create new materials in the database, materials of different nature (seeds, trees, cultures). Super-users have edit rights, regular users have viewing access.
- Any given plant material can go through several subculture and multiplication steps. For example, one embryo is multiplied for months (in many containers) and gives birth to large numbers of clones.
- Each material type can be associated with other material types (e.g., Trees produce seeds which contain embryos which become trees)
- The system should keep a log of user actions (creations, edits ,deletions, etc.) that system administrators can query. For this, user authentication is required. These time-stamped actions should be searchable, or the user can filter changes done by a given user or on a given date.
A few more things to add:
- A reporting system can generate custom reports such as “Provide a list of all the material currently present in Incubator #1” or “Provide a list of material in incubator #2 that needs to be transferred to fresh media” (material that has been growing on given media for over a month) or “Provide a list of material that was discarded on specific data”
- Nice-to-have: ability to attach a document (notes or pictures) to the material for example attach a picture of a cone from which the seeds were isolated to show worm damage and contamination issues.
- Data is entered manually, but the search function should allow the user to scan a barcode to retrieve the material. The barcode contains the name of the material being searched for.
- We expect the database to be able to host thousands of data points. The excel spreadsheet currently used contains hundreds (The table constantly grows in 2 dimensions: number of rows and columns, Row representing a unique plant material, columns contain the various steps happening to that material)
Technologies and Other Constraints
The system should be web-based and backed by a relational database. Students are welcome to recommend suitable technologies for both the front-end and back-end, keeping in mind that the sponsors will have limited resources and familiarity with the software technologies used.
Sponsor Background
Managing office hours queues in large enrollment classes can be challenging. MyDigitalHand (MDH) is an online office hours queuing system that is currently used by NC State, Duke University, and the University of North Carolina - Chapel Hill. The tool was originally developed by colleagues at UNC-CH as part of a Google award to support help-seeking in large enrollment courses. The tool was revised as part of a National Science Foundation-supported research project to better understand the help-seeking behaviors of computer science undergraduate students. Our goal is to create an updated version of the tool to support student help-seeking, queue management, and data collection for help-seeking research.
Background and Problem Statement
The current version of the MDH app requires updates and new features. The current stack is outdated and has security issues. Since MDH began as an intra-institutional academic project, nobody currently owns the maintenance and updates to MDH. At the same time, many instructors would like to continue using MDH to manage office hours and gain valuable insight into student help-seeking behaviors. Other institutions want to adopt MDH but are unable to do so in its current form. Therefore we propose re-imaging the MDH app and creating MDHv2.0.
Project Description
MyDigitalHand should have the following functionality:
Course Creation
- An instructor can create a course
- An instructor can create a roster of students, TAs, and instructors for a course by 1) uploading a CSV file of information and 2) creating an individual user.
- An instructor can create a set of pre- and post-help session questions for students to answer. ● An instructor can create a set of post-help session questions for the teaching staff to answer.
Office Hours Interactions
- A member of the teaching staff (instructor or TA) can start an office hour session.
- A student can raise their hand during an office hour session. As part of this, a student completes a pre-help session questionnaire about why they are seeking help.
- A member of the teaching staff can call a student to come to find them, start a help session, and end a help session.
- The student and teaching staff member completes a post-help session questionnaire about the interaction and progress.
Data Collection and Visualization
- Data about teaching staff office hours sessions should be recorded.
- Data on when a student raises their hand, when they are called for help, when their help session starts, and when their help session ends should be collected.
- Data about pre- and post-surveys should be recorded.
- Summaries of interactions, wait time, calling time, and help session time should be provided to instructors.
- Ability to export reports for further external analysis (CSV or JSON)
Part of this project is to also gather usability feedback from current NC State instructors using MDH and create a list of features that need to be updated or added. Instructors from other institutions may also be included.
Stretch Goals
- Provide the ability for an instructor to hold office hours for multiple classes at the same time by intermingling the queues
- Provide the option for using Shibboleth and LDAP authentication to tie to university authentication systems.
- Provide a secure API for data connections to other projects (e.g., Concert)
Technologies and Other Constraints
MDH will be released open-source to the computing education community, likely using one of the Creative Commons licenses.
MDH should be a responsive web application that could run on AWS or a local university server. Proposed Technologies
- React
- Flask
- MySQL
- REST API
- Stretch: Connection to Shibboleth and/or LDAP authentication
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Siemens Healthineers develops innovations that support better patient outcomes with greater efficiencies, giving providers the confidence they need to meet the clinical, operational and financial challenges of a changing healthcare landscape. As a global leader in medical imaging, laboratory diagnostics, and healthcare information technology, we have a keen understanding of the entire patient care continuum—from prevention and early detection to diagnosis and treatment.
Our service engineers perform planned and unplanned maintenance on our imaging and diagnostic machines at hospitals and other facilities around the world. Frequently, the engineers order replacement parts for our machines (e.g a magnetic coil for an MRI machine). When a machine needs maintenance, we send whatever parts our engineers need to repair the machine. This project proposal comes from the Managed Logistics Department at Siemens Healthineers, and our goal is to get those spare parts to the engineers as quickly and accurately as possible. We help to deliver confidence by getting the right part to the right place at the right time.
Background and Problem Statement
While we strive for 100% accuracy when shipping spare parts, occasionally we come short of the engineer’s expectations. When this happens, the engineer can submit feedback for our team. Currently, the feedback submission process is handled by a third-party logistics company with an application that is cumbersome for the engineer to use. The feedback is then transmitted via secure FTP to our own concern management system. Our goal is to improve the engineers’ user experience by creating our own application for feedback submission and establishing better integration between the concern management system our department uses and the feedback application the engineers use. This new app would also replace the other functionalities of the third-party app, such as order tracking and updates.
Project Description
Our wish for this semester is for the team to develop a prototype mobile website as a proof of concept for replacing the third-party app. Some functions we want this website to include are:
- Track an order over various milestones (e.g. Order Created, Out for Delivery)
- Collect feedback responses from the engineer via a form that would include:
- a score (from 1 to 5 stars) of how well the order went
- an option for the the engineer to write a review or complaint
- provide the option to specify which aspect of the order was problematic. Examples of these aspects are topics like “Late Delivery” and “Wrong Part in Box.”
- Send feedback to a separate Concern Management System using an API
- Send notifications to a user when there are updates, by user preference.
- Have a functional and user-friendly design
Technologies and Other Constraints
We request that the product be a mobile website. Our team is most familiar with a Python/Django stack, but this is only a suggestion in case the team is not more comfortable with another technology stack for web applications.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Professors Barnes and Cateté in the NCSU Computer Science department are working together to build tools and technologies to improve k12 learning in science, technology, engineering, and mathematics, especially when integrated with computer science and computational thinking.
Background and Problem Statement
According to Code.org, over 50% of the U.S. states classify computer science as a math course contributing toward graduation. Unfortunately, higher level AP computer science courses are offered in less than 50% of schools, and are attended less often by students of color. Advances in technology, particularly around artificial intelligence, machine learning, and cyber security, have given rise to both 1) a need for students to have a firm grasp on computer science and computational thinking (CS/CT) in order to contribute to society, and 2) a need for rapid development of educational tools to support their learning.
Regarding the latter, computing educators are often teaching a brand new subject after only a few weeks of training and very little experience with scaffolding, grading, and providing formative feedback on related activities. Many tools developed to help support these teachers specialize in a single feature and don’t always consider the context of a live classroom. There has also been less attention paid to integrating analytics and intelligence into these tools to help analyze the impacts on the educator and students. Furthermore, although many individual educational tools are beneficial to students, the complexity around interacting with a variety of systems can cause students to become confused and disengaged, which may inhibit their learning. If students cannot manage their work and interactions in a useful and intuitive way, they lose the educational benefit of the systems they are attempting to use.
Therefore, it is critical for CS learning by novice students to be able to provide a complete package for teacher-centric and classroom support around block-based programming.
In this project, we will build on a current beta tool called SnapClass. SnapClass will integrate multiple learning features into one environment for total classroom support. Our objectives as part of this project are to 1) develop new intelligent and data-driven supports to provide a teacher-centric hub for activity creation and student assessment, 2) develop an administrative dashboard for school staff to manage student accounts and activity and 3) collaborate with our K-12 school and teacher partners to beta-test, co-design and iteratively refine the new SnapClass system prior to release in the BJC and infusing-computing communities. While the different features are deployed into dozens of classrooms, with complete integration, SnapClass will become more accessible and desirable for a greater number of teachers, including the network of 500+ AP CS Principles teachers using the Snap!-based BJC curriculum and their 20,000 students annually.
Upon initial integration, SnapClass will be beta-tested with a core group of our partnering schools and teacher practitioners. This will include BJC Master Teachers (those who teach BJC and train new teachers) and our infusing computing teacher partners, including a research practice partnership where computing activities are integrated into the school’s classrooms. We have developed research and working relationships through our previous educational outreach efforts, so we can easily and quickly work with educators in these school systems to deploy and evaluate SnapClass. Once iteratively refined, we will release a larger deployment into our larger BJC and infusing computing network of nearly 1000 middle school and high school teachers.
The Spring 2023 will build off of work done by the prior two teams (Spring 2022, Fall 2022) who developed from the original 'GradeSnap' software. The prior SnapClass teams have been able to extend the functionality of the system to include the integration of multiple block-based programming languages into the environment, creating a FAQ for students working in Snap, developing a mechanism for auto-saving, among other features that have been directly requested from the intended users of the system.
Project Description
SnapClass is a learning hub used for account management and project sharing by both students and teachers for STEM+C assignments based on the Snaphub at North Carolina State University. SnapClass facilitates low maintenance tools to establish intelligent and adaptive collaborative learning environments for students such as iSnap, and learning management tools and support for teachers such as GradeSnap, with the scalability of data driven tutoring systems.
SnapClass will integrate classroom support tools to create a more cohesive and well-supported learning environment for both teachers and students. Additionally, Snapclass will extend GradSnap’s teacher portal to include local school base account administration, and also build a data center dashboard that uses data-driven and intelligent features to supply the teachers with live and post activity feedback on their students’ pace, performance, and estimated levels of understanding.
This semester's group will work on the following features to extend the SnapClass platform:
- Means for teachers to differentiate assignment to students based on skill level
- Mechanism for exporting SnapClass data (student classroom grades on activities in a CSV file format) acceptable to other common Learning Management Systems (Canva, Google Classroom)
- Way to upload "non coding assignments" including multiple choice questions/free response questions
- Developing a Activity Library' for commonly used lesson that teachers can upload their own lessons to and search through by learning objectives, curricula, age, difficulty etc
- Means to display student code on teacher laptop mid assignment and extending ‘help’ functionality to be able to look at the code and edit directly
- Means for teachers to enroll students in already established pre-built curriculum (e.g. the Beauty and Joy of Computing with all of its lessons) rather than develop all of their lessons independently (Senior Design students would not develop the curriculum, just the means for automatically enrolling students in a full course - e.g. assigning multiple already established lessons all at once)
Technologies and Other Constraints
- Desktop/Web-based/Mobile development - Requirement
- Snap
- Cellular
- JavaScript
- HTML
- SQL/phpMyAdmin
- Current Tech Stack for SnapClass - (Nice to know)
- Node.JS
- Mocha (Unit Testing)
- Angular
- MySQL
Sponsor Background
The Diversity Movement (TDM) launched in 2019 as an eLearning organization that grew rapidly into a full-service, product-driven consultancy, helping 100+ client organizations operationalize diversity, equity, and inclusion (DEI) as a business growth strategy. The Diversity Movement(TDM) helps organizations build high-performing teams and a culture of belonging through diversity, equity, and inclusion (DEI) practices. We use a combination of digital learning, leadership development and analytics to fulfill this mission. Our award-winning MicroVideos offering, a micro-learning platform containing 600+ 2-3 minute videos, was recognized on Fast Company’s exclusive list of global organizations changing the world for the better. Our goal is to extend MicroVideos so that they are available on any device, any time, and any place.
Background and Problem Statement
As we expand our library of MicroVideos, we want to improve the user experience by making search easier to use and suggestions more relevant to a user's preferences. We anticipate adding user generated videos and expect machine learning (ML) to become critical for content categorization and recommendations. We also believe that Natural Language Processing (NLP) will become a core behind-the-scenes component of our system.
We believe that integrating a combination of intent recognition, natural language processing and artificial intelligence/machine learning into a Netflix-style user interface will transform how organizations and their employees incorporate DEI into their organizations and daily roles.
Project Description
For this project, we would like a simple implementation of Netflix Clone using TDM’s current 600 video library. We expect the project to be based on the best Netflix Clone Repo that enables the following extensions to be added. Here are some illustrative samples below:
https://github.com/AhmedTohamy01/React-Netflix-Clone#technology-used
https://github.com/amoldalwai/watch-any-movie
https://github.com/codermother/Netflix-Clone
Once the base is completed, we would like the SD student team to collaborate with us (TDM) and add features which will become inputs to a recommendation engine. These features might include:
- Likes,
- Comments
- Shares,
- Time watched,
- Paused,
- Push notification of new videos,
- other features suggested by the group
The results of these features are stored with the user profile or each video’s meta data (e.g. Title, Category, Short Description, Video Length)
Once a few features above are added, they and the user’s profile become inputs to TensorFlows Recomenders an elegant and powerful library for building recommendation systems. These recommendations are presented to the user in a new category Videos Just for You.
Technologies and Other Constraints
DataBase: MySQL, MongoDB or other database of team choice
Mobile Dev Platform: React Native
ML Platform: TensorFlow
TensorFlow Recommenders repository on GitHub
Identity Management
JWT Authentication
Sponsor Background

Autonomous vehicles technology is maturing and could offer an alternative to traditional transit systems like bus and rail. EcoPRT (economical Personal Rapid Transit) is an ultra-light-weight and low-cost transit system with autonomous vehicles that carry one or two passengers at a time. The system can have dedicated guideways or, alternatively, can navigate on existing roadways where the vehicles are routed directly to their destination without stops. The advantages include:
- Dual mode – existing roadways and pathways can be used for low install cost in addition to elevated roadways at a lower infrastructure cost than existing transit solutions.
- A smaller overall footprint and less impact on the surrounding environment so guideway can go almost anywhere.
The research endeavor, ecoPRT, is investigating the use of small, ultra-light-weight, automated vehicles as a low-cost, energy-efficient system for moving people around a city. To date, a full-sized prototype vehicle and associated test track have been built. For a demonstration project, we are aiming to run a fleet of 5 or more vehicles on a section of Centennial campus. The Vehicle Network server will serve as the centralized communications and vehicle routing solution for all the vehicles.
Background and Problem Statement
With the aim of running a multi-vehicle, live pilot test on Centennial Campus, the overarching goal is to create a Vehicle Network Controller (VNC) and the associated Robot Operating System (ROS) vehicle client software to guide the vehicles and provide interaction to users. Please refer to the architectural diagram below showing the server architecture of the solution. The VNC will manage a fleet of cars, dispatching them as needed for ride requests and to recharge when necessary. It will also provide interaction to users to both make these requests and manage the network itself.
Project Description
The work on the VNC will continue work from previous senior design teams. The current VNC solution provides a limited ability to simulate multiple vehicles, evaluate metrics of performance, create administrators/users, and allow for vehicle clients to interact with the server in different ways. Though still considered an alpha stage at this point, there is a need to further develop the VNC to make it ready to be used with physical vehicles. Also, new this year is a senior design ECE team with coordination by IBM to develop miniature autonomous vehicles.
Further, recent Industrial Design students developed the user interface for a phone app to integrate with the VNC. Examples of the user interface of the design are seen below, and a link to their full presentation is here:
https://www.canva.com/design/DAFTQ3IuyIg/ehsmPoQkQT82lpPud-lbpw/edit
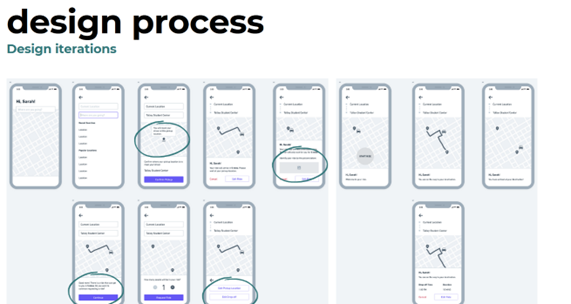
Image by Ngoc Nguyen
Previous work focused on replacing google maps as the vehicle routing and planning. This effort is related to improving the app user interface and integrating with smaller vehicle hardware for testing purposes.
Continuing this effort will include two tasks. First is integration of the wireframe design of the app with the existing Vehicle network controller. Previous work has been done to provide a user interface. This effort would be an improvement over the existing app/web-based solution.
As a second effort, the ECE senior design team is developing miniature vehicles. It will be possible to integrate these vehicles with the current VNC solution. The task here is to make the needed changes to finalize the integration. The task will include communication and coordination with the ECE vehicle team, clearly defining the interface between VNC and vehicle, and adding any minor glue logic to accommodate minor feature additions.
Specifically, the CSC Senior Design team’s tasks would include:
- Updated app to include the new user interface flow design
- Integration of wireframes into existing app
- Verification of interface requirements for VNC component
- Design and implementation of additional API interfaces needed for additional functionality
- Adapting the VNC to operate with ECE senior design team’s vehicle
- Addition of minor features which could include
- Generalized data packet sending
- Additional diagnostic data
- Testing and verifying functionality with vehicle hardware
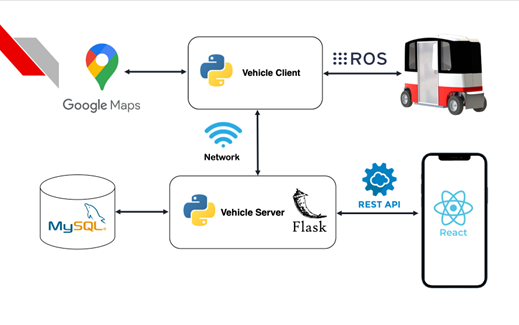
Previous Architecture of Vehicle Network Server
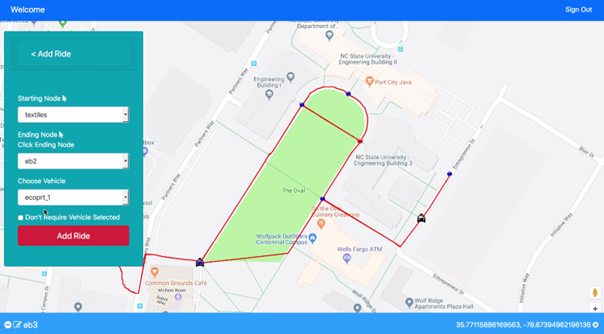
Initial View for Vehicle Network Controller

EcoPRT Vehicle
Technologies and Other Constraints
This project will give the team a chance to work with the following technologies.
|
Name |
Description / Role |
Version (if necessary) |
|
ROS |
Robot OS system for autonomous vehicle |
Melodic |
|
NodeJS |
Web Server software. This will run on the web server and will serve the website and connect the website to the database. It will contain a REST API. The REST API will allow the website and other services to access the functions of the web application. |
8.9.4 |
|
Python |
Used to write the Vehicle Server and Vehicle Client processes |
3.4.9 |
|
NPM |
Node Package Manager for installation |
- |
|
MySQL |
SQL implementation. Database that is used for storing tabular data that is very relational in nature. |
14.14 |
|
Neo4j |
Graph database. Used for storing graph-like data. Uses the Cypher query language. |
3.4.9 |
|
Bootstrap |
Using Bootstrap will give more freedom to customize the look and feel of the web application. It also makes it easier for to make a mobile friendly version of the website. |
4.0.0 |
|
AngularJS |
Used for the logic of the website. It works very well for data binding which is the bulk of the web application since all data is pulled from the database. |
1.6.8 |
|
Express |
Routes URLs to files and/or functions |
4.16.2 |
|
HTML5 |
Used to create web pages |
5 |
|
REST |
Used to get information from the server and send it to the front end |
- |
|
Socket.io |
Used to get information from the server and send it to the front end |
2.0.4 |
|
CasperJS |
Used for automated testing of web applications with JavaScript |
1.1.0-beta4 |
|
Mocha |
JavaScript framework for Node.js that allows for Asynchronous testing |
5.0.5 |
|
Chai-HTTP |
Assertion library that runs on top of Mocha |
4.0.0 |
|
Istanbul (nyc) |
Used for determining code coverage |
11.7.1 |
Sponsor Background
IBM is a leading cloud platform and cognitive solutions company. Restlessly reinventing since 1911, we are the largest technology and consulting employer in the world, with more than 350,000 employees serving clients in 170 countries. With Watson, the AI platform for business, powered by data, we are building industry-based solutions to real-world problems. For more than seven decades, IBM Research has defined the future of information technology with more than 3,000 researchers in 12 labs located across six continents.
The Department of Forest Biomaterials at NC State’s College of Natural Resources is home to one of the oldest and most respected paper science and engineering programs in the world as well as a cutting edge sustainable materials and technology program.
Background
Background: As of 2018, 300 MM tons of Municipal Solid Waste (MSW) was available in the US. Of that material, about 50% was landfilled, representing a huge opportunity for the conversion of the energy value of MSW not captured into cost effective and sustainable biofuels which can help support DOE’s selling price of less than $2.50 per Gasoline Gallon Equivalent and national energy security independence. We are working on AI-driven MSW characterization with the use of visual, multi spectral, and hyperspectral sensors. The idea is to build and train a model to identify types of materials (grade 4 plastic, high lignin paper content, glass etc.) in real time.
Project Description
We plan to build Augmented Reality (AR)-assisted sorting technologies for workforces in the field. This will require tracking multiple objects moving on a belt and putting labels (color codes and text) on each object.
Every 10 seconds, a set of objects is placed on a belt. The AR engine will put labels on each object and track their position until each object leaves the conveyor belt. Initially, the labels and the initial position of the objects would be provided. Future work on the project will involve integrating AI components to automatically identify and label the object.
This project will give the team a chance to work with technologies for Computer Vision, Augmented Reality toolkits and 3D Visualization.
Sponsor Background
The Laboratory for Analytic Sciences (LAS) is a research organization in support of the U.S. Government, working to develop new analytic tradecraft, techniques, and technology that help intelligence analysts better perform complex tasks. Processing large volumes of data is a foundational capability in support of many analysis tools and workflows. Any improvements to existing processes and procedures, whether they are measured in time, efficiency, or stability, can have significant and broad reaching impact on the intelligence community’s ability to supply decision-makers and operational stakeholders with accurate and timely information.
Background and Problem Statement
With growing data volumes and access to faster communication infrastructure, building machine learning models that scale is a complicated task. From a data volume perspective, care needs to be taken so as to not slow down overall bandwidth capacity. For example, the current leader of sortbenchmark.org (tests how long it takes to sort a massive amount of data) has reached a throughput of 60.7 TB/min [1]. Based on recent experiments out of Sweden and Denmark [2] that push communication throughput to outrageous speeds, the best sorting method would be behind by 110.34 PB after a single minute. When looking to detect fraudulent or nefarious activities (e.g. cyber security), machine learning models embedded within the flow of data will need to maintain these high levels of throughput or risk falling considerably behind.
Instead of a highly complicated machine learning model in the processing flow, we seek to develop a rule-based system (e.g. key-value lookups) that can reduce data volumes to a more manageable level before a complicated model is run. LAS research projects like RADS (2021) and TLeaves (2022) use a lot of features and computation, too much to keep up with throughput speeds on production systems. We seek the help of NCSU Senior Design to design a web application that can enable demonstration of these projects’ unique advancements outside of the normal processing flow.
Project Description
This web application will need to handle both machine-generated (analytic) and user-supplied input, and allow users to manage prioritization of data based on a reduced set of fields.
Background Use Case of the RADS / TLeaves Problem
Cyber security data from around the globe is ingested into a central data repository where users can query against the data to find intrusions. Just like any large company, some organizations may be in charge of finding specific intrusions for specific clients, while others may be looking holistically for trends and indications and warnings of impending attacks.
At some point in time a system owner will have to tell the users of the central data repository that they are not allowed to keep ALL of their data in perpetuity (e.g. finite amount of space). The organizations will need to better understand and manage their data. Given these restrictions, there are a few ways an organization can do this:
- Manual entry - a user specifies a specific set of values for a field that are then used for prioritizing data.
- User activity association - a system (e.g. RADS / TLeaves) can use user activity details to infer what a user cares about
At the end of the semester, we hope to have an application that combines both of these methods into a single management interface where a user can manage data rules, visualize the outcomes of these rules, and visualize user activity information in hopes of finding new and novel ways to prioritize data.
Rule Management (Part 1)
- Rules for data retention can be loaded into the app in two different ways:
- Batch load (from systems like RADS or TLeaves)
- Manual user input
- A data management rule will need to maintain the following information:
- Unique identifier
- Rule (e.g. IP address with or without a Port Number)
- Status - Active / Inactive
- Associated with 0…n organization bucket(s) (each maintaining a priority)
- An organization bucket will need to maintain the following information:
- Unique identifier
- Max data size limit per 24 hours (e.g. can only keep 20 GB of data)
- Max data duration limit (e.g. can only hold on to the data for 1 month)
- Associated rules (and their priorities)
- A bucket priority will need to maintain the following information:
- Data management rule
- Organization bucket
- Priority (unique per bucket)
- After creation of rules, a rule can be modified but not deleted (only set inactive)
- After rules have been created / loaded, a user can filter / search / sort the data in the following ways:
- Detailed view of a bucket (show all associated rules in priority order)
- Detailed view of priorities (show all rules in a given priority, agnostic to buckets)
- Detailed view of a rule (show bucket information along with bucket-specific priorities)
- After creation, bucket limits (size and duration) can be modified.
- Buckets will be loaded in the database / specific ingest endpoint and do NOT have to be created via UI
- The app should allow a user to generate a ruleset that is a representation of the current configuration (bucket, rules, and associated priorities).
- This can be a manual export button or on a schedule (e.g. every day)
Performance Metrics (Part 2)
Given (mock) performance metrics from a file, ingest the metrics for a user to view alongside a particular ruleset.
- The user should be able to view the average metrics in a time-limited format (e.g. 5 minutes, 1 hour, 1 day).
- The user should be able to view average data size (bandwidth) for each bucket.
- The user should be able to drill down into a bucket to view the data size for each rule.
- For a given bucket, the priority level where data had to be aged-off due to bucket priority (e.g. enough data in the high priority came in that we didn’t even get to a medium priority).
User Activity View (Part 3)
Details of this stage will be discussed if time allows. In general, we would like to be able to view and drill deeper into how users are searching for data. In our RADS example above, this would be a tabular interface where we could see what data a user interacts with, and when.
Technologies and Other Constraints
The application should be stand-alone and should not have any restrictions (e.g. no enterprise licenses needed). In general, we will need this application to operate on commodity hardware and be accessible via a standard modern browser (e.g. Chrome, Microsoft Edge, etc).
The current list of sponsors have experience with the following technologies:
- JavaScript frontend frameworks like Vue.js, Angular.js, or React.js
- Python or PHP backend frameworks like Flask or Django
- SQL and NO-SQL databases
ALSO NOTE: Public distributions of research performed in conjunction with USG persons or groups are subject to pre-publication review by the USG. In the case of the LAS, typically this review process is performed with great expediency, is transparent to research partners, and is of little to no consequence to the students.
References
[1] Marián Dvorský. (2016, February 18). History of massive-scale sorting experiments at Google - The Google Cloud Blog. Google Cloud. https://cloud.google.com/blog/products/gcp/history-of-massive-scale-sorting-experiments-at-google
[2] Pranshu Verma. (2022, October 27). This chip transmits an internet’s worth of data every second - The Washington Post. The Washington Post. https://www.washingtonpost.com/technology/2022/10/27/laser-powered-chip-internet-data-transfer/
Sponsor Background
The Laboratory for Analytic Sciences is a research organization in support of the U.S. Government, working to develop new analytic tradecraft, techniques, and technology that help intelligence analysts better perform complex tasks. Processing large volumes of data is a foundational capability in support of many analysis tools and workflows. Any improvements to existing processes and procedures, whether they are measured in time, efficiency, or stability, can have significant and broad reaching impact on the intelligence community’s ability to supply decision-makers and operational stakeholders with accurate and timely information.
Background and Problem Statement
The Laboratory for Analytic Sciences (LAS) hosts an annual event called the Summer Conference on Applied Data Science (SCADS). This is an 8-week immersive workshop bringing approximately 40 data science professionals from academia, industry, and government to the campus of NC State University to focus on a 5-10 year challenge problem. The challenge is to create a system capable of automatically generating a “tailored daily report” (or “TLDR”) for individual users of the system. The vision of a TLDR is a relatively short, easy-to-consume report filled with content of great interest to the user and provided on a recurring or on-demand basis. The content of a user’s TLDR is to be “tailored” to that individual user’s objectives and interests. Source materials for a TLDR could be drawn from a very broad and diverse set of information repositories/outlets/feeds. Examples could include published news articles, social media, knowledge repositories (e.g. Wikidata), log files, or perhaps even raw data elements such as sensor readings (e.g. weather sensor readings, camera feeds, etc), etc. The TLDR system being constructed by SCADS participants over the coming years is anticipated to gather, process, prioritize, and synthesize information from such sources. Finally, it will then need to generate a “TLDR” itself in some form, for presentation to the user. This latter portion is the focus of this project proposal.
Project Description
As a result of the initial SCADS workshop in 2022, a basic prototype TLDR interface was built using the goals described above. The goal of the student team is to enhance an existing prototype interface for the TLDR system. The existing prototype is quite basic, and is a launching point on which to build a more functional, and more feature-rich, vision of a TLDR interface.
[Screenshot of the current prototype]
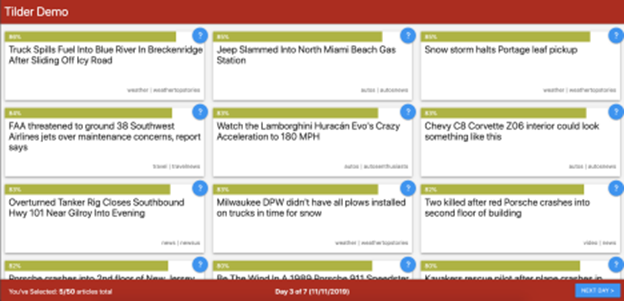
Given an existing machine learning model to provide news article recommendations, the prototype provides for the user to use and iterate through the model’s recommendations. The interface currently provides article recommendations to users, along with explanations of why each article was recommended, and updates its recommendations on a daily basis based on what previously-recommended articles the user “likes”. Key enhancements to this prototype for the student team to build include the following. Priorities for these will be determined after taking into account the technical interests of the student team.
- Create frontend and backend support so that a user can look at the results from multiple model recommendations.
- Enable the users to toggle between available models to compare and contrast results at any time.
- Create a word cloud of the recommended news articles so that the user has an alternative data view of the recommended news articles. Allow the user to toggle between news article views.
- Given the current news article display, organized by recommendation and category, include a filter that will order the returning recommended news articles within each category by keyword.
- Enable the application to be user-based and to store results for each particular user.
- For each article that is selected by a user as “interesting”, retain that information in a backend database.
- Adapt the prototype so that it is able to interface with machine learning models that are deployed via docker containers with an associated results endpoint.
Below are other things to consider as we build out the features described above. These are not requirements, but should be considerations in design and implementation.
- The prototype interface is to have dashboard-like qualities, such as several visual sections devoted to different TLDR functions. For example, one section will likely need to be focused on providing a multi-modal holistic view of information-of-interest, while other sections should be focused on presenting specific data types (published text articles, raw sensory data, contextual information, etc), and summaries thereof. At present, the prototype is very basic, only providing a single view, informed by a single recommender model, of a single article data set. We would like to expand its capabilities to be more encompassing of the multi-modal environment in which knowledge workers reside.
- The prototype is to offer users the capability of submitting feedback into the system to better tune informational content toward their current objectives and interest. Feedback can take three separate forms; “passive feedback” consisting of user-interaction measurements logging how users interact with content in the TLDR, “active feedback” consisting of information explicitly provided from the user in order to better tailor/tune the TLDR’s content towards their objectives and interests, and “interactive feedback” where the system prompts the user to provide active feedback for a specific purpose. Taking some form of action based on feedback is only currently practical in a limited set of scenarios, and those will be left as a stretch goal. For now, the goal is to design and structure/architect the prototype in such a way that feedback can be gathered and stored to enable future development of dynamic mechanisms that will utilize the feedback.
- The prototype’s interface is to enable users to access “explanations” of why any particular item of information is being presented. The student team may assume that such explanations will be provided by the underlying AI/ML models being developed by the LAS, but must develop interface elements capable of presenting them to the user on-demand. Offering these explanations to users engenders trust in the system, and enables the users to submit effective feedback. The existing prototype has a button which, when clicked, displays a pop-up window showing the results of LIME, an explanation tool for AI/ML models. We desire the prototype to be engineered in a manner to support such a capability for all additional content sources to be used.
- The prototype should be engineered to support multiple users concurrently. The existing prototype is extremely limited. Relatively small improvements to its backend design could enhance its utility significantly.
- As mentioned above, the existing prototype only offers the results of a single recommender model against a single data set. In particular an article recommendation engine for the Microsoft News Dataset is implemented, along with explanations offered by LIME. Including additional data sets, and/or additional model results is a keenly desired feature. The student team will not necessarily be expected to develop the models, or gather the data sets, rather the desire here is to enable the prototype user to choose, and make use of, multiple resources. The LAS will provide the student team with additional models and data sets to incorporate into the prototype.
- The prototype should have a fully modularized design. The LAS’s goal is for the fully-functional TLDR system to be developed over the coming 5-10 years. Capabilities that it will require are in varying states of development, with most needing significant improvements if the TLDR is to be successful. We anticipate that every sub-capability of the TLDR will be continuously updated and improved over this development period. Therefore, we must make it simple for components of the TLDR to be swapped in/out, and updated, without breaking the system at large. This will likely require development/use of APIs, containerization technologies (Docker/Docker Swarm, Kubernetes, etc), and model registry/versioning systems (e.g. BaILO, etc).
- The visual structure/layout of the prototype interface itself would ideally be automatically tailored to the individual user’s needs. The capability of automating this is not in the scope of this project, however if practical and time-permitting, a stretch goal would be to engineer the interface in such a way that it can be later updated to take advantage of custom layout inputs should the capability of determining an optimal visual structure/layout be generated at some point.
A main outcome of this effort is to provide future SCADS participants with an application to both demonstrate the models they build and to prototype the human and machine interactions that are a part of a TLDR. This prototype will be of tremendous benefit to the SCADS effort. In addition, we also expect to test the different TLDR concepts and utilize this experience to better refine the TLDR concepts/goals moving forward.
Technologies and Other Constraints
The application should be stand-alone and should not have any restrictions (e.g. no enterprise licenses required). In general, we will need this application to operate on commodity hardware and be accessible via a standard modern browser (e.g. Chrome, Microsoft Edge). Beyond those constraints, technology choices will generally be considered design decisions left to the student team. That said, the LAS sponsors for this team have experience with the following technologies and will be better able to assist if they are utilized:
- Python or PHP backend frameworks like Flask or Django
- SQL and NoSQL databases
- Docker
- JavaScript frontend frameworks like Vue.js, Angular.js, or React.js
References
LIME:
https://lime-ml.readthedocs.io/en/latest/
MIND:
BaILO:
ALSO NOTE: Public distributions of research performed in conjunction with USG persons or groups are subject to pre-publication review by the USG. In the case of the LAS, typically this review process is performed with great expediency, is transparent to research partners, and is of little to no consequence to the students.
Sponsor Background
LexisNexis® InterAction® is a flexible and uniquely designed CRM platform that drives business development, marketing, and increased client satisfaction for legal and professional services firms. InterAction provides features and functionality that dramatically improve the tracking and mapping of the firm’s key relationships – who knows whom, areas of expertise, up-to-date case work and litigation – and makes this information actionable through marketing automation, opportunity management, client meeting and activity management, matter and engagement tracking, referral management, and relationship-based business development.
Background and Problem Statement
Large applications can have a deep history. Over time, software patterns evolve and dependencies require updating. Given the size of an application, it’s often hard to ensure any refactoring actions are exhaustively applied, leaving the codebase in a partially migrated state, mixing patterns and practices, leading to confusion on which pattern to follow for any given implementation, and increasing technical debt.
InterAction’s current incarnation is only 3 years old but has grown quite large with the size of the team working on it. At the same time, the open-source ecosystem around .NET - one of the platforms InterAction is built on - has accelerated, leaving patterns and dependencies out of date or in a half-migrated state. This is a source of pain for us and slows us down overall. We need a way to quickly apply code changes in an automated fashion to an entire microservice at once.
Project Description
.NET provides a compiler API, known as Roslyn, which can be used to modify code. This project should create a fluent Domain Specific Language (DSL) on top of Roslyn to ease its use, enabling us to quickly make modifications to the codebase.
We’ll provide an example codebase with two scenarios we would like covered, focusing on pattern changes required to perform dependency updates. The implementation should be in a .NET language, preferably C# or F#, using the Roslyn API to perform the code modification. The output of the project should be a reusable library implementing a DSL that can be used from C#.
Support will be provided by the InterAction product development team at LexisNexis.
End User Use Cases
The end users for this project are LexisNexis developers; they will use the library for the use cases below as well as many others, so it should be flexible enough for future use cases. Each refactoring will have two phases, first is a measurement phase to assess the impact, and the second is the refactoring phase which will modify code. Also, these are the base cases, the actual usage patterns are more complex and can be treated as a stretch goal.
Change Static usages to Instance
There is a library, AutoMapper, that changed its usage pattern from static to instance methods, and we need to adjust roughly 900 usages to the new pattern. The usage below and the provided example code use a placeholder version of the library.
Old Pattern Example
public class OldMappingPattern
{
public string? GetSomething()
{
int value = 42;
return StaticMapper.Map<int, string>(value);
}
}
New Pattern Example
public class NewMappingPattern
{
private readonly InstanceMapper _mapper;
public NewMappingPattern(InstanceMapper mapper)
{
_mapper = mapper;
}
public string? GetSomething()
{
int value = 42;
return _mapper.Map<int, string>(value);
}
}
Pseudocode for refactor
- Find all usages of StaticMapper.Map in instance methods
- For each usage
- Add a field to the parent class of type InstanceMapper
- If the parent class does not have a constructor, add one
- Add a constructor parameter of InstanceMapper and set the field to that value
- Swap the usage from the StaticMapper to use the field
Grouping Initializations
Another library, Autofac, paired with Autofac.Extras.Moq is used by the InterAction integration test suites to manage mocked dependencies across layers. Recent upgrades have made it so all Dependency Injection configuration must be done in a block at the start of the test. We need a way to gather these configurations together, preserving order, into a lambda at the start of the test method.
Old Pattern Example
public class OldInitPattern
{
public void TestStuff()
{
var di = new MockDependencyInjection();
di.Provide<IServiceA>(new ServiceA());
di.Provide<IServiceB>(new ServiceB());
var sut = di.Get<IServiceC>();
sut.DoStuff();
}
}
New Pattern Example
public class NewInitPattern
{
public void TestStuff()
{
var di = new MockDependencyInjection();
di.Initialize(config =>
{
config.Provide<IServiceA>(new ServiceA());
config.Provide<IServiceB>(new ServiceB());
});
var sut = di.Get<IServiceC>();
sut.DoStuff();
}
}
Pseudocode for refactor
- Find each test in the project
- For each test
- Create an Initialize invocation as seen in the New Pattern Example
- Find each Provide usage
- For each Provide usage
- Move the usage into the block in the Initialize invocation
Liskov Substitution Fixes
We have found numerous breaches of Liskov’s substitution principle while transitioning our backend API. We have different implementations of interfaces that break when used in the same manner. These cases are almost always caused by a NotImplementedException being thrown from implementations that do not support the functionality. To fix this, the interface and implementations should be split out so that an interface’s implementations only contain supported functionality.
Code examples would cloud the issue, so a description of structure will be used instead as an example.
Old Pattern Example
- Contract Namespace
- IContactRepository – repository interface for Create, Read, Update, Delete methods related to contacts
- GetContact – Gets contact by id
- GetContactsByAreaCode – Gets a list of contacts by area code, only supported by Implementation 2
- IContactRepository – repository interface for Create, Read, Update, Delete methods related to contacts
- Implementation 1 Namespace
- ContactRepository – IContactRepository implementation backed by the older API.
- GetContact – implemented
- GetContactsByAreaCode – throws NotImplementedException
- ContactRepository – IContactRepository implementation backed by the older API.
- Implementation 2 Namespace
- ContactRepository – IContactRepository implementation backed by the newer API.
- GetContact – implemented
- GetContactsByAreaCode – implemented
- ContactRepository – IContactRepository implementation backed by the newer API.
New Pattern Example
- Contract Namespace
- IContactRepository – repository interface for Create, Read, Update, Delete methods related to contacts
- GetContact – Gets contact by id
- IContactsByAreaCodeSource – interface for reading contacts by area code
- GetContactsByAreaCode - Gets a list of contacts by area code
- IContactRepository – repository interface for Create, Read, Update, Delete methods related to contacts
- Implementation 1 Namespace
- ContactRepository – IContactRepository implementation backed by the older API.
- GetContact – implemented
- ContactRepository – IContactRepository implementation backed by the older API.
- Implementation 2 Namespace
- ContactRepository – IContactRepository implementation backed by the newer API.
- GetContact – implemented
- ContactByAreaCodeSource
- GetContactsByAreaCode – implemented
- ContactRepository – IContactRepository implementation backed by the newer API.
Pseudocode for refactor
- Find all contract interfaces in Contract namespace
- For each contract interface
- Find all implementations of the contract interface across the implementation namespaces
- For each method on the contract interface
- Compare implementations to find any that just throw NotImplementedException
- If any implementations only throw NotImplementedException
- Create a new contract interface
- Move the method from existing contract interface to the new contract interface
- For each actual implementation
- Create a new implementation class, implementing the contract interface
- Move the implementing method from the old implementation to the new
- Copy any dependencies from the old implementation to the new
- Remove any orphaned dependencies from the old implementation
- Replace usages of the old contract interface method with usages of the new contract interface method.
Technologies and Other Constraints
- Implementation of the DSL may be done in either C# or F# but must be easily usable from C#.
- Must utilize the Roslyn compiler platform for parsing and modifying the code.
- The DSL codebase should include its own unit and integration test suite with at least 80% code coverage.
Sponsor Background
Our company is an innovative, global healthcare leader committed to saving and improving lives around the world. We aspire to be the best healthcare company in the world and are dedicated to providing leading innovations and solutions for tomorrow.
Merck’s Security Analytics Team is a small team of Designers, Engineers and Data Scientists that develop innovative products and solutions for the IT Risk Management & Security organization and the broader business as a whole. Our team’s mission is to be at the forefront of cybersecurity analytics and engineering to deliver cutting-edge solutions that advance the detection and prevention of evolving cyber threats and reduce overall risk to the business.
Background and Problem Statement
Today’s organizations are faced with fragmented and siloed information that is driving the need to easily connect to data across disparate media content sources, for instance YouTube or Twitter. More cyber security relevant information is being stored in digital formats, and the collection, organization, and security of these sources is a strain on labor and costs. Automatically performing preliminary analysis can help the organization to meet this challenge by unlocking hidden insights by revealing trends, patterns and relationships and uncovering facts validated by a human eye.
In order to assess cyber risk for the organization we have to collect and analyze information from a variety of Open-Source Intelligence (OSINT) sources - live feeds from social media, broadcast video streams and news articles related to cyber threats. These unstructured data sets are challenging to understand. They constantly change, making it difficult for even a team of people to monitor them 24 by 7. The volume of content even within a region or country is millions of tweets and hundreds of video and news articles a day, especially concerning a company with a global operational presence such as Merck.
As a risk manager or cyber threat analyst, information about attack vectors most commonly deployed in the wild by both criminal and nation-state actors is of great interest.
Project Description
We would like a student team to design and build a business security solution with a web-GUI which uses OSINT artificial intelligence to identify global trends, sentiment, and keyword mentions. It can analyze the data available in public sources such as video broadcast, social media, and websites to bring our cyber risk teams actionable insights.
The system would be able to analyze video, audio and image content for multiple entity types, simplify user training, and allow more effortless data fusion. Third party software solutions will be used for analysis. The goal of the project is to create a GUI and integrate various IT systems to demonstrate the capability. For example, extract text from YouTube channels and index it for further content search.
Technologies and Other Constraints
The solution can be developed in AWS, and specifically leverage Amazon AI/ML Services. The preferred cloud machine-learning platform is Amazon SageMaker.
Micro Focus IDOL or an alternative can be used for unstructured data analytics. IDOL Unstructured Data Analytics is an advanced search, knowledge discovery, and analytics platform. It uses AI and machine learning to leverage key insights stored deep within your unstructured data, including text analytics, audio analytics, video analytics, and image analytics.
The final product should be a web-based GUI that end users can use to search for a pattern and perform other analytics.
For model and GUI development, students can use their language of choice (but Python is preferred).
Other Resources
In a broader IT Security context please see: CARTA (Continuous Adaptive Risk and Trust Assessment) that allows organizations to predict, prevent, detect and respond to security threats by applying continuous visibility and analytics:
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
NetApp is a cloud-led, data-centric software company dedicated to helping businesses run smoother, smarter and faster. To help our customers and partners achieve their business objectives, we help to ensure they get the most out of their cloud experiences -- whether private, public, or hybrid. We provide the ability to discover, integrate, automate, optimize, protect, and secure data and applications. At a technology level, NetApp is the home of ONTAP (our custom storage focused operating system); cloud, hybrid and all-flash physical solutions; unique apps and technology platforms for cloud-native apps; and an application-driven infrastructure which allows customers to optimize workloads in the cloud for performance and cost.
Background and Problem Statement
Rust is a general-purpose programming language influenced by C++ that was created in 2006. It grew out of a personal project by Mozilla employee Graydon Hoare, and was sponsored by Mozilla until 2020, until the Rust Foundation was founded in 2021.
Amazon Web Services, Huawei, Google, Microsoft and Mozilla now support the foundation, and Google supports Rust in its Android Open Source Project. Notably, Rust was recently included in the Linux 6.1 kernel.
Benefits of Rust include:
- A high-performance language, created with the intention of marrying the flexible syntax of a high-level language with the hardware control and speed of a low-level one
- Parallelism
- Strong memory safety
NetApp uses a FreeBSD based operating system in its products. We would like to use Rust for future projects – both internally and to enable leveraging of open source.
Project Description
The goal of this project is to design, develop and test a FreeBSD kernel module that implements basic networking socket functionality written in Rust and run on a FreeBSD system.
References to current work in the area: https://wiki.freebsd.org/Rust
The team will use the prior work from the link above to compile and run a "Hello World" FreeBSD Rust kernel module. Once that is complete, the team will call FreeBSD kernel APIs in their kernel module to:
- Create a UDP socket (on a hard-coded IP address and port).
- Receive packets on the UDP socket.
- For each UDP packet received, either (or both):
- Echo the data packet data back to the sender on the UDP socket.
- Copy the packet data to an in-memory ring buffer. The contents of this in-memory ring buffer can then be read by running "cat" on a character device for the module (i.e., similar to how the prior work's "cat" on the device will display what was echoed to the device).
The implementation should then be tested/verified by running a simple socket program like netcat on a remote machine to send UDP packets to the node with the kernel module running. The payload of the UDP packets being sent should either be returned as an echo to the sender or seen by running "cat" on the character device to see the payload bytes in the in-memory ring buffer.
Technologies and Other Constraints
FreeBSD
Rust
Kernel modules
Networking sockets
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
SAS provides technology that is used around the world to transform data into intelligence. This project is sponsored by the SAS Data and Compute Services, and has a focus on leveraging computer science and Ethics principles to mitigate bias in AI Systems. Broader impact of this project cuts across law, social science and technology; improving fairness and reducing the negative ethical consequences of AI in our world.
Background and Problem Statement
AI systems have been known to exploit patterns in data to improve their predictive power. If these patterns are biased, then these systems would be biased. From self-driving cars to Customer KPI prediction, it is beneficial to anticipate and erase bias as early as possible in smart systems. What if an AI system for customer marketing is trained an American data only, but British customers spend twice as much as their American counterparts? What does equal representation of race, gender or ideology mean in a data setting? This project would explore these issues to try to answer the following research questions:
RQ1: Can we detect a biased dataset?
- RQ1a: Understand the different scenarios of bias in data (see https://www.scuba.io/blog/data-bias-why-it-matters-and-how-to-avoid-it) for some ideas
RQ2: How can we detect bias in data early enough to prevent the creation of bias in AI models?
- RQ2a: Are existing bias detection tools sufficient in ensuring fair AI?
- RQ2b: How can we create a more efficient early bias warning strategy?
Project Description
The goal of this project is to create a web application where users could upload their data or set of datasets and use your algorithms to early detect bias. You can do this with a specific target variable identified as a supervised learning approach, but you could also add the ability to do this in an unsupervised way by comparing against expected distributions and identifying differences from those distributions (age, ethnicity, gender, religious affiliation, etc.). Either or both approaches are interesting and provide the user with useful information.
Could you visualize the data in such a way that people not familiar with the domain of data bias could understand that the data may be biased?
If you picked up a new dataset, could you provide a method to discover whether or not a dataset is biased and visualize that so people could understand?
Could you also provide assistance for people to understand why bias is important so that they become educated enough to be able to work properly with datasets in a way that could prevent bias in future reports or algorithms or dashboards they use in a system?
Could you implement an "early warning system" such that users that select a dataset could understand the proper usage of this dataset so as to prevent data bias?
If you complete this initial phase, you can move to the next step which is to apply algorithms that can correct for bias. More details will be supplied in the references.
Technologies and Other Constraints
- Python should be the language you use to develop your underlying code.
- Storage - any preferred storage that the students can work with.
- UI can be a custom Javascript Web application in React. You can also use a reporting app if you would like for producing a report on Bias such as Tableau, which is free.
- Datasets can be CSV structure datasets that are pulled from Kaggle to work on for detecting bias.
Sponsor Background
Bandwidth is a software company focused on communications. Using cloud-ready voice, messaging, and emergency service connectivity, Bandwidth’s platform is behind many of the communications you interact with every day. Calling mom on the way into work? Hopping on a conference call with your team from the beach? Booking a hair appointment via text? Our APIs, built on top of our nationwide network, make it easy for our innovative customers to serve up the technology that powers your life.
Background and Problem Statement
At Bandwidth, Whole Person Challenges are a part of our culture. Challenges are aimed to promote teamwork, camaraderie, and good ol’ fashioned competition as well as giving employees the opportunity to better themselves in mind, body, and spirit. Each challenge has its own theme, required workout, a mind component (ex. reading a book, or studying on Udemy), as well as a challenge aimed to improve your spirit (ex. organizing your home, or volunteering). At the end of the challenge, if an employee completes all of the requirements, they will earn an extra PTO day.
Currently, Bandwidth uses an antiquated process involving Google forms and spreadsheets to track participation in our challenges. It’s not a very forgiving interface and requires participants to manually add in workout logs or hours spent toward the challenge on a daily basis. Today, the majority of bandmates already track their workout time/miles in Strava making the previous step superfluous.
Our challenges are a lot of fun and receive a lot of interest from employees. As such, we want to improve our technology in how our participants keep track of their challenge progress.
Project Description
We want to build an internal web app that makes it easier to track “Body” (aka fitness) data for the challenges, along with completion of the “Mind” and “Soul” tasks. The goal is to make it simple to enter workout hours or mileage by creating integrations with popular fitness tracking tools such as Strava (MVP) or Runkeeper (stretch).
Once the integrations are built, we want to gamify the experience. Think a leaderboard page, notifications when you’ve been passed / passed others, or telemetry around what it will take to finish in first.
If time allows, there is an opportunity to build another integration between Strava and Racery for our Muddy Souls Tour (running/hiking/walking). Details to come.
Technologies and Other Constraints
We will want to host this in AWS (we will provide students an AWS account and credentials), and it will need to be a full-stack application. We recommend React for the front-end, and Node or Python for the backend, but ultimately the team can choose technologies they are most comfortable with.
Sponsor Background
I am both a masters and bachelors graduate of NCSU’s computer science games concentration, and have been working at Epic Games since graduating. As part of my work at Epic Games, I assist Unreal Engine developers by offering technical solutions and examples to demonstrate core features of the engine.
Background and Problem Statement
Epic Games continuously works and improves upon the Unreal Engine, adding new features and improving existing ones from release to release. While official documentation is helpful for understanding the features, oftentimes a practical implementation in a real game, and not just a sandbox environment, is the best way to demonstrate how to use them. These projects, while substantially more useful, do take longer to make, and often suffer from being too generic to be applied in a real game project. The goal here is to make a compelling game that also clearly demonstrates some of the editor utility functionality present in Unreal Engine.
Project Description
An Unreal Engine game/plugin that demonstrates actual implementations of the below listed features in a real game of their design.
Core Features:
The Unreal Engine contains many features designed specifically to help develop games, and these features are collectively known as ‘Editor Features’. Some examples are Editor Utility Widgets, and the Tool Menu System. Editor Utility Widgets are drag-and-drop designed interfaces where users of the engine can create their own windows with buttons, labels, sliders and more, and often are used to add functionality to assist with editing levels or performing common editor tasks. The Tool Menu system allows for the editing of the editor’s tool menus and right click context menus. This effectively allows for the core editor window itself to be modified to better suit the needs of the developer, and even add new entries to menus for project-specific tasks.
- Core features should be implemented separately from the game itself in an Unreal Plugin, so they can be reused in other projects, and therefore not tied to a specific game
- Editor Utility Widget - To assist with level design, an editor utility widget should be present that allows for specific actors to be marked as selected in the current level based on at least the following selection criteria:
- Actors that are within a user inputted distance of a user-specified light source type, and a way to invert this logic to find actors outside of this range
- Actors that are not touching the ground, or other collision under them
- Actors that are overlapping with other solid actors
- Tool Menu System - To remedy design errors, add a Tool Menu that has easily accessible buttons to perform at least the following functions:
- Set an internal flag on any actors that exceed a minimum distance from any light source
- Move ‘floating’ actors down until they are touching the ground or other collision
- Try to move overlapping actors away from each other until they are no longer colliding, or provide an error message to the user if they cannot be fully separated without creating more collisions
The Game:
The genre and gameplay is entirely up to the team, however it must at least implement the following features to support the core features:
- A variety of at least 5 actor types, to provide some reasonable amount of actors to interact with
- At least 3 different types of lights of differing colors to better distinguish them
- At least 2 levels of reasonable difference from each other to demonstrate universality of the tools. To show this reasonable difference, the levels must meet the following criteria:
- At least 1 example of each of the core ‘problems’ outlined in core features should be present in each level, with more being preferable
- Any stretch goals for additional actor selection criteria (See stretch goals below) should also ideally have a level or subset of a level dedicated to showing their implementation
Documentation:
As the end goal is a demonstration of editor features, having documentation of what to look for is important. The implementation of the following features should be clearly documented, with clear instructions on what to look for in your designed levels:
- Editor Utility Widget:
- Where is the asset located in your project’s folder structure
- Step-by-step instructions on how to use your widget for each selection criteria (including any additional ones implemented as stretch goals)
- Any potential failure cases, and what to look out for should no actors be selected
- Tool Menu System
- How are the menu edits applied? Automatically when the editor starts, or should a script be executed?
- What menu is edited, and what series of clicks are needed to find it?
- Any potential failure cases, and what to look out for should the action not be possible
- The Game
- List the various actor types, and a clear description of how to distinguish them in the levels
- For each level demonstrating selection criteria, clearly explain where in the level the various ‘problems’ are located, and the expected behavior of the selection criteria given the level’s layout
- Stretch Goal: Detail Panel Customization
- If implemented, clearly list which properties should be visible given the selection criteria
- Stretch Goal: Python Integration
- If implemented, list where your scripts are, and provide clear instructions on how an end user would create a new script
- Explain your API choices internally, and how end users could tap into them, if needed
Stretch Goals:
- Additional selection criteria - Depending on the genre of game designed by the team, there are hundreds of potential selection criteria that can be useful. Adding more preset types to the list will offer this functionality to other games too. Some examples include, but are not limited to:
- Select actors visible from the initial camera’s perspective
- Select all actors of a certain asset type
- Select all actors that are only visible in the editor (ex. Control actors)
- Detail Panel Customization - On the editor utility widget, add a customized detail panel to dynamically hide properties not relevant to actor selection criteria
- Python Integration - Add support for custom actor selection on the editor utility widget, using the built-in Python functionality to determine if an actor should be included. Additionally, if the detail panel customization stretch goal is taken, adding Python support for selecting which properties to show is also a bonus.
Technologies and Other Constraints
- Unreal Engine (Requirement) - While free to use, users must accept the EULA to use the software (https://www.unrealengine.com/en-US/eula/unreal)
- Art/Audio tools (flexible) - There are no explicit requirements for tools used to create assets, but any external assets used must be free for commercial use, or owned/created by the team
Sponsor Background
Katabasis is a non-profit organization that specializes in developing educational software for children ages 8-15. Our mission is to facilitate learning, inspire curiosity, and catalyze growth in every member of our community by building a digital learning ecosystem that adapts to the individual, fosters collaboration, and cultivates a mindset of growth and reflection.
Background and Problem Statement
Access to tutoring services is a key metric in determining academic success for students. Most students need some form of supplementary assistance beyond the instruction they receive during class time. However, the pricing and availability of these services can be absolutely unaffordable for some families, where tutoring services can cost as much as (or more than) monthly rent. That being said, tutors themselves are workers that need to be paid, and so a large part of the problem is simply a shortage of tutors nationwide. Automation and digital tutors are a natural proposed solution, but children have consistently shown they respond better and achieve better results with human interaction. With all this in mind, Katabasis is seeking to develop a Metahuman tutor that can achieve the best of both worlds.
Project Description
Katabasis is seeking to develop a Metahuman tutoring interface to assist young children with basic math competencies (e.g., multiplication, division, fractions). In order to achieve this, we want the team to develop an interface to be centered around a Metahuman agent (created with Unreal Engine 5), who will be posed questions by a user, and will respond to them as naturally as can be achieved. We want the nonverbal output of the Metahuman to be as compelling and indicative as its verbal/text output. Here is a summary of the core features we are looking for:
- Metahuman Interface: The core frontend of the project featuring fully developed Metahuman(s) created using Unreal Engine 5’s MetaHuman framework.
- Diverse Metahuman Agent: We want the team to develop a Metahuman agent that can interpret user questions around the subject matter, and respond naturally, both in voice/text and in expressions. The regions we are targeting feature many different ethnicities, but are predominantly African American, Hispanic/Latino, and Native American. We want the agents created to be people that the children can relate to and look and feel like people they know.
- Nonverbal Expressions: We want the agent to have a range of nonverbal expressions, from facial expressions showing confusion, confidence encouragement, etc. to gestures indicating the same (e.g., thumbs up, smile, shrug, clapping). These expressions will be mapped to the NLP insights on the conversation being had to display them at the appropriate moments.
- Rapport Building: Talking to users to make them feel more comfortable, and make the agent feel less automated and more personable.
- Information Gathering Questions: Ask targeted questions to get more accurate measures for comprehension level and subject matter they are struggling with.
- Natural Language Processing: The core backend of the project that will be processing a user’s input and generating the correct output to be shared via the Metahuman Agent.
- Sentence Structure Analysis: Sentence structure of the input will be processed to help strip out the less relevant words of a sentence and focus on the subject matter content.
- Response Phrase Composition: In addition to a library of prewritten responses, the agent should have the capacity to compose responses to react to specific input prompts provided by users.
- Interface Management: In addition to being able to create speech patterns for the MetaHuman agent, we want the ability for parts of the interface to be interactable using specific word triggers, and the interface in Unreal should have the proper hooks to make this happen correctly.
Technologies and Other Constraints
The Metahuman agent will be created using the Unreal Engine Metahuman Creator tool suite. This will require using Unreal Engine 5 and will likely involve at least a little bit of C++ coding to handle some backend code. The interface built around the Metahuman agent can take whatever form the team prefers, but most likely the easiest way to do so will be by building it within UE5 itself.
Additionally, this project will have the team delving into natural language processing (NLP) to parse user input and generate tutor responses. Most of this will likely happen in Python since there are many robust libraries with NLP tools for use in the language.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Katabasis is a non-profit organization that specializes in developing educational software for children ages 8-15. Our mission is to facilitate learning, inspire curiosity, and catalyze growth in every member of our community by building a digital learning ecosystem that adapts to the individual, fosters collaboration, and cultivates a mindset of growth and reflection.
Background and Problem Statement
In today’s education systems, young people are very rarely taught sensible financial lessons, and can often be put into situations to make important financial decisions before fully understanding their repercussions. These problems are felt even more in areas where there is less to go around, and can lead to compounding cycles of generational poverty, among other things. We want to find a way to teach children in late middle school and early high school (right around the time they may be starting to develop financially) the principles that go into sensible financial decision making and increase financial literacy in these groups as a whole.
Project Description
Katabasis is seeking to continue development on our financial literacy education game, Money Making Mateys (formerly Taxing Towers). In the current state of the game most of the core systems have been fully implemented, including features such as time and money management, islands representing tangible and nontangible assets, personal skill development, and a loan/borrowing system. For this semester’s project, we want our team to flesh out these existing systems, focusing on designing the core gameplay loops, and reinforcing the financial literacy education goal. Specifically, here is a summary of the core additions we are seeking:
- Timeline Implementation: The representation of time is very important for the functionality of many game systems, and the current system is rather barebones. We want our team to flesh this out with a fully-fledged Timeline system that can track time effectively, be interacted with by many classes easily, be modified simply (increasing/decreasing speed, pausing, etc.), and integrates well with the existing infrastructure.
- Financial Fidelity: We want the financial systems that we are teaching and demonstrating through the game to have greater fidelity to real-world interactions. In particular, we want to avoid effective gameplay patterns that could lead to poor real-world financial decision-making. To achieve this, we will want the credit score system to be more fleshed out, and have more interactions (both inputs and outputs) with the core gameplay loop. Such interactions could include (but not be limited to): a more in-depth loan system that will react to your credit rating (varying interest rates, loan amounts, etc.), certain islands locked behind a certain credit rating (necessitating increasing credit score), and maybe even more predatory loan practices, realistically implemented (to highlight the dangers and disadvantages of them).
- Achievement System: In order to promote different play patterns and encourage experimentation, we want an achievement system to be implemented, rewarding reaching certain milestones and can be analogous to real-world financial goals.
- Random Events: To simulate real-world unexpected expenses (accidents, fluctuating markets, medical expenses, etc.), we want random events to be implemented in the game, along with a corresponding mitigation mechanic, in the form of insurance. This will likely be explained thematically as some sort of sea monster attack, but the team is free to be creative with the particulars. For both educational and gameplay reasons, these events will likely be seeded to happen more frequently than necessarily happen in reality, and could even be tailored to highlight strengths and weaknesses in a player’s strategy.
Technologies and Other Constraints
This game is made in the Unity game engine, and as such, team members will be expected to operate within it and produce C# code to supplement.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Dr. Stallmann is a professor (NCSU-CSC) whose primary research interests include graph algorithms, graph drawing, and algorithm animation. His main contribution to graph algorithm animation has been to make the development of compelling animations accessible to students and researchers.
Background and Problem Statement
Background
Galant (Graph algorithm animation tool) is a general-purpose tool for writing animations of graph algorithms. More than 50 algorithms have been implemented using Galant, both for classroom use and for research.
Other existing algorithm animation systems and tools are limited in one of two ways.
- The user can view animations but has limited control over problem instances and details of the animation. These apps (usually web-based) do not allow a user to implement different algorithms.
- The system is designed for production of sophisticated animation, but the animation API is complex. Creating a new animation may require months of effort by a skilled programmer.
The primary advantage of Galant is the ease of developing new animations using a language that resembles algorithm pseudocode and includes simple function calls to create animation effects. In Spring 2016, the last programming assignment in CSC 316 was to create two animations, one of an algorithm discussed in class and another of an algorithm outside the scope of class. Several of these animations (most notably Boruvka’s MST algorithm and Quicksort) are now (with minor modifications) part of the collection of algorithms in the Galant repository. A paper about this experience and student reflections on it was published in the education section of the IEEE Journal on Computer Graphics and Applications.
The most common workflow is
- Create a graph either externally or using Galant’s graph editor
- Upload an algorithm animation program created externally using a program editor
- Compile the program and execute it using arrow keys to step forward and backward in a list of animation events
Problem statement
Deployment of the current implementation of Galant requires that a user has git, Apache ant, and runtime access to a Java compiler; it is also complex and includes many unnecessary features. While it is technically platform independent, behavior differs on different platforms; any modifications must be tested on Mac, Windows, and Linux.
The current implementation is also unnecessarily complex – it includes many GUI features that are not essential to the primary functionality of Galant. Code for these features is poorly documented and difficult to maintain and modify.
Algorithm animation code is translated to Java and then compiled by a Java compiler; this creates two major problems.
- It may not be easy to associate Java compilation errors with the original animation code.
- Some Java runtime exceptions, such as null pointers, can be interpreted only by someone familiar with the Galant implementation.
Project Description
The goal of this project is to port the core features of Galant to the Web. A web-based JavaScript implementation would have several advantages.
- Users could run Galant in any browser – no need for a download or special tools.
- The code base is likely to be much simpler, for two reasons: (a) unnecessary features would not be included; and (b) JavaScript has features that would simplify implementation of the GUI.
- Since much of the functionality of the algorithms and their animations can be implemented directly in JavaScript, errors will be much easier to track down.
The team is expected to implement a web-based JavaScript application that allows a user to
- Upload a graph from a file in a simple format. The graph is drawn in its own window.
- format specifies relative locations of nodes and the two endpoints of each edge
- when uploaded, the graph is drawn in a window
- each node is a circle containing its id (number)
- each edge is a line/arrow connecting the endpoints
- Upload source code for an animation. The code is in its own window.
- Run a specified animation on a specified graph.
In addition to the sources of the Java implementation, example graph and algorithm input files will be provided.
Technologies and Other Constraints
Students would be required to learn and use JavaScript effectively to reimplement Galant functionality. Familiarity with Java will also be useful to read and understand the current implementation.
Sponsor Background
Wake Technical Community College (WTCC) is the largest community college in North Carolina, with annual enrollments exceeding 70,000 students. The pre-nursing program in the Life Sciences Department runs a two-course series on Anatomy and Physiology, where this project will be used, with enrollments exceeding 800 annually. Additionally, this project is expected to assist over 1,000 biology students when fully implemented.
Background and Problem Statement
Biology students as well as pre-nursing students need to understand how the body carries out and controls processes. Proteins have a diverse set of jobs inside cells of the body including enzymatic, signaling, transport, and structural roles. Each specific protein in the body has a particular function and that function depends on its 3D conformation. It makes sense then, that to alter the activities within cell or body, proteins change shape to change function. One important example of this is hemoglobin. Hemoglobin is a huge protein found inside red blood cells and its primary function is to carry oxygen and carbon dioxide to and from cells of the body, respectively. Structures inside hemoglobin bind to oxygen dynamically at the lungs and then release the oxygen at metabolically active tissues.
As a beginning biology or pre-nursing student this is a difficult process to imagine from a 2D image in the textbook, and we have worked to create a tool that helps visualize protein dynamics using augmented reality. In various iterations the tool has supported the use of AR tags to change the environmental factors that influence protein structure and function, basic animation of structural changes of 3D protein structures, and the creation of structured activities to support educational use—although never all at the same time. Integrating and enabling all of these features, alongside several new ones to make the tool more suitable for online education, is the emphasis of this project. In particular, supporting decentralized collaborative AR experiences for teams of students or students and instructors through the use of animation features, the use of multiple AR tags, and connecting to the instructor’s assignment specification and grading views will be the main goals.
Project Description

What are your initial thoughts about a potential solution that addresses the problem presented above? Briefly describe your envisioned software solution to be developed by the student team. Use cases and examples are useful. Provide insight into how this potential solution will be beneficial to end users.
The existing version of the AR app has been implemented in React, and allows instructors to upload molecule crystallography files (.cif), define molecule states and environmental factors, and specific environmental factors that trigger the molecule states. Instructors can additionally create lesson plans comprising questions that students can view and submit for grading. This represents a pretty full featured experience, although there are a number of remaining futures and a handful of issues that remain to be addressed. The aim for this semester will be to design and implement some missing features as well as address some remaining issues in the existing code. The main outstanding features and development tasks (in rough priority order) are:
- Incorporating a preview feature when uploading molecules.
- Implementing a keyframe animation system to emphasize/highlight molecular changes as they occur in response to changes in environmental factors.
- Improved error checking and messaging on the front end and back end.
- Developing new functionality for more complex Boolean expressions for environmental factors to trigger molecule state transitions.
- Creating a use case for generating and adding new AR tags.
- Creating a screenshot upload question type for lesson plans with associated functionality for instructors and students.
- Refactoring code to improve maintainability (specifically in the AR view where several functions are duplicated), including migrating some lingering Angular code to either React or the backend.
Technologies and Other Constraints
- This must be a web-based app with AR views supported on mobile devices and instructor/backend systems on desktop browsers.
- React (existing)
- Angular (almost entirely phased out)
- Three.js (existing, can be replaced)
- AR.js (existing, can be replaced)
- LiteMol (existing, can be replaced)
- Spring (existing)
- Gradle (existing)
Students will be required to sign over IP to sponsors when the team is formed
Project Archives
| 2026 | Spring | Fall | |
| 2025 | Spring | Fall | |
| 2024 | Spring | Fall | |
| 2023 | Spring | Fall | |
| 2022 | Spring | Fall | |
| 2021 | Spring | Fall | |
| 2020 | Spring | Fall | |
| 2019 | Spring | Fall | |
| 2018 | Spring | Fall | |
| 2017 | Spring | Fall | |
| 2016 | Spring | Fall | |
| 2015 | Spring | Fall | |
| 2014 | Spring | Fall | |
| 2013 | Spring | Fall | |
| 2012 | Spring | Fall | |
| 2011 | Spring | Fall | |
| 2010 | Spring | Fall | |
| 2009 | Spring | Fall | |
| 2008 | Spring | Fall | |
| 2007 | Spring | Fall | Summer |
| 2006 | Spring | Fall | |
| 2005 | Spring | Fall | |
| 2004 | Spring | Fall | Summer |
| 2003 | Spring | Fall | |
| 2002 | Spring | Fall | |
| 2001 | Spring | Fall |