Projects – Spring 2010
Click on a project to read its description.
Redesign of Login Toolbar – Wolf Launcher 2.0
Background
AT&T’s Global Technology and Tier 3 (GT3) organization is responsible for developing tools and automation for its Managed Network Services product line. The number of client networks and devices has been progressively growing over the past 10 years. Managing these devices has become increasingly more challenging. The Login Toolbar, that was developed 4 years ago, was a tool created to help associates gain access into management servers and client devices more efficiently. The continued development on this tool has become cumbersome and inefficient. The Login Toolbar is a very effective tool for device access, however, it can benefit from a redesign that is more modular and having a more robust framework. The current code is written in TCL/Python with SQL direct calls and is a Thick-Client running on individual machines.
Project Description
This project will investigate the redesign of the current tool into a more modularized framework that will allow for the addition/removal of components without major code revision and deployment. The tool will need to be user friendly, interactive, and security conscious. It will also need to be easily administrable by the developers.
Login Toolbar Description
The Toolbar is a launching platform that can perform several tasks. The first feature is authorized use of the Toolbar. This ensures the user should be allowed to use the toolbar. After the being authorized, The Toolbar is configured by the user with their login/passwords for both Server Access and End-Device Access such as TACACS. This information is stored locally on a user’s machine encrypted for security. The user also has the ability to choose their method of access such as X-Term/Putty/SecureCRT – whichever is available on the local machine. After the User setup is completed, the user now has the ability to access a server by entering it manually or by using the Drop-Down menus. The Toolbar will launch the personal access tool of choice and login the user automatically. They also have the ability to connect to an end-user device by entering a device. The Toolbar, using their user settings, will launch the access tool, log the user into the appropriate server for the device, and then runs a script on the server that logs the user into the device using the pre-defined user access information.
The Toolbar’s code is the intelligence behind the whole process. It uses SQL calls to figure out IP addresses for servers and also what servers a particular Device is managed off of. This automation allows the users to quickly access different servers/devices by removing the repetitive steps of launching an X-term tool, typing logins for servers/devices over and over again, as well as determining which devices are managed if it is not all ready apparent. There is approximately 5-10 second reduction per incident/issue and when you are looking at 1000s of incidents/issues a day, this is a large time saver for users and the company as a whole.
Preliminary Project Goals
- Redevelop the main code to make additional modules easier to deploy
- Create Module to interact with Internet Explorer and FireFox for Favorites
- Create Module to look for code upgrades and new modules dynamically
- Create Installation package and launching capabilities
Preliminary Project Requirements
Thick client
- Run on Windows XP operating systems (Vista if Possible)
- Perl/XML/Web Calls (Compiled for security)
- Must be modular in nature
- More Detailed Requirements to follow after Demonstration/Discussion
Benefit to NC State Students
This project will provide an opportunity for students to look at an existing tool, gather the strengths and weaknesses, and create a new tool that incorporates new processes and languages such as PERL, XML, web calls, HTML.
Web Widgets for the IP Phone
Background
Cisco's Voice Technology Group (VTG) has recently released our newest line of IP Phone models, including the 9971, 9951, and more. The new phones will feature a web browsing application, which includes the ability to launch "Web Widgets," standalone applications created using web technologies (XHTML,CSS,JavaScript) which run in a special browser window and appear as native applications (see W3C Widgets spec, Opera Widgets, or OSX Dashboard Widgets). We are providing the ability to create web widgets so that 3rd party developers will be able to more rapidly develop applications for the phone, as well as leverage the special capabilities gained from developing on the web. As a result of creating this new browser and widget framework, Cisco would like a number of sample applications to showcase the browser.
Project Description
In order to provide a number of sample applications available with the browser, we would like the NCSU team to create for us 4-5 web widgets (or more if time permits) for use on the phone. The widgets will showcase a variety of tasks in order to demonstrate the flexibility of developing web widgets. These widgets will include stand alone widgets which run locally, AJAX based applications, mashups of various web 2.0 services, etc. The widgets should be able to conform to the limitations of working on a small screen device. Students will work with the Cisco browser team to iron out requirements and design of the widgets before going into development, through an iterative development process.
Example list of widgets:
RSS ReaderGoogle Maps
Stock Ticker
Weather App
Calendar App (Google calendar?)
To do List/Sticky Notes
Slideshow (Picasa, Flicker, etc mashup)
Currency Converter
...etc
Project Skills
The following skills will be useful for a student of this project, but can be ramped up during development. Many of these skills are highly desirable to corporate recruiters.
-Web Widgets-XHTML
-CSS
-JavaScript
-AJAX
-jQuery
-Google API
-Other web technologies
GreenLogo*
Every day our habits contribute to the creation/generation of Carbon Dioxide, which many believe is affecting our climate. How warm or cool our homes are, how much we travel, what we eat – it’s pretty complicated … no actually it’s really complicated. We all need to work together to make a difference. It’s social, it’s technical, and it needs our attention.
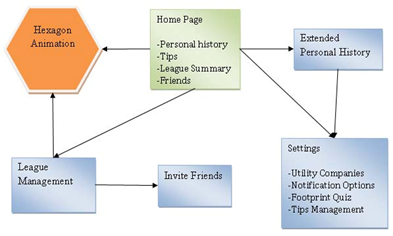
In the fall of 2009, the 492 Green Logo group created a Facebook application to promote reducing our nation’s carbon footprint. Utilizing “screen scraping” to capture the user’s power consumption information, the Facebook app is designed to create a social and fun incentive for users to change their daily habits, through competition and collaborative support from the expansive social media group community. In addition to understanding the existing code base which resides on the Amazon EC2 Cloud, there are several extensions and enhancements that are needed before opening the app to a broader audience and continuing its existence beyond a 492 project:
- Add News Feed, Recent Activity, and Status Updates to current Facebook application backend environment.
- Expand competition scoreboard (see Flash presentation below) and create league to league competition.
- Expand and open a “Tips” database via service-oriented architecture, using SOAP/WSDL so other organizations specializing in energy reducing tips can add organized tips for circulation via GreenLogo.
- Create branding opportunities for application sponsors such as Progress Energy or Sierra Club.
- Create advertising placement (e.g., banner, tower, Google AdWord) for targeted energy reducing products.
- Prepare source to become an Open Source project on SourceForge or equivalent.
- Abstract existing Facebook application so Open Social Sites (e.g., MySpace, Orkut, Ning, etc.) can use GreenLogo backend.
- Correct identified bugs from fall project work that are required for forward progress.
The students will also be required to maintain a clean, engaging, and visually stimulating user experience that is consistent with what Facebook users expect from an “app” and Web 2.0 technologies. Two members from the previous semester’s team will be available as liaisons to support the continued development of this application.
*Sponsor Information: Cleanbit Systems, Inc. is a startup company with a mission to educate users on the environmental impact of their carbon-based energy usage through Web 2.0 social interaction. By presenting images, tips of the day, and individualized information on energy consumption in a fun and competitive environment such as Facebook, Cleanbit is working to encourage reduction of energy consumption. GreenLogo is a placeholder name for the application.
Enhanced Version Control Management
DataFlux offers enterprise master data management solutions and provides its customers with software tools to help improve enterprise data quality. These solutions and tools allow customers to rapidly assess and improve problematic data.
DataFlux jobs are stored in an XML format and use a DataFlux Job Viewer as one component of an IDE. This Job Viewer does not integrate with version control packages such as CVS or Subversion. The goal of this project is to create a stand alone user interface that will, at a minimum, permit users to do version control of XML expressed objects and side-by-side comparisons of file differences. A more challenging goal is to enhance file differencing to a logical level so that users could tell for example that a job node changed, and the change was for property X. In other words, enhance the differencing algorithm to make it easier for users to see that specific properties of an XML expressed node have been changed, or that nodes have been added or removed, etc., rather than simply displaying line-by-line differences. As a simple example, consider the following property defined in the job's XML:
False
The enhanced differencing algorithm, rather than simply telling the user that a change or conflict has occurred at line 2, would abstract that based on the tag (in this case,
More formally, the team must implement logical differencing for DataFlux objects represented by an XML schema such that updates to files are presented to end users as differencing information in terms of XML objects and properties that have been modified and not just a line number.
The stand alone version control interface with logical file differencing will need to integrate with Subversion and/or CVS, be programmed in C# and use the Windows Presentation Foundation UI packages so that it matches the architecture of other software at Dataflux.
Team qualifications:
- Experience with subversion or CVS
- Experience with XML
- Knowledge of C#, .Net framework, and Windows Presentation Foundation graphical package (or willingness to learn).
DataFlux, a wholly owned subsidiary of SAS, is headquartered Cary, NC, and provides end-to-end data quality integration solutions that enable companies to effectively analyze, improve and control their data. (http:www.dataflux.com).
Blackberry Server Interface
Duke Energy financial systems are critical to the company’s operation and require 24/7 maintenance. As a result, it’s necessary for the support team to handle issues remotely, at a moment’s notice. The students will create a mobile application that will be used to resolve support-related issues remotely. The platform for the mobile application will be a Blackberry. Functionality of the application will include the ability to start/stop Windows 2003/2008 services; retrieve server specifications (such as disk space, memory, CPU, uptime, etc); and the ability to start/stop scheduled tasks. Students will use the Blackberry SDK, which provides emulators, negating the need for a physical device. The user interface on the Blackberry could either be a true Blackberry application or a web page. A server component with database is required as well. Additional challenges include developing a reporting capability for auditing user activity. The technology to be used will be .Net/C# and SQL Server. Students are encouraged to be creative in the design of the system.
Stress Test Code Modification Tool
Background
Celerra is the brand name of EMC’s Network Attached Storage (NAS) products. These products are designed to provide network based access to files over a number of network protocols (CIFS, NFS, ftp, http). Celerra systems range in size from small systems supporting dozens of users to large, enterprise wide systems supporting thousands of users.
In our RTP Software Development Center we develop a wide range of software for Celerra, but more importantly we perform extensive testing of the product in its operating environment. Over the years we have developed a comprehensive set of functional and stress tests that are automated. Automation, however, requires an operating environment, called a framework, which provides test management, test operational control, operating environment stability, test logging, and results analysis.
We have recently begun using new test frameworks which will improve the operation environment, allow the integration of tests from different organizations, and let us keep using tests in existing frameworks during the conversion/consolidation process. This project will develop an automated, or at least a semi-automated, tool to help the conversion process for a number of our stress test suites.
Project Scope
We desire to develop an automated tool which will make the 47 existing stress test suites more portable between test frameworks and more functionally correct by eliminating the need for a shell wrapper (called the “SC” file) along with adding the Perl directive “use strict;” to the test suites. The high points of the tool’s capabilities should be:
Stage One:
- Find and read a model file associated with the test suite
- From the model file, get the list of required Perl module files and add syntax to the test suite to have the files compiled or sucked in at runtime
- From the model file, get the list of user parameters
- Add code to get the parameters read into a Perl hash by a special Perl method
- Change all references to parameters in the test suite to be hash references to the parameters
- Change the model file to remove the line with the SC file name
- Produce a summary log of actions taken
Stage Two:
- Find improperly scoped variables and scope them. Execute this as an iteration until no more improperly scoped variables can be fixed automatically. This part will be tricky and will require some depth of understanding of Perl syntax.
- Produce a summary log of action taken.
- Produce a summary of improperly scoped variables, and usage locations, which could not be fixed automatically.
Materials Provided
- A tree of Perl module stubs, test suite model files (actual ones), and test suite example files will be provided. The files in the provided trees will be somewhat depopulated to protect sensitive test code, but should prove sufficient to evaluate and handle all “real life” conditions during the development / testing process.
- At iteration milestones, or on demand, the tool can be run by the EMC contact over the real, full set of test scripts and results provided back for additional debug and analysis.
- Stub files of the Perl modules (names will be valid, but contents will be depopulated) will be provided as necessary for compiling if the students choose to use that method in the stage two problem.
Benefits to NC State Students. This project provides an opportunity to attack a real life problem covering the full engineering spectrum from requirements gathering, to research, to design, and finally implementation. This project will provide opportunities for creativity and innovation. EMC will work with the team closely to provide guidance and give customer feedback as necessary to maintain project scope and size. The project will give team members an exposure to commercial software development.
Benefits to EMC. As storage usage worldwide continues to grow exponentially, providing our customers with the tools and features they need to better understand and manage their data is critical. All of this content complicates the role of the quality engineer in having to maintain and use the proper tests when needed. This tool, once complete, will allow important stress tests to be used across multiple platforms and in multiple test frameworks.
Company Background. EMC Corporation is the world's leading developer and provider of information infrastructure technology and solutions. We help organizations of every size around the world keep their most essential digital information protected, secure, and continuously available.
We are among the 10 most valuable IT product companies in the world. We are driven to perform, to partner, to execute. We go about our jobs with a passion for delivering results that exceed our customers' expectations for quality, service, innovation, and interaction. We pride ourselves on doing what's right and on putting our customers' best interests first. We lead change and change to lead. We are devoted to advancing our people, customers, industry, and community. We say what we mean and do what we say. We are EMC, where information lives.
We help enterprises of all sizes manage their growing volumes of information—from creation to disposal—according to its changing value to the business through information lifecycle management (ILM) strategies. We combine our best-of-breed platforms, software, and services into high-value, low-risk information infrastructure solutions that help organizations maximize the value of their information assets, improve service levels, lower costs, react quickly to change, achieve compliance with regulations, protect information from loss and unauthorized access, and manage and automate more of their overall infrastructure. These solutions integrate networked storage technologies, storage systems, software, and services.
EMC's mission is to help organizations of all sizes get the most value from their information and their relationships with our company.
The Research Triangle Park Software Design Center is an EMC software design center. We develop world-class software that is used in our NAS, SAN, and storage management products.
EMC where information lives.
Social Networking Concepts Applied to Creation & Maintenance of a Configuration Management Data Base
Background
First Citizens Bank maintains an enterprise-wide business application portfolio that includes over 400 software applications running on a multitude of mainframe and server platforms. This portfolio supports all aspects of bank operations including the operation of many of our client banks. First line technical support is provided by an internal IT helpdesk consisting of several helpdesk specialists. Both functional and infrastructure changes are made daily. Application development and support are provided by an internal IT team as well as external vendors. A change/incident/problem management tool is used to administer and track incidents and problems in the application portfolio and to manage change approval and scheduling processes. A daily 8:30 A.M. meeting is held with all IT departments to review incidents, problems, past 24-hour changes and future changes. In standard ITIL terminology, a Configuration Management Data Base (CMDB) is a federated view of various Configuration Items (CIs) and the important relationships between CIs managed by the enterprise. Here at the bank, a master list of business applications is maintained in a database. Server related data is maintained in Access databases and spreadsheets. However no relationship data is maintained that specifies various relationships between applications and servers.
The term CMDB or Configuration Management Data Base can have multiple meanings depending on the perspective of the user. To the data center and server operations organization it mainly means the network, hardware (like servers), and the connections between them. They may also be interested in what applications run on each server. However they often lack the perspective of the application development team. The application team has a more complex view of configuration that includes the context associated with the configuration items (CI). “Context” means relationships between hardware, applications, and databases. Some of these relationships are physical and permanent while others are logical and temporary. So the challenge is to somehow get the contextual information out of the minds of those with the knowledge and into some form of database that, along with a visualization capability, can be kept up to date over time.
Key questions this tool would answer about the configuration include:
- What Configuration Items are dependent on a given CI?
- What redundancy exists that prevent down time if a specific CI is shut off?
- What applications and user functions are dependent on a specific CI?
- What is the service level associated with the business process and therefore some set of CIs?
Institutional knowledge of the production CI relationships is provided by over 100 subject matter experts (SME) in IT. Access to this knowledge requires meetings and emails to facilitate discussions about the CI relationships. Such a large effort has not been prioritized by the organization at this point. In addition to the creation and maintenance of CMDB data, there are two additional challenges. First is the necessity for a fast search of this data and a data retrieval capability and second is a graphical representation of the data. Both are important to the incident/problem/change management processes.
A possible solution has been proposed that may fulfill this high level CMDB requirement. The theory is that an intranet-based capability that promotes easy development and maintenance of the relationships will cause the experts to develop the data. One example we are all familiar with is wikipedia.org. The proposed solution would take advantage of three techniques common in today’s internet space. They are:
- A Social Networking Interface
- A Search Engine
- A Graphical Representation
Project
This project has two objectives. The first is to develop a working prototype of a high level CMDB repository that is accessible to FCB IT employees via a web portal on our intranet.
- Document business and technical requirements for the project.
- Develop web-based programs using a social networking motif to capture and maintain basic CI data relating to business applications and servers.
- Utilize a powerful search engine to enable quick access to data.
- Implement a graphical relationship diagramming capability that provides a visual representation of the CI relationships.
- Design and implement a data reporting capability.
The second objective of this project is to develop a method to evaluate the CI data for completeness and to create logical relationships from what is known. This capability will be used to highlight applications and servers that lack relationships and to create secondary relationships from primary identified relationships.
Well known internet applications that represent these types of capabilities include:
- Face book
- Linked In
- Google Search
- Wikipedia
This project includes the analysis, design, coding and testing necessary to create a small prototype of these capabilities. The results will be used as a pilot that includes a small subset of the business application and infrastructure. One proposal for consideration is that such an application may be prototyped using SharePoint for the user interface development. In its simplest form, this could boil down to a Wiki-like web tool that is loaded with core CI data, for example, server names, application names, application sub-component names, and database names, plus some form of relationship codes between them. Then knowledgeable folks would simultaneously log into the web tool and use some easy and fast visualization (think Visio network diagrams) to define the relationships and to "clean up" the data. Like a Wiki, others would be able to verify this information and suggest (or just make) alterations as necessary.
Cyber Situational Awareness through Streams Based Analysis
Background. The adoption of emerging technologies has changed the way we interact with the world and with each other. None have had a more significant impact in recent history than the emergence and acceptance of information systems into each of our lives. These information systems have changed the way we communicate with each other and how we go about accomplishing various tasks. We are more connected than ever before and we accomplish tasks with greater speed, higher precision, and increased efficiency. While these advances can be linked to the adoption of information systems, it has also come at a price; the technologies we used to support critical activities have become critical assets and protecting those assets has become a critical activity. We are now dependent upon information systems to accomplish many of our daily activities. Disruption in access or the degradation of the trust in the system can be devastating to individuals and corporations alike.
Project Statement. The goal of this project is to enable an enterprise to better protect its networks by developing analytic processes to aid the network defenders in performing network defense in the face of offensive cyber activities. Working with cyber engineers from The Johns Hopkins University Applied Physics Laboratory (JHU/APL), the team will implement analytic processes on IBM’s InfoSphere Streams platform, a streaming analytic tool utilizing continuous queries, to give high level decision makers situational awareness in real time and to improve the Computer Network Defense (CND) decision making process. This allows network defenders to make better informed decisions using relevant data to answer the critical questions they face when dealing with cyber attacks.
Project Deliverables. Students, using object oriented programming, will implement analytic operators and processes for the InfoSphere Streams platform and will deliver the source code and documentation to JHU/APL. The analytic processes will consume network data and identify suspicious network activities based on network anomalies associated with cyber attacks. The process will produce alerts of the suspicious network activities and identify the data used during the analytic process.
About InfoSphere Streams. InfoSphere Streams is a platform developed by IBM Research to enable the fast analysis of large quantities of information-in-motion to aid in decision making. InfoSphere Streams relies on a paradigm shift for data analysis by utilizing time sequenced events, or streams, to give time sensitive insight into data. Rather than query static data after it has been stored as is done in “traditional” data analysis, InfoSphere Streams queries data dynamic data as it is being used by the native process. Analyzing new data as it becomes available, rather than after it has been collected, enables decision makers to utilize real-time insights into the data when making decisions.
Developers can design, implement and rapidly deploy custom analytics to the InfoSphere Streams platform using the Stream Processing Application Declarative Engine (SPADE) and the supplied Eclipse-based Workflow Development Tool Environment. SPADE supports basic operators such as bringing in streams from outside InfoSphere Streams and the ability to export results from the system. SPADE also allows for the development of analytic procedures without having to understand the lower-level stream-specific operations. Developers, using the supplied Integrated Development Environment (IDE), can extend the functionality of SPADE by developing analytic operators not originally supplied with SPADE.
Benefit to Students. This project leverages the skills acquired by students during their studies at NCSU and introduces them to both new technologies and new concepts. Students will apply their analytic skills and programming background to the research area of network defense. This project will introduce students to the fundamentals of network security, operational networks, and the tradecraft of cyber exploitation. This project will utilize Virtual Machine (VM) technology, the InfoSphere Streams platform, and network traffic generators.
Suggested Team Qualifications
- Interest in Security
- Basic understanding of network security and/or attack
- Object oriented programming
- US citizenship (this will make it easier for the team to visit the APL facility at the end of the semester to present the results)
About APL. The Applied Physics Laboratory (APL) is a not-for-profit center for engineering, research, and development. Located north of Washington, DC, APL is a division The Johns Hopkins University (JHU). APL solves complex research, engineering, and analytical problems that present critical challenges to our nation. Our sponsors include most of the nation's pivotal government agencies. The expertise we bring includes highly qualified and technically diverse teams with hands-on operational knowledge of the military and security environments.
Performance Of Microsoft Hyper-V Virtualization Platform
The primary objective of this project is to compare performance of LAMP (Linux, Apache, MySQL, Perl, Python, PHP) stacks when installed directly onto enterprise-class bare metal versus the same stacks running under Microsoft’s Hyper-V virtualization platform. Packages to be considered will be based on SUSE Linux and Red Hat Enterprise Linux. The student team will configure and install these packages (with assistance from NCSU IT and Microsoft Engineers) on servers in local laboratories. The student team will also define applications and workloads and set up stress tests to determine the performance differences between stacks running on bare-metal and the same stacks running under the Hyper-V environment. Performance metrics, applications, and workloads will be designed in consultation with Microsoft Engineers based in Cambridge, MA.
The end product of this project will be a report detailing designs, results, and comparisons of testing scenarios, including visualization of results.
It is strongly recommended that students have knowledge and understanding of the following when selecting this project:
- Linux operating systems
- Web-services
- Database technologies
- PHP and web apps communicating with databases
- Hyper-V or some other virtualization technology (however project will be restricted to Hyper-V)
Implementation & Performance Study of iSCSI Extensions for Remote Direct Memory Access (iSER)
With increased focus on 10G Ethernet, vendors have begun to develop specialized Remote Direct Memory Access (RDMA) hardware to offload processing and reduce the copy overhead in the TCP/IP network stack. We know that iSER assisted iSCSI implementation does have a clear performance advantage for specific workloads, but NetApp is interested in an independent performance investigation. Several NCSU senior design teams have worked on this project in past semesters and have produced interesting results. This semester we propose to continue these investigations. This project will involve reading research papers on iSER, comparing and modifying existing open source Linux code (C) and gathering performance numbers for different workloads.
Background. Several hardware test setups were created and preserved in the lab. For details, see the past semester report posted on the CSC 492 website. Basically, several server-class machines are available with 10gBit optical RNIC’s from Chelsio interconnected by a Cisco switch.
Previous SDC Team reports provide a description of iSCSI, iSCSI with TOE, iWARP, iSER and comparative advantages of iSER. Workloads were created using sio, a NetApp tool that mimics high CPU intensive workloads. These reports also give a description of different iSCSI & iSER implementations, in particular University of New Hampshire (UNH) reference target and initiator code, and discuss functionality provided by the OFED stack (Open Fabric Enterprise Distribution). Most of these open source implementations needed some rework to support iSER with 10G Chelsio RNIC's. Performance numbers were gathered, especially server side throughput/latencies for different workloads with traditional iSCSI (Linux) initiators/targets and iSCSI with TOE. Comparisons were made and results reported for iSER assisted iSCSI. Tabulation and reporting of results were assisted by code and scripts developed specifically for that purpose by prior teams.
Goals This Semester:
- Baseline performance statistics should be determined for iSCSI without TOE
- Research needs to be done to understand how Linux assigns individual processor cores, and from there, how multiple threads are distributed across these cores.
- Performance testing should be extended to a single target with multiple initiators connected to it
- Performance testing should be extended to multiple initiator/target pairs.
- Enhance the testing harness by arranging to have coordinated start and end times on different machines. Data collection should be automated for test runs that involve multiple pairs. (Suggestions – use ntp, heartbeat, etc.)
HR Salary Administration Project
DOJ Salary Administration has approximately 200 plus MS Excel spreadsheets containing salary administration information. The spreadsheets are updated manually when new data becomes available such as a legislative salary increase, new hires, and employee separations etc. This data is used to create HR reports such as salary inequities; these reports have become more critical with the passing of the Lilly Ledbetter Fair Pay Act of 2009. When a new employee is hired, their pay must be within a certain range that corresponds to their experience and other factors. Currently all this information is stored in Microsoft Excel. DOJ would like this information to now be stored in a database and automatically be updated from their Main office, which sends out regular updates through a program called Beacon.
Project Requirements
- Work with DOJ to create a database schema for employment data.
- Parse data from regular Beacon update into the new database schema.
- Create a web based reporting tool to display multiple view graphs of the data
- Have an easy web based administration panel for manual overrides of employment data, salary thresholds, and additional comments.
Benefits to the students
- Good job experience for:
- Database administration
- Web programming
- Data Visualization
- DOJ willing to have their programmers and DBA’s meet with the students regularly if needed.
- Local Raleigh office very close to Centennial Campus
Ant Colony Optimization & Applications to Autonomous Vehicle Operation
Natural Computing is a burgeoning field that seeks to understand the way in which the natural world operates and uses this knowledge to inspire new approaches to solving computational problems. Abstractions motivated by this approach can provide alternate or improved algorithms for solving many different classes of problems. This field is not entirely new. “Nature as inspiration” has had a visible influence on computing beginning with the early work of Turing and von Neumann through their concepts of automata theory and cellular automata. More recently, notions of “neural networks,” “swarm intelligence,” and other ideas add to a growing list of abstractions to influence algorithm development. In particular, “Ant” algorithms have been introduced as an alternate approach to solving combinatorial optimization problems over discrete spaces. Here “Ant” refers to the behavior patterns of colonies of ants (i.e., the little crawling insects). Goals of this project are (1) to investigate ant colony optimization as an alternative approach to solving a distributed shortest path problem and, (2) to implement and evaluate a version of this approach using miniature autonomous vehicles that collaborate to find and use the shortest path between two points.
Algorithms designed for this project will be implemented in Java and executed on small battery powered computation devices with short-range radio capability, i.e., the Sun Labs SPOT (Small Programmable Object Technology). The team working on this project will be expected to conduct research into Natural Computing - especially Ant Algorithms, demonstrate an understanding of ant colony optimization through simulation or other programmed means, compare the relative merits of this to classic shortest path approaches, evaluate available autonomous vehicles, and demonstrate a solution using the SPOT as the autonomous vehicle control computer.
SVN Spy - An Open Source Flex Project
Project Goal
The student team will participate in an Open Source initiative to help expose data behind source code repositories on the web. Leveraging technologies such as Java, SVNKit, BlazeDS, Spring, Flex, and PureMVC, they will help expose and migrate metadata, using social networking influences, to unlock the power of SVN. This project has an architecture already designed and in place and is looking for talented developers to contribute to its feature set. The project uses a test driven development approach and a continuous build and integration environment to ensure team cohesiveness.
A student team can contribute to the project based on their knowledge and ability to:
- Expose and implement a security layer that could later be used to integrate with Facebook, LinkedIn, MySpace;
- Improve the functionality of the Charting feature similar to Google’s Finance Chart;
- Expose the ability to navigate from file metadata to an actual repository;
- Expose the ability to allow users to diff files where they live in SVN repositories;
- Improve the Visual Design and HCI of the interface
- Improve the architecture documentation and help deploy it to the project’s website;
- Devise a scoring mechanism that will allow for developers to be scored based on performance.
Background & Vision (from http://www.neosavvy.com/svn-analytics/)
SVN Spy is a tool used to help aggregate statistics about remote subversion repositories around the world with the goal of helping compare developer statistics and demonstrate that delivered results by a developer can be measured against a group of peers or even unknown developers. The long term goal of this project is to help crawl known public and private SVN repositories and gather statistics about all known users in the effort to compare patterns that form amongst groups of developers. Some of the questions that this effort will try to determine are:
- What groups of developers work well together?
- Are there patterns of activity that form during the normal throws of a software development cycle?
- Is it possible to determine the productivity of a developer simply by analyzing the statistics of a subversion repository?
- When do developers tend to have the most activity in their repository?
The project’s existing example code is here:
http://www.neosavvy.com/svn-analytics-webapp/
This is an open ended project and hopefully a continuing effort sponsored by Roundarch, a technical consulting firm based in NYC and Chicago and will be guided by a developer at Neosavvy, Inc.
For more information about Roundarch, visit www.roundarch.com
(http://www.roundarch.com/ and http://impost.roundarch.com/)
Business & Statistical Graphics Creation & Manipulation Through Symbols & Gestures
Many traditional business and statistical graphing packages allow creation and manipulation of graphs by selecting from a list of possible graph types and choosing features of the desired graph as descriptive options. In many cases, the user must provide the data to be graphed in advance before they can begin to see the results. The goal of this project is to develop a software library to interpret gestures and hand-drawn symbols using a mouse or track pad to interactively build a graph without having to specify either the data or the named layout of the graph. For example, a simple bar chart might be expressed as a series of vertically stretched boxes, whereas a pie chart might be intuited from a crudely drawn circle with internal lines depicting the slices (see example images).
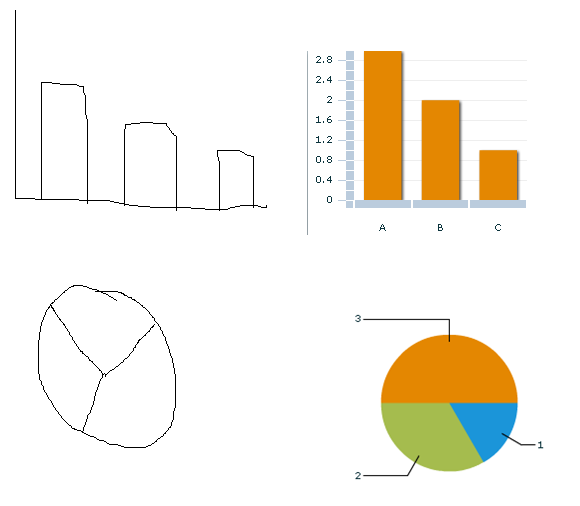
There is a lot of new hardware that provides alternate input methods. The idea behind this project is that it will not require access to special hardware (iPhone, touch screens, etc.) or platform-specific API's (Windows 7 has one, Mac OSX has another, the iPhone has a third). Rather, the project will use the cross-platform API's newly released in Adobe Flash Player 10.1 and will focus on the logic and algorithms of gesture classification and interpretation. Hopefully, this can be achieved with a standard mouse or track pad, but dissenting opinions are welcome, if supported by demonstrations and adequately justified!
There is a clear trend in consumer electronics (iPhones, iPod Touch, netbook computers, etc.) to provide more intuitive input controls, along with API’s to access them. The iPhone operating system, Windows 7, and Adobe Flash 10.1 all have introduced new sets of API’s to support multi-touch and gesturing. However, this project will primarily use the new Adobe Flash capabilities and will use existing SAS components for the actual chart/plot rendering. As such, the focus will be on the gathering, classification, and contextual interpretation of incoming gestures. SAS has access to Windows 7 hardware, iPhones, HP touch screens, Apple Mac trackpads, etc. which may be used for comparison purposes along the way to see how other hardware/API/applications are dealing with "gesturing" and how this project might eventually be used in those environments for graph creation, but the focus and the primary development here will be using Adobe Flex and Flash.
For more information, see:
http://www.adobe.com/devnet/flash/articles/multitouch_gestures.html
Apple iPhone API’s: http://developer.apple.com/technology/cocoa.html
Windows 7 API’s: http://msdn.microsoft.com/en-us/magazine/ee336016.aspx
Mobile Retail Applications Using iPhone, Droid, etc.
Project Goal
Create an iPhone/Droid or windows mobile app or web based mobile app that utilizes Best Buy's Remix service (http://remix.bestbuy.com/). The end user for the application is any potential Best Buy customer who has access to a mobile device. This application will allow consumers to interact with Best Buy's product catalog via their mobile devices.
Project Requirements
- The application must have a user friendly interface that is inviting and intuitive to consumers.
- The app should be able to display/browse a list of 10 items at a time.
- The app should allow users to search for products by specific criteria.
- The user should also have the ability to add items to a virtual cart/gift registry.
- The user should be able to take a picture of a barcode, then use that barcode to return product information via Best Buy's Remix service.
- The user should be able to set up price alerts – i.e., set a target price in case an item goes on sale or the manufacturer drops the price, then they would receive an e-mail letting them know. This could be tied to a wish list.
- The user should also be able to check Gift Card balances and Reward Zone point balance.
- We do not expect to have any other retailers’ APIs but we do want the ability to implement easily when they are available.
Other Considerations
- The application framework should be designed in a generic fashion, so it can be implemented for other retailers when the service is available by changing a module on the data lookup.
- The back-end should be created in VB .NET. The mobile interface would be written in the specific device's language (IE, Java, Objective C).
Here is a link to Android's emulator:
http://developer.android.com/guide/developing/tools/emulator.html
Here is a link to the iPhone development kit:
http://developer.apple.com/iphone/program/develop.html
These are both free.
Also, possible access to real phones of one or more types may be provided. At project conclusion, demonstrate it working on two or three devices.
A Graphical User Interface for an SQL Pretty Printer
Problem Statement
The Healthcare Business of Thomson Reuters is involved, among many other things, in software that communicates with relational database management systems via the widely used SQL query language. One of the flagship products is called Advantage Suite, which allows healthcare data analysts to interactively construct specialized reports via the Decision Analyst application. Each report definition results in a series of SQL queries that are sent to the database for execution. The resulting answer sets from each query are then “collated and stapled together” by Decision Analyst and displayed to the end user.
The queries issued by Decision Analyst are not directly readable by humans, since no indentation and alignment (commonly called pretty printing) is used. Here is an example of such an unreadable SQL query:
SELECT EPIS_OTHER.epi_sum_grp c0, EPIS_OTHER.epi_disease_stg_cd c1, PERIOD_INC_M.rolling_year c2, SUM(EPI_PROF_CLM.net_pay_amt) m0 FROM EPIS_OTHER EPIS_OTHER,EPI_PROF_CLM EPI_PROF_CLM,PERIOD_INC_M PERIOD_INC_M WHERE (((((EPI_PROF_CLM.epi_other_key = EPIS_OTHER.epi_other_key) AND (EPIS_OTHER.epi_sum_grp IN ('Asthma','Cancer - Breast','Cancer - Cervical'))) AND (EPIS_OTHER.epi_disease_stg_cd IN ('0.00','1.01','1.02','1.03','1.04','1.05','1.06','1.07','1.08','2.01'))) AND (EPI_PROF_CLM.period_inc_key = PERIOD_INC_M.period_inc_key)) AND (PERIOD_INC_M.rolling_year = 'Jun 2008 - May 2009')) GROUP BY EPIS_OTHER.epi_sum_grp,EPIS_OTHER.epi_disease_stg_cd,PERIOD_INC_M.rolling_year
Although a number of no-cost SQL pretty printers exist on the web, they are generally not reliable when confronted with long queries. As part of a project that deals with query optimization via source-to-source rewriting, a command line driven pretty printer for a certain subset of SQL was developed by Thomson Reuters. The pretty printer is written in Java, and currently executes under Windows. Here is what the pretty printer output for the above query looks like:
selectepis_other.epi_sum_grp as c0,
epis_other.epi_disease_stg_cd as c1,
period_inc_m.rolling_year as c2,
sum(epi_prof_clm.net_pay_amt) as m0
Transit Route Beautifier
Project Description
TransLoc was formed by NCSU students with the goal of revolutionizing campus transit. Today, universities all over the country use the technology first used here on the Wolfline.
In addition to universities, big city transit systems are now beginning to take notice of what we do, which is where you come in. The route data that we get from large transit agencies needs to be cleaned up before we can make use of it. Specifically, we need a tool that will transform routes defined as messy paths into clean paths that match the streets. If you are successful in doing this you will improve the daily lives of thousands of riders of large transit systems.
The data we get from the transit agencies outline the path of each individual route as a series of latitude and longitude pairs. With this, however, we need to figure out which routes overlap and where, data that is vital for us to be able to visually indicate where the routes overlap on our maps. Furthermore, even though routes may overlap on a section of road, their paths do not always line up neatly with the same latitude and longitude pairs, thus making it difficult to detect the overlap through simple means.
This project presents the challenging task of designing and implementing a tool that is capable of automating the work of cleaning up the route paths. The tool will transform a collection of sloppily overlapping paths stored in flat files and produce a set of clean paths that closely follow the streets. In addition, these paths will be broken into unique sections and stored in a database. Along with the unique section data, the database will also contain the mapping of the original paths to the new sections.
Below is a sample of the desired outcome:
Though we are open to suggestions, we would prefer the use of Python with MySQL or PostgreSQL under Linux. If you don't know Python but are an excellent coder, go ahead and start learning it now.
Project Archives
| 2026 | Spring | Fall | |
| 2025 | Spring | Fall | |
| 2024 | Spring | Fall | |
| 2023 | Spring | Fall | |
| 2022 | Spring | Fall | |
| 2021 | Spring | Fall | |
| 2020 | Spring | Fall | |
| 2019 | Spring | Fall | |
| 2018 | Spring | Fall | |
| 2017 | Spring | Fall | |
| 2016 | Spring | Fall | |
| 2015 | Spring | Fall | |
| 2014 | Spring | Fall | |
| 2013 | Spring | Fall | |
| 2012 | Spring | Fall | |
| 2011 | Spring | Fall | |
| 2010 | Spring | Fall | |
| 2009 | Spring | Fall | |
| 2008 | Spring | Fall | |
| 2007 | Spring | Fall | Summer |
| 2006 | Spring | Fall | |
| 2005 | Spring | Fall | |
| 2004 | Spring | Fall | Summer |
| 2003 | Spring | Fall | |
| 2002 | Spring | Fall | |
| 2001 | Spring | Fall |