Projects – Spring 2017
Click on a project to read its description.
Product License Management Website (KLM)
Allied Telesis – 1
We currently have a website that serves as a frontend for managing one of our product’s licenses. We are in need of a new website that supports more products, uses software we are familiar with, and can be maintained and modified over time. This requires setting up an Apache Tomcat server and developing a Java-based web application that will interface with existing licensing applications, manage customer accounts, and generate licenses for them. The application would be based on our existing website and implement the following:
- Create and find customer accounts
- Entry of license purchase order information such as purchase order number, date, contact information
- Provide a choice of currently implemented license types that correspond with what was purchased
- Issue licenses – invoke a license application and send the information to the customer
- Maintain a history that can be used to query current and past licensing information for every customer
The application can be extended depending on progress and can implement the complete website functionality of managing license types, customer accounts, and logistic user accounts. It has the ability to store and modify a history of orders, reissue or cancel existing orders, and to manage licenses for multiple products.
The new website needs to know about customers and what products they have. It doesn’t need to know how licenses are created; it will utilize common interfaces to ask for licenses to be created based on a set of parameters that we define. It will need to maintain a database, preferably using MongoDB, to store customer data and license information.
The current website is implemented using Groovy on top of a Java platform and is run on Oracle Glassfish. Our desire is to replace the frontend with a modern, sustainable interface, using a common framework such as AngularJS, Ember.js or jQuery. We would like the students to evaluate the current implementation, choose an appropriate framework and implement the new solution.
Corporate Background
Allied Telesis is a network infrastructure/telecommunications company, formerly Allied Telesyn. Headquartered in Japan, their North American headquarters are in San Jose, CA. They also have an office on Centennial Campus. Founded in 1987, the company is a global provider of secure Ethernet & IP access solutions and an industry leader in the deployment of IP triple play(voice/video & data), a networks over copper and fiber access infrastructure.
Management of Ethernet Networking Equipment in Factory Automation Environment
Allied Telesis – 2
Factory automation systems can utilize several different Fieldbus technologies. Evolution of some of these technologies to utilize Ethernet and TCP/IP as a means for L2/L3 communication has created the opportunity for Ethernet Networking vendors to push their products as part of the factory non-time-critical communication network. In order for this to be achieved in a non-disruptive manner, it is necessary for these switches to be manageable by the existing Management System used in that factory. As a result, there is a need for several of the Allied Telesis Switches, targeted for Industrial Automation solutions, to support select Fieldbus Management Protocols specific to those environments. Ethernet/IP and Modbus are the two selected for this project since there is strong industry support and existing open source solutions available. Ethernet/IP (Ethernet Industrial Protocol) is focused on automation control communication and is promoted by ODVA. There is a large amount of information available on their website.
The Ethernet/IP open source application is OpEner. It was released into the wild by Rockwell a while ago – and has recent updates. Probably not perfect – but hopefully adequate (https://github.com/EIPStackGroup/OpENer). It is a generic package – that enables the user to define the objects representing the device and communicate with them from another device using Ethernet/IP.
Modbus has evolved from a Serial communication protocol – to one now capable of running over Ethernet. There is lots of information from the Modbus web page as well. From this page it is possible to download an open source Modbus library that can be used.
In order to enable the project, development focus to be on the Automation Management protocols and not on the underlying embedded system, the interface between the applications under development and the rest of the system will utilize an open source data management application (https://github.com/alliedtelesis/apteryx). This application is already present in the ATl code base and functional on the IE200 platform. It provides a clean interface into the existing ATl datamodel. In addition, since the Apteryx datamodel can be modified at run-time, it will be possible to emulate any data that is not easily available.
ATl will provide:
- Container-based, cross-compiler build environment for the target platform.
- Several IE200s to serve as runtime system.
- Minimal list of attributes and interfaces to control and report status on.
- Active support to get the project team off and running.
The scope of the project includes the following
- Validation of Embedded Development environment (Container build system – generates executable object) – Mostly provided by ATl.
- Able to build and run a “hello world” executable.
- Configuration and Generation of Modbus executable
- Integration with Apteryx for Configuration of Modbus service
- Integration with Apteryx for Access to monitored data
- Build Modbus application and execute from thumbdrive on embedded system
- Validate implemented functionality:
- Use novaprova for unit tests.
- Configuration and Generation of EthernetIP executable.
- Integration with Apteryx for Configuration of EthernetIP service
- Integration with Apteryx for Access to monitored data
- Build EthernetIP application and execute from thumbdrive on embedded system
- Validate implemented functionality:
- Use novaprova for unit tests.
- Extend testing scope to include use of open source testing tools and/or consortium-defined compliance test suites.
Corporate Background
Allied Telesis is a network infrastructure/telecommunications company, formerly Allied Telesyn. Headquartered in Japan, their North American headquarters are in San Jose, CA. They also have an office on Centennial Campus. Founded in 1987, the company is a global provider of secure Ethernet & IP access solutions and an industry leader in the deployment of IP triple play (voice/video & data), networks over copper and fiber access infrastructure.
Realtime SMS Monitoring Android App + Web Service
Bandwidth
Bandwidth is a communications technology company that’s transforming the way people communicate and challenging the standards of old telecom. We provide voice and messaging APIs that allow developers to easily add texting or calling to any app. Our mission is to bridge the gap between the new world of REST APIs and application development and the old world of telecom hardware and networks.
Our services have many different mechanisms in place to monitor the health of our systems, but a challenge arises when we want to monitor end to end connectivity with networks operated by other providers. For example, we can monitor if text messages are sent and received successfully on Bandwidth phone numbers, but right now we do not have an automatic way of testing if a device on another provider’s network, such as AT&T or Verizon, successfully received a message that we sent. Likewise, we do not have automatic monitoring that can detect when users of other carriers are having difficulty sending messages to Bandwidth numbers. It’s hard to know you never got a message you weren’t expecting it in the first place.
The goal of this project is to solve this problem and provide visibility to the deliverability of messages all the way to the end user’s phone. This will be accomplished by building a system that tracks messages to and from Android devices and reports back to a central monitoring system. The project has two components:
Web Service
The web service will send test messages, listen for events via HTTP callbacks, and post metrics to AWS CloudWatch. The web service will periodically make HTTP requests to the Bandwidth API to send test messages to phones that are running the Android service, which is the other component of this project.
Android App
This app will be a background service that will be installed on multiple test devices that are running on several different carriers. The devices themselves will sit in the Bandwidth Network Operations Center (NOC). The background service will monitor for SMS or MMS messages containing specific information indicating that it is a test message. The app will then reply to the message and POST to the web service. A user interface on the Android device is not necessary.
The combination of these two components will allow us to monitor message delivery all the way to end-user devices on carriers that we would otherwise not have visibility into. Once we begin collecting metrics, we can monitor deliverability in real time, and trigger alarms when messages are not received as expected.
If needed, an Android development device can be provided by Bandwidth for this project.
3D Phi-Mask
Dr. Anita Skincare
Project Background / Opportunity
This is a joint project between Dr. Anita Skincare, a boutique cosmetic medical practice in New York City, and Triangle Strategy Group (TSG), a technology consulting firm in RTP. TSG has significant experience with Internet of Things (IOT) in retail settings and Digital Marketing.
Dr. Anita Dormer has been working in Aesthetic Medicine since 2000. One of the core tools she uses in her treatment decisions is the “Phi Ratio” or “Golden Ratio” which describes the ideal proportions of the human face for maximum attractiveness.
In 1996, Dr. Stephen Marquardt designed and patented a “Phi Mask” that systematically applies the golden ratio to layout the most attractive placement and dimensions of facial features.
Many attempts have been made to apply the Phi Mask in 2D both manually and recently digitally. Recent developments in 3D mapping – notably the Microsoft Kinect device – allow an exciting and powerful new 3D adaptation of the Phi Mask.
Dr. Anita would like to use a 3D computerized adaptation of Phi-Mask in the standardized treatment of her patients. It will allow Dr. Anita and her patients to visualize possible improvements to their faces through a variety of treatments ranging from makeup to cosmetic surgery. The visualization will help patients make better-informed treatment decisions and give them an objective measure of what to expect.
Project Scope
The goal of this project is to develop software to capture a high-quality 3D image from the Kinect, analyze the image using the Phi Mask, visualize the data, model optimization scenarios and to develop a mobile app.
At the start of the semester, TSG will provide a Kinect device ready for programming. We will have sister devices for testing at Dr. Anita’s office in NYC and TSG’s office in RTP.
Deliverables
- Face capture module
- Interactive setup for image grab on Kinect
- Measure illumination, request any needed hanges (brighter, darker)
- Measure placement, request any changes (move left, look up).
- When optimally positioned, capture HD 3D image of client’s face (3D image and texture)
- Save image data to cloud database
- Interactive setup for image grab on Kinect
- Analytics module
- Convert 3D image to vertex array
- Extract coordinates of key vertices
- Calculate key distances and ratios between vertices
- Calculate beauty score (0-100) using TSG beauty score algorithm
- Output beauty score and drivers (e.g. face long relative to width, mouth wide vs nose)
- Interactive rendering module
- Fit and render an overlay of Phi-Mask on client’s facial image
- Adjust client’s image with scenarios, calculate improvements to beauty score, render model
- Plastic surgery (fix all ratios 100%)
- Aesthetic medical treatment (partially fix a few ratios)
- Makeup optimization
- Hairstyle
- Custom: adjust ratios on sliding scale
- Allow user to pan, tilt, rotate image
- Save modeled scenarios to cloud database
- Interactive smartphone app
- Access cloud database
- Allow user to select scenarios, pan and tilt – maybe use gyro on phone?
- Provide referral to designated service professional / call for appointment
- Database to log each access and actions taken on app
- Send base scan, scenarios and images to service professionals
Stretch Goals
- Allow hosting of additional Phi-masks (initial mask for this project will be a Caucasian female – Dr. Marquardt has developed other masks including male and ethnic)
- Host more complex beauty models (TSG will provide initial beauty model in parametric for to allow later upgrades)
- Before and after comparison
Technology
- The core hardware will be a Kinect for Xbox paired with a PC running Windows 10 - Kinect SDK 2.0 produces high-resolution images and extracts over 1000 vertices from a facial image.
- Programming for the core application will be in C#, and Kinect SDK 2.0 HD face tracking library
- Other SDC teams have recently had good results with Unity 3D engine for rendering.
- We are presently open minded on mobile programming – it has been suggested to develop in Java (for Android) and port code to iPhone through J2ObjC.
- Database operations will use AWS
- TSG will provide a 3D version of the Phi-Mask ready for use and a beauty model ready for coding
Having at least one member of the team with joint Math major would be a plus. Cosmetics / healthcare industry knowledge not required.
Target Audience
The team should consider the following stakeholders:
- Cosmetic Doctors, their staff and their patients
- Makeup artists
Benefits to Students
- Work at the leading edge of digital marketing
- Build experience with 3D scanning, modeling and visualization
- Receive positive exposure to multiple potential employers
Benefits to Sponsor
- Leverage the unique creative capabilities of the full NCSU team
- Gather ideas that may help solve a challenging set of real world problems that are important to our business
Wolfpack Athlete Management System
Freeh
College athletics has become an arms race. With expanding revenues have come new opportunities for companies to come into the collegiate environment and offer new technologies that seemingly will allow the programs to improve their athlete success. Advanced technologies include Global Position Sensors, heart rate monitors, bar speed measuring devices, motion capture systems, and more. All of these systems generate a tremendous amount of data that not only needs to be stored and sorted, but communicated across an entire department. There is an entire industry now devoted to employing data scientists at the collegiate and professional setting and it is rapidly growing. There is a demand to create more effective athlete management systems to service the needs of a rapidly expanding athletic departments looking to gain any competitive edge through the use of performance technologies.
Prototype
Several athlete management systems exist nationally that have tried to respond to the needs of the collegiate environment, such as Kinduct, CoachMePlus, Bridge Athletic and Smartabase. These systems typically allow a coach to create individual athlete profiles, share information regarding any testing and monitoring they conduct with the athletes, and are typically compatible with the reports generated by many performance technologies. However, these systems are not customizable and expensive.
Project
Build WAMS, the Wolfpack Athlete Management System, that consists of a web server front end, a data collection framework, and a data storage and management back end. The front end exposes the data to several classes of clients, such as coaches and athletes. It provides various views of the data to track and analyze performance.
The AMS would include basic athlete information, performance testing data, monitoring information (questionnaires, rating of exertion), and sport performance metrics. The system should include different views for athletes, sport coaches/administration and sport scientists. Data visualizations would also need to be included to provide contextual information.
The project builds a data collection framework for the Polar HR (heart rate) monitors. The monitors communicate with a Bluetooth radio to a base station. The framework communicates with the monitors to download HR data from training sessions.
The data storage and management backend stores all data, which includes the collected data, user profiles, configuration settings, and more. It also stores metrics derived from analytics, such as average heart rate. The backend provides reliability, security, and availability.
Views
The prototype will consist of numerous web pages that support three views: athlete, coach, and admin. An athlete will be able to view and input her own data. A coach will be able to view data for all athlete on the team and run analytics both on individuals and across teams. These are the overall parameters. However, there is much design work to be done. The student team is expected to do some competitive analysis of existing athlete management systems, conduct interviews of athletes and coaches, and present ideas for views.
Open source and extensible
We are advocates of open source. So we expect to release the software as an opensource project. Furthermore, all third-party tools, libraries, etc also will be open source. Extensibility is fundamental to success. While the Polar HR monitor is the only device planned for this project, the solution needs to be design to support any device.
Skills:
- Web framework
- Database manage and Linux admin (eg, cron jobs)
- Languages: Python, Java, C/C++, SQL, bash, and
- Network protocol: Bluetooth
Mentors: Professors V. Freeh and M. Shahzad; Sport Scientist/Strength Coach N. Brookreson
Risk Preparedness Dashboard
Merck
Merck is a global pharmaceutical company that aspires to provide leading innovations and solutions for today and the future through the production of medicines, vaccines and animal health products. With being a leading global pharmaceutical company, many cyber and physical security risks exist that could compromise its health care objectives. As a result, Merck must be able to protect its intellectual property and have a workforce that is prepared and ready to face a variety of threats and risks.
Merck is interested in having the senior design team create a dashboard that determines the “readiness” of risk preparedness. The objective is for the team to determine what factors affect the score and how much weight each factor contributes to the score. (A few examples of measures: 1) Applications live outside of Merck, how well are the protected as, 2) Employees can take training courses or get certifications to become more knowledgeable about risks, 3) Critical vendors to Merck’s operations).
The concept is that there are a number of measures that could potentially influence a risk readiness score, from all aspects of business. What we are asking the students to do is:
- Come up with measures that would be good influencers of a “risk readiness” score
- Develop a dashboard that could represent these score (Mobile & Web)
- Enable a drill down into the various metrics that are influencers of the score so leaders of the organization could take corrective action
- The dash board would have 4 highlighted areas that would be customizable based on what the leader felt like his organization should focus on
- Measures that were not highlighted as the top 4 would be parked on the side of the dashboard so the could be dragged and dropped to replace one of the highlighted 4
- Be creative with the measures
- Dashboards should role up organizationally (so training potentially could go all the way down to and individual, where an application would start at the application owner)
- Below is an example of what the dashboard may look like.
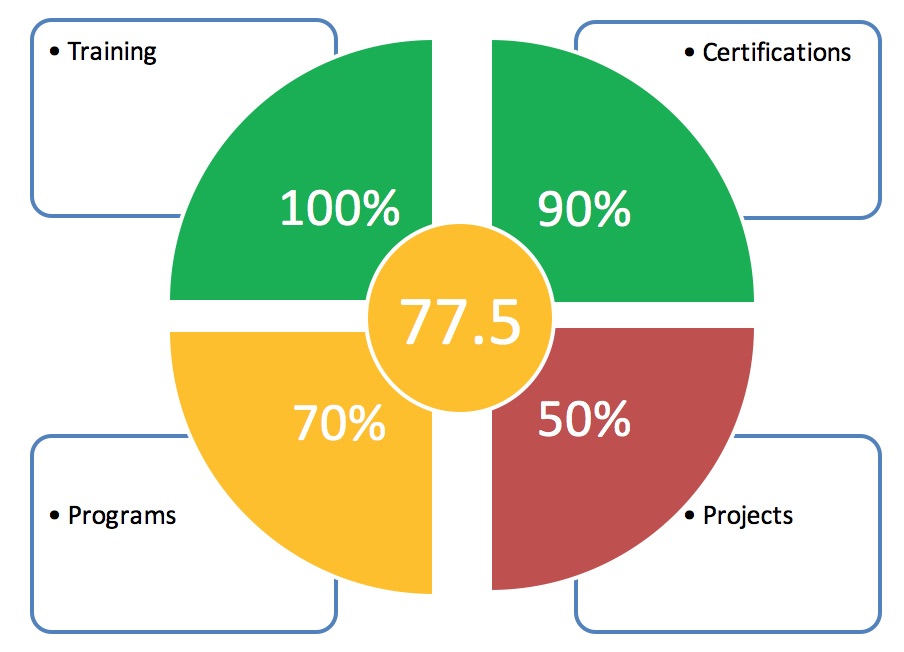
Management UI/API for StorageGRID Containerized Deployments
NetApp
Background
StorageGRID Webscale, NetApp’s software-defined object storage solution for web applications and rich-content data repositories, is designed for the hybrid cloud. It supports standard protocols—including CIFS, NFS, Amazon S3, and Swift—so you can run your apps on-premises or in public clouds.
StorageGRID Webscale leverages a distributed shared-nothing architecture, centered around the open-source Cassandra NoSQL database, to achieve massive scalability and geographic redundancy, while presenting a single global object namespace to all clients.
StorageGRID Webscale nodes can be hosted on VMware or KVM virtual machines in vSphere or OpenStack environments, or on bare metal appliances based on NetApp’s high-density, low-latency E-Series storage arrays. In an upcoming release, we are adding support for container-only deployment, allowing customers to plug StorageGRID Webscale node Docker containers into bare metal whitebox servers running Red Hat Enterprise Linux (RHEL), to maximize performance (no more virtualization tax) and minimize cost. The container-only platform option is the context for this project.
Project Goals
- Implement a UI and REST API for configuring and managing StorageGRID Webscale nodes running on bare metal RHEL hosts
- REST API will be provided by a Python 2.7 server running on each RHEL host and interacting with the StorageGRID container host service via a simple line-oriented protocol over a Unix domain socket. Operations include:
- Create and edit per-node configuration files
- Start node
- Stop node
- Reload node configuration
- Initiate node recovery
- Get node status
- UI will be provided by a standalone .html file containing javascript. This file should be served in response to a default HTTP GET on the Python web service.
- Note: development can be done over multiple files, with the final UI container file assembled during the build process.
Deliverables
- StorageGRID-Webscale-Host-Management.rpm
- RPM package that installs Python web service (including UI .html file)
Development Environment
- Red Hat Enterprise Linux 7.x (or CentOS 7.x, if RHEL subscriptions are not available)
- Python 2.7
- Javascript
- Bootstrap for styling the UI
Application Health Dashboard
Premier – 1
Goal: to be used by the development, infrastructure and operations teams as a light-weight monitoring tool that can be easily customized for any environment and application. Some products use a commercial off the shelf solution for monitoring, while others cannot justify the cost of a commercially available solution. In the instance of the latter set of products, Premier would like to have a low-cost and effective solution to get some visibility into our solutions’ health.
Requirement: create a web app that will monitor a number of servers and provide information about their health on several levels:
- Application Server level ( Current CPU utilization, %, Current Memory utilization, %, Average CPU utilization over the past 24 hours, Average memory utilization over the past 24 hours, etc.)
- Database server level (database type, long running queries, CPU utilization, memory utilization, (metrics as above for Application server))
- Service monitoring on application server: Number of processes / jobs running, Job name, Average job run time, Etc.
Solution would, ideally, be OS and Java/.NET agnostic so that we could use on a variety of solutions. If needing to choose only one, we’d focus on .NET and SQL Server.
Students would need to provide a plan of how applications get monitored and what is necessary for their metrics to show up on the monitoring application. They would be responsible for outlining how configuration was handled to cover application, database and service monitoring. Testing would be necessary to demonstrate a very low “footprint” of monitoring overhead – monitoring should not adversely affect solution performance.
The dashboard should have a high level health indicators for each server, as well as ability to drill down into specific server or application instance (e.g. to see which jobs are pending).
Source Code Customization Analysis
SugarCRM
About SugarCRM
SugarCRM helps businesses create extraordinary customer relationships. SugarCRM is a leading vendor in Customer Relationship Management software. We compete with the likes of Salesforce.com, Microsoft, and Oracle. Some of our customers include IBM (one of the largest CRM deployments in the world), Sennheiser, HTC, and Sherwin Williams. SugarCRM is a privately held company based in Cupertino, CA in the heart of the Silicon Valley with an office in the Research Triangle Park.
Sugar is deployed by over 1.5 million individuals in over 120 countries and 26 languages.
Project Background
Sugar, like most Customer Relationship Management (CRM) applications, is often heavily customized by Software Engineers or Developers in order to meet customer requirements. For example, in order to support a particular company’s sales or customer support processes, there could be a number of workflows that need to be implemented as well as integrations that need to be created between the CRM and external systems.
Sugar has an open source heritage which allows for extensive source code level customizations. This makes it extremely flexible and has traditionally allowed for a wide variety of customizations without abiding by well defined API contracts. This poses a challenge during upgrades – an upgrade of the Sugar application from one version to the next can break these extensive code customizations, or worse, break the entire Sugar application. This poses a business challenge where customers become stuck on old versions of software due to costs related to fixing customizations after upgrades. Ultimately, this affects customer retention which is essential to the success of a subscription software business. We want to improve the API contracts that our platform provides to better enforce separation of core application code from code customizations.
The Sugar platform is written in PHP with a front-end JavaScript framework built on Backbone.js, jQuery, and Handlebars. SugarCRM hosts Sugar as a service (Sugar On-Demand) or it can be deployed on premise by our business partners or by larger Enterprise customers.
Project Objectives
This project would involve building tools to automatically analyze source code level customizations that have been made to the Sugar platform. This tool could either be embedded into our application or distributed standalone to customers and business partners. The tool can then be run against thousands of our customer instances to gather information about what customizations exist and report back to SugarCRM. The goal would be to identify the set of most commonly found customization use cases. A research report with findings based on scans of real Sugar customizations is another deliverable. These resources will aid SugarCRM in planning how we evolve our platform, in particular, where we should be improving or adding APIs.
ShelfRokr
Triangle Strategy – 1
CORPORATE BACKGROUND
Triangle Strategy Group (TSG) is a technology consulting startup based in RTP. Our clients are fortune 500 consumer goods manufacturers and retailers. We integrate Internet of Things (IOT) technology into retail stores and consumer products to help our clients influence consumers’ purchase decisions and expand their product use. Our combination of patented IOT technology and analytics gives us powerful insights that help our clients grow their businesses and create innovative products that better meet their consumer needs.
PROJECT BACKGROUND / OPPORTUNITY
We are presently working with a major cosmetics client in New York City. Our client seeks to optimize the design and layout of their retail displays and integrate digital marketing into their physical product displays. During Fall semester an SDC team developed software for our “ShelfRokr” prototype display that tracks shopper pickup and putbacks from the display and drives local digital marketing.
PROJECT SCOPE
The goal of this project is to expand upon the present system to integrate additional sensors, add mobile functionality and drive more sophisticated digital marketing. TSG will provide a functioning prototype for the team to work with. The hardware includes three types of IOT sensors – pickup sensors that track which items shopper touches, proximity sensors that detect the position and movement of a shopper and an NFC read/ write system for connecting with smart devices.
DELIVERABLES (IN PRIORITY ORDER)
- Expand existing Arduino module
- Gather data from proximity sensors, convert to shopper position and direction and log this
- Add capability to auto-detect number and type of sensors
- Add ability to detect and log system failure (power out, sensor failures)
- Add database analytics module (on server)
- Alerts (pickup, proximity, out of stock, tester empty, shrink event, power out, sensor fail)
- Daily / weekly activity reports
- CRM analytics (follow-up targeting, cross-sell, dwell time)
- Add mobile app (to support both iOS and Android)
- Leverage QR and NFC connect for shopper ID, app install
- Consumer mode: deliver product information from display via smart phone
- Technician mode: remotely manage ruleset, configure routing for alerts and reports
- Enhance media delivery module
- Add new touchscreen navigation capability (navigate between screens product features and benefits video, application demo video, testimonials, ingredients, online reviews)
- Add social media connect
- Provide on-screen volume and subtitle control during video segments
STRETCH GOALS
- Add new ruleset functionality to configure how movement and pickup triggers media
- Add data buffering capability to cover loss of Wi-Fi connection
- Add data extraction from DynamoDB database via MS Access
- Add role-based access to allow remote updating of system parameters, content and ruleset
TECHNOLOGY
The hardware contains four programmable elements:
- Arduino microcontrollers - drive the sensors, NFC reader and LED lighting system
- Windows tablet PC - performs analytics, communications and input / output.
- Server - gathers data from multiple remote systems, data logging, launch alerts
- Smart phone – alerts service technician / security personnel
We expect the project will require the following tools: C++ (microcontroller), C# (tablet PC), Flash Player, DynamoDB, EC2, MS Access, Android, iOS. Hardware design not required but would be a plus. Cosmetics industry knowledge not required.
TARGET AUDIENCE
The team should consider the following stakeholders:
- TSG marketing analytics consultants
- Client advertising team
- Field service technician
- Store security personnel
BENEFITS TO STUDENTS
- Work at the leading edge of convergence of digital and physical marketing
- Build experience with real world IOT hardware
- Help establish new standards and protocols for the exciting new field of IOT
- Receive positive exposure to 2 potential employers
BENEFITS TO SPONSOR
- Leverage the unique creative capabilities of the full NCSU team
- Gather ideas that may help solve a challenging set of real world problems that are important to our business
OPEN QUESTIONS To Explore
- Should we use SAS ESP in the analytics chain or is this too simple to benefit?
- What are best principles for laying out this sort of user interface?
- What are best practices for user identification (QR / NFC / others?)
Counterintelligence
Triangle Strategy – 2
PROJECT BACKGROUND / OPPORTUNITY
Triangle Strategy Group (TSG) is a technology consulting startup based in RTP. Our clients are fortune 500 consumer goods manufacturers and retailers. We integrate Internet of Things (IOT) technology into retail stores and consumer products to help our clients influence consumers’ purchase decisions and expand their product use. Our combination of patented IOT technology and analytics gives us powerful insights that help our clients grow their businesses and create innovative products that better meet their consumer needs.
PROJECT BACKGROUND / OPPORTUNITY
“Counter Intelligence” is a visionary branded skincare moisturizer from our partner Dr Anita Skincare that is looking to make a major impact in the North American cosmetics market. We believe technology can help Dr Anita Skincare users get more out of their product by helping them with proper application technique, reminding them reapply on a regular schedule and expanding their product use to complimentary products.
We are developing a novel SmartJar package to showcase the launch of Counter Intelligence that will help users apply the product as intended and drive powerful new electronic interactions between consumers and brand using IOT technology and social media. We anticipate the package will be highly aesthetic and also refillable - users will refill their SmartJars many times, minimizing waste and environmental impact.
The core functionality of the SmartJar is to track product usage. This information will be used to enhance the product experience by triggering usage reminders, instructions, warnings when product is about to run out or when product is expired, adapting users regimen to local weather conditions / location. Extended benefits include automatic re-ordering, authenticating product, cross-selling other goods and services and providing remote beauty consultations.
PROJECT SCOPE
The goal of this project is to develop software for the SmartJar, configure a server to track usage and driving response to activity, and develop a mobile app. This project will leverage parts of a system developed last semester by another SDC team.
At the start of the semester, TSG will provide a system at a “breadboard” level ready for programming. Over the semester we will translate this into a hardware prototype.
The SmartJar will include the following IOT technology: sensor inputs tracking when lid is on / off, level of product in the jar and when the user covers one or more light sensing buttons. An embedded microcontroller, power management including wireless power and battery. A/V outputs include a video screen on the jar and audio speaker and LED illumination. The SmartJar should conduct communications via Bluetooth and NFC with a smartphone app capable of running on either Android or iPhone platforms.
CORE DELIVERABLES
- New microcontroller data gathering module
- Gather data from sensors, convert to lid on/off events, jar level, button presses
- Detect and log system issues (power out, sensor failures)
- Store events to buffer
- New microcontroller communication module (device to cloud)
- Establish Bluetooth connection with smart phone using NFC or QR
- Conduct initial pairing with smart phone, reestablish pairing after disconnect
- Transmit event data from buffer to cloud database via smartphone
- New mobile app (to support both iOS and Android)
- App to auto install based on NFC / QR code, pair jar with phone, reestablish on disconnect
- Transmit event data to cloud, transmit media and ruleset to jar
- Navigate to product information (instructions, ingredients, benefits, reviews, testimonials)
- Display product alerts (authentication, usage, level, re-order)
- New Arduino / media delivery module
- Drive video, audio, LEDs
- Display QR code / NFC transmit
- Apply media playback ruleset functionality to drive how events trigger media
- Provide on-screen volume and subtitle control during video segments
- Enhance existing AWS
- Log event data to dynamoDB
- Allow extraction to MS Access
- Remotely manage media playback rulesets
- Store media
- New database analytics module (on server – maybe use SAS ESP?)
- Daily / weekly activity reports
- Alerts (out of stock, low level, power out, sensor fail)
- CRM analytics (follow-up targeting, cross-sell, dwell time)
STRETCH GOALS
- Communication module (cloud to device)
- Receive new media and media playback ruleset from cloud
- Measure signal strength from smartphone, infer distance
- Mobile App extended
- Get location and environment (sunlight, aero-toxins, humidity) information from web
- Use environment to drive regimen alerts and modification selection
- Allow to “like” CounterIntelligence on social media, address feedback to Dr Anita
- Manage opt-in preferences (re-order, email marketing, partner services)
TECHNOLOGY
- We will use a microcontroller programmable in C++ using Arduino IDE
- The A/V system will be a 4D systems RD220 embedded graphics device and programmable in 4DGL, a hybrid of several languages optimized for small screen A/V applications.
- We are presently open minded on mobile programming – it has been suggested to develop in Java (for Android) and port code to iPhone through J2ObjC.
- Our database is presently hosted on DynamoDB. Web analytics may take place in EC2.
Since we will be fine tuning hardware in parallel with programming, having at least one member of the team with hardware design expertise would be a plus. Cosmetics industry knowledge not required.
TARGET AUDIENCE
The team should consider the following stakeholders:
- Skincare users age 12-70
- Dr Anita Skincare personnel
- TSG marketing analytics consultants
BENEFITS TO STUDENTS
- Work at the leading edge of convergence of digital and physical marketing
- Build experience with real world IOT hardware
- Help establish new standards and protocols for the exciting new field of IOT
- Receive positive exposure to 2 potential employers
BENEFITS TO SPONSOR
- Leverage the unique creative capabilities of the full NCSU team
- Gather ideas that may help solve a challenging set of real world problems that are important to our business
OPEN QUESTIONS To Explore
- What languages to use to develop a robust app / port to iPhone
- What are best forms of use interface for an application of this nature
- How to most intuitively navigate on jar
Clinical Data Exchange
Blue Cross Blue Shield of NC
Opportunity
Healthcare payers and providers do not yet have a standard efficient way to exchange and match up claims and clinical data. Payers generate claims data, while providers generate clinical data. Both have separate but important vantage points:
- Clinical data reflects what one provider (or hospital system) knows about the patient based on their encounters with that patient
- Claims data reflects medical history for all of the different providers or hospital systems that this patient may have visited, as well as any prescriptions, and health management programs the person may have used. In addition, this data typically covers a longer period of time.
Clinical data currently is exchanged among provider networks in a variety of different, incompatible formats (Epic, Cerner, Allscripts, and many more). This imposes a serious data continuity problem that makes it practically impossible to link up patient health record data especially for patients that may have moved between providers using different formats.
Solution
Develop simple data conversion capabilities that use the FHIR standard and enable clinical data to be converted between formats and matched to claims data. The goal of this would be to provide strong methods for converting data between different formats, or converting the data to a central format that overcomes the interoperability issue. The scope of this project would most likely be limited to a small number of most frequently used data elements. If possible, develop a set of rules that other teams could reuse to convert other data elements.
Anticipated activities and opportunities for learning
- Gain familiarity with HL7 and FHIR standards.
- Map a CCD XML file to a database.
- Match it to a claims 837.
- Develop a screen to do matching – EMPI
- Develop a longitudinal view of a member based on clinical and claims info.
- Identify ways to use the resulting information to improve healthcare quality scores.
Key Takeaways Expected/Questions to answer
- Which data sets are in highest demand/used most often?
- What set of technology capabilities are needed to enable this capability?
- How does this change/improve the industry’s ability to address healthcare quality?
This project could deliver significant value to an internal initiative we have with the Providers of NC – to exchange clinical and claims data more freely in order to drive better health outcomes for patients.
Note on PHI: The functionality described above would – in a live production environment – be handling PHI and thus would require full HIPAA compliance for all systems and parties. We would not use real PHI for this project. We would need to provide appropriately realistic dummy data so that the resulting rules or functions are assured to work satisfactorily in a production environment later on.
Load Signal Viewer Rewrite
Duke Energy
Overview
Duke Energy provides a web application to external customers for viewing load signal data in its service territory. The term “Load Signal” describes the amount of electricity (in megawatts) that is being consumed at any single point in time. This data is currently used by wholesale energy providers who purchase electricity from Duke Energy. Load Signal Viewer is the name of the web application that has been established to give these customers a view into energy consumption at any point in time. Current functionality shows a live graph that is updated at defined intervals with new data. Users can also download historical data for specific days, seven day periods, and thirty-one day periods. Load data is collected in defined increments and stored in a relational database.
Although the application in its existing state meets the needs of its users, it is dated and in need of an upgrade. The students will rewrite Load Signal Viewer so that it is available as a mobile application and add additional functionality.
Requirements
- The application should be mobile and iOS compatible.
- Display load data graphically at hourly increments. Users should be able to configure the amount of data displayed at one time (i.e. day/week/month).
- Users should be able to personalize their application to set alerts when megawatt thresholds (i.e. min/max) are met. The type of alert should be configurable, such as an application alert, SMS, or email.
- Provide the ability to download data in a tabular format for a defined interval and send it via email.
- Users should be able to graphically compare data between two points in time.
- Users should be able to select views between multiple regions (Carolinas, Florida, Midwest).
- Users should be able to graphically compare data between multiple regions.
Data
The current production system relies on megawatt data that is captured by SCADA systems located at each plant. As part of this project, the team will be provided example data that simulates what a typical load profile looks like. The students will extrapolate this data as needed to populate the application database. This should be done for the three regions above. Data should be displayed in one hour increments. Note that the actual data isn’t important. The user experience and functionality should be the emphasis.
Weather Impacts on Load
As an additional challenge, implement functionality to predict future loads based on changes to weather. For example, if the load was 800 MW at 1:00 PM today while the temperature was 80 degrees, what might it be if the temperature increased to 90 degrees? Users should have the ability to enter potential temperatures in the system and see the change in load expressed graphically. There is no one algorithm for predicting how weather affects load, so students are encouraged to be creative in demonstrating what this functionality might look like.
As a further illustration, with a 24 hour period of test data, students could assume baseline weather, such as sunny and a temperature range from 70 to 90 degrees Fahrenheit. A rule could be created as follows:
- For every 10% temperature increase when the temperature is over 70 degrees, the load increases 5%.
- Any temperature change between 60 and 70 degrees has no effect on load.
- For every 5% temperature decrease when the temperature is under 60 degrees, the load increases 8%
- What impacts might occur if the forecast calls for rain, snow, or an Ozone Alert?
Documentation
Full documentation of the system is required. This includes:
- Source code documentation
- A User’s Guide, in the form of a Word Document, fully describing the features of the system. This is to be a “how to” guide for the users.
- A Technical Guide, in the form of a Word Document, that describes the architecture and major components of the system from a technical standpoint. The intended audience will be software developers who will be providing support for the application in the future.
Interactive User Experience for Pattern Development
IBM – 1
Background
IBM estimates that, back in 2012, the world was producing approximately 2.5 billion Gb of data daily — surely it's much higher today — and almost 99.5% of that data is never analyzed. This unanalyzed data likely holds a trove of insights about the people, processes, and systems that generated it. Since much of the data is text, and most of it is semi-structured, it should be amenable to analysis.
The goal of big data analytics is to fish useful insights out of the rising tide of available data, but the key step of parsing raw data is today built on a shaky foundation. Most tools (e.g. ElasticSearch, Splunk, most Apache parsers, Perl & PCRE) for processing unstructured text rely on regexes, expressions which extend the theory of regular expressions. But regexes are not easy to write and are notoriously difficult to read and maintain, so it’s best to avoid long regexes and also large regex collections. Also, regexes have surprisingly variable performance in practice (even exhibiting exponential behavior), due to inefficient implementations, non-regular extensions, and the proliferation of naïvely written patterns. So it’s best to avoid putting a regex engine in your big data pipeline.
To have a scalable alternative, we have created Rosie Pattern Language (RPL) (github). RPL is a language of parser combinators based on parsing expression grammars. RPL shares some concepts and notation with regexes, but RPL patterns match a superset of the regular languages. RPL is designed like a programming language:
- composable patterns are bound to identifiers;
- comments and whitespace are allowed within patterns; and
- patterns may be grouped into lexically scoped modules.
Such features facilitate the creation, maintenance, and sharing of patterns. RPL matching (parsing) requires only linear time in the input size, with a small enough constant to perform well in practice. Consistent speed makes RPL well suited to big data pipelines. The Rosie Pattern Engine contains a compiler for RPL, a pattern matching engine, and an interactive (REPL) interface. The compiler and REPL are implemented in Lua, but Rosie is callable from Python, Ruby, javascript, Go, C, Perl, and other languages.
Project Scope
While RPL is achieving its goals of usability, scalability, and performance, the project supports just one way of interactively writing and debugging patterns: the Rosie read-eval-print loop (REPL). The proposed project involves the design and implementation of richer experience for pattern writing and debugging. The prototypical use cases are:
- The user is writing a new pattern using sample data. Incremental pattern development is desirable, wherein the user writes a small pattern to match just part of the data, gradually growing the pattern.
- The user must debug a pattern that has failed to match a particular piece of data (which is provided as evidence of the failure). Perhaps a visualization of how and where the pattern failed would be helpful for the user? Or at least a compact description of the failure?
Addressing these use cases will make it easier to use Rosie Pattern Language. (Think of how many "regex debugger" websites there are, and the valuable role they play in regex development!)
Rosie has a unique feature that can be incorporated into the solution: The predefined pattern 'basic.matchall' will match dozens of commonly found pieces of text, such as dates, times, network addresses, and numbers in various formats. Conceivably, the project solution could match sample data using 'basic.matchall' and use the results to highlight known sequences in the sample input, in effect making suggestions on which predefined patterns in the Rosie library may be useful for this data.
The solution should use a browser for its user interface so that it can be hosted on the open internet as a way for people to try out RPL.
Suggested technology
Github for source code and issues, Travis for build, and students' choice of web application frameworks as needed.
Public release of results
Students will be required to publically release their code, documentation, and other results under the open source MIT License at the conclusion of the project.
For more information about Rosie, please see The Rosie Pattern Language, a better way to mine your data.
Source Code Feature Extraction for Automated Software Engineering
IBM – 2
Background
IBM estimates that, back in 2012, the world was producing approximately 2.5 billion Gb of data daily — surely it's much higher today — and almost 99.5% of that data is never analyzed. This unanalyzed data likely holds a trove of insights about the people, processes, and systems that generated it. Since much of the data is text, and most of it is semi-structured, it should be amenable to analysis.
The goal of big data analytics is to fish useful insights out of the rising tide of available data, but the key step of parsing raw data is today built on a shaky foundation. Most tools (e.g. ElasticSearch, Splunk, most Apache parsers, Perl & PCRE) for processing unstructured text rely on regexes, expressions which extend the theory of regular expressions. But regexes are not easy to write and are notoriously difficult to read and maintain, so it’s best to avoid long regexes and also large regex collections. Also, regexes have surprisingly variable performance in practice (even exhibiting exponential behavior), due to inefficient implementations, non-regular extensions, and the proliferation of naïvely written patterns. So it’s best to avoid putting a regex engine in your big data pipeline.
To have a scalable alternative, we have created Rosie Pattern Language (RPL) (github). RPL is a language of parser combinators based on parsing expression grammars. RPL shares some concepts and notation with regexes, but RPL patterns match a superset of the regular languages. RPL is designed like a programming language:
- composable patterns are bound to identifiers;
- comments and whitespace are allowed within patterns; and
- patterns may be grouped into lexically scoped modules.
Such features facilitate the creation, maintenance, and sharing of patterns. RPL matching (parsing) requires only linear time in the input size, with a small enough constant to perform well in practice. Consistent speed makes RPL well suited to big data pipelines. The Rosie Pattern Engine contains a compiler for RPL, a pattern matching engine, and an interactive (REPL) interface. The compiler and REPL are implemented in Lua, but Rosie is callable from Python, Ruby, javascript, Go, C, Perl, and other languages.
Project Scope
A 2016 paper from Stanford makes a convincing argument that there is no need to fully parse source code in order to build a static analyzer. The approach is to build "micro-grammars": expressions that match the parts of a program of interest to the analyzer.
Rosie excels at such tasks, and simple micro-grammars have been written to extract comments from source code, for example (https://github.com/jamiejennings/rosie-pattern-language/blob/master/rpl/language-comments.rpl). Beyond static analyzers, there are many other uses for micro-grammars for source code. Perhaps most important (and urgent) is the field of Automated Software Engineering, in which machine learning and other techniques are applied to improve the software development process. Many kinds of analysis would be enabled by micro-grammar patterns written in RPL, because full parsers for many programming languages are difficult to write and labor-intensive to maintain.
The proposed project is to design and implement a parameterized family of micro-grammars that can do useful things with source code in various languages, such as:
- Extract all the conditional expressions from a piece of code
- Create a graph of the class/object relationships defined in a project
- Map the imports/exports declared across a set of files
- Find all the references to URL literals in the code
The primary use case derives from machine learning tasks in which certain language features are extracted and then analyzed to determine which uses are robust and which are fragile (error prone). The source code may be in various languages, and we envision a solution which is a set of RPL patterns that is parameterized by language.
For example, the import/export patterns for Go will look for 'import' declarations and definitions of capitalized symbols (exports), whereas the import/export patterns for Python will look for 'import' and 'from ... import' declarations, and exports are (implicitly) all defined identifiers that do not start with an underscore. Analogously, each language has its own syntax for conditional expressions, literal strings, etc. However, since languages often share syntactic conventions, it may be fruitful to define, for example, a few kinds of comment syntax, a few kinds of import declaration syntax, etc. Then, a language is defined by a list of which comment syntax it uses, which import syntax, which string syntax, etc.
Creating such a parameterized pattern library and demonstrating its accuracy will enable a wide variety of automated software engineering experiments to be done (in addition to new static program analyzers).
Suggested technology
Github for source code and issues, Travis for build, and a choice of programming language for a test harness; patterns will be written in RPL.
Public release of results
Students will be required to publically release their code, documentation, and test results under the open source MIT License.
For more information about Rosie, please see The Rosie Pattern Language, a better way to mine your data.
Source Control Gamification
Infusion
Business Problem
Source control is a vital, central technology to large software projects, not only to Infusion and our various clients, but to the software industry as a whole. However, the teaching of best practices around how to appropriately utilize source control technologies such as Git are often under-stressed or completely absent in education or training, despite this technology’s widespread use. This can lead to costly mistakes, particularly on projects where lots of people spread across different teams working on the same code – like the enterprise-level software Infusion deals with. As such, we would like to find a way to encourage and reinforce good source control habits in a developer’s day-to-day life.
Solution Description
We would like to create an application or plugin to an existing application (such as Visual Studio) that uses gamification to motivate good source control and Git Flow practices, such as committing early and often, including descriptive commit messages, branching from and merging back to the develop branch – and not breaking the build! We want this application or plugin to be visual in nature to some extent (no command-line wrapper for Git) and include features that make Git and Git Flow more convenient for users (such as auto-fill suggestions, warnings when the user has many un-pushed commits, and statistics so the user can see how they’ve been using Git). We would like to investigate a moderate amount of configurability, but we are focused on the widely-adopted Git Flow standard to limit the scope of the project.
We envision the result as a score tracker recognizes and logs constructive and destructive source control practices, possibly with a leaderboard (care will have to be taken to ensure the program is not annoying or demotivating). We are considering using Git hooks and the Jenkins API to queue builds on commits and award or detract points depending on the result.
If we progress fast enough, we might also consider User Acceptance Testing with your peers.
Technology Constraints
We are focused on Git as opposed to other source control technologies like Mercurial. We would also like to use the Jenkins API for the build server for its relative ease of use and NCSU’s history of using it. Aside from this, we would like to leave technological constraints relatively open for the students to decide.
“Launch Street” Game
Ipreo
Summary
Ipreo is a privately held company that makes and sells software that helps drive all core processes and activities of financialmarkets. Ipreo has software products that start all the way at the beginning of a company’s life and span the entire spectrumof the needs of a company’s lifecycle, including when they go public and become a large, successful publicly traded institution.
In spring 2016, an NCSU team created the first version of a game that we wanted to use for part of our employee training.We wanted an engaging simulation that while playing, also creates a fundamental understanding of why companies would useour software by the different people in all parts of the IPO cycle.
Background
One of the challenges we face when we hire new people is training and onboarding. It's usually not difficult to find talenteddevelopers. It's much more challenging, however, to find software engineers who are also well-versed in the world of highfinance. Therefore, most of the time when we hire new talent we not only have to make sure they’re fully immersed in howwe develop software, but also fundamentally understand the customers who use our software, how they use it, and which featuresare most important.
We are looking for a repeatable way of training our employees, at a high level, to learn how the world of high finance works.It needs to be engaging and immersive so people want to pay attention and get better.
Technology
The original team used Unity and .Net to create the game and we would like to continue their usage as much as possible. Ipreois mostly a Microsoft shop. There are exceptions, but many of our databases run on SQL Server, a lot of our code is writtenin .NET, our web servers run on IIS.
The most important part is the creation of a fun, engaging game you’re proud to have been a part of, and that it helps ournew employees get up to speed faster and without having to sit through hours of boring presentations.

This semester
The first version of the game focused on what it’s like to be an entrepreneur and take a business from you and a partnerstarting out, move to finding angel funding, and then going public. We have a couple of ideas for the next iteration ofthe game and need your help to see it succeed.
- The other major players in the IPO process are the Investment Bank and the investors themselves. Investment Banks are alsoIpreo clients and having a way to represent their view of the process would be ideal. Investment banks choose/bid onwhich companies to take public as well as pitching them to investors. The IPO process for them has a lot to do with roadshows,prospectus, and support in the secondary markets once it’s live.
- Having this as a multi-player option is possible and it’s ok if it’s a standalone game mode also.
- A graphic update is very possible.
- Iteration on the original gameplay could improve the playability based on player feedback. The core game loop feels solidand can likely be further iterated on.
Thank you and good luck. We can’t wait to see what you’ll create.
Note: Students will be required to sign over IP to sponsor when team is formed.
Enterprise Application Integrated Training Portal
KPIT
Most enterprise systems have out of the box reference material in a lot of different locations in the UI that goes to generic, vendor-provided information on a specific topic. Many customers have their own internally developed (and often process specific) material that should be referenced instead. For example, KPIT uses Windchill (a PLM software) and Moodle (open source LMS software) but currently the two systems are not connected.
We would look to the senior design team to come up with a solution for providing a method of linking together these enterprise systems so that a request can be made for training material from within the PLM system and relevant content will be returned to the user from the LMS system. KPIT will provide access to an existing Moodle environment that has some data populated.
Deliverables should include:
- Code developed in Java (compatible with most PLM systems) that will take input on keywords and search Moodle for relevant material
- Simple GUI for testing/demonstration purposes to show functionality of the developed solution
- Time permitting—implement with PLM side for testing/demonstration rather than using the GUI
Natural Language Processing (NLP)
LabCorp – 1
Natural-language processing is the use of more than 20 different natural language tool classes. It can ease human-computer interaction; help people to find, understand and act on natural-language content; and provide the foundation for inferences that make people more effective.
LabCorp® is looking to sponsor an NLP project, which explores the usage of NLP frameworks and technologies in the medical field. All aspects of the laboratory industry deal with various standards, publications, and terminologies, which enlighten test results for physicians and patients alike. The outcome of the project should explore the translation of text based on domain-specific standards and create meaningful instructions for a computer system.
Expectations and Goals
The student development team will engage on a regularly set schedule with designated mentors from LabCorp®. LabCorp® will provide guidance about enterprise scale architecture and technologies, but leave the students engineering creativity a focus point of the project. We will encourage and maintain an ongoing dialogue with the team about how modern research from the students can enhance existing approaches.
The outcome of the project should create a demonstrable solution, which could enhance decision support for physicians, medical laboratories, insurance companies, and patients. The idea of the project is to apply measured and collected information by a laboratory and query in several steps public or proprietary literature and recommendations to enrich the measurements with more guidance for physicians or computer systems. NLP will be used in this program to read the free text and translate this into computer understandable instructions. The instructions in return will be validated against the lab data and historical results from de-identified patients. The solution will have many practical applications for outcome reporting or visual enhancements for a better user experience.
About LabCorp®
Did you know that the largest healthcare diagnostics company is right in your backyard? Based out of Burlington, North Carolina, LabCorp® has a lot of different research and development centers around the country including in the Research Triangle Park (RTP) in North Carolina.
Laboratory Corporation of America® Holdings (NYSE: LH), an S&P 500 company, is the world’s leading healthcare diagnostics company, providing comprehensive clinical laboratory and end-to-end drug development services. With a mission to improve health and improve lives, LabCorp delivers world-class diagnostic solutions, brings innovative medicines to patients faster and develops technology-enabled solutions to change the way care is provided. With net revenue in excess of $8.5 billion in 2015, LabCorp’s 50,000 employees serve clients in 60 countries. To learn more about LabCorp, visit www.labcorp.com, and to learn more about Covance Drug Development, visit www.covance.com.
Speech to Action
LabCorp – 2
Speech-to-speech translation involves translating one spoken language into another. It combines speech recognition, machine translation, and text-to-speech technology. Speech to Action or an actionable expression for computer systems enhances medicine by allowing hands-free interactions with medical equipment.
LabCorp® is looking to sponsor a speech-to-action project, which explores the usage of speech-to-text and NLP frameworks and technologies to be applied to the medical field. The outcome of the project should explore the translation of speech to text for the use in operational environments to assist in traditional interaction with computer systems in addition to keyboard, touch, and mouse interfaces. The identified command in such a speech-to-action system should enable triggering actions through a reusable software framework, which could be embedded or executed from a lightweight JavaScript library.
Expectations and Goals
The student development team will engage on a regularly set schedule with designated mentors from LabCorp®. LabCorp® will provide guidance about enterprise scale architecture and technologies, but leave the students engineering creativity a focus point of the project. We will encourage and maintain an ongoing dialogue with the team about how modern research from the students can enhance existing approaches.
The outcome of the project should create a demonstrable solution, which could enhance decision support for physicians, medical laboratories, insurance companies, and patients. The idea behind this project is to enable medical trained personnel to request standard voice commands without requiring to put their fingers on keyboard, mouse or screen, which may be important in sterile environments or improve the speed and accuracy of their work. The solution can emphasize visual enhancements for a better user experience or focus on the research of syntax and algorithms for a unique outcome.
About LabCorp®
Did you know that the largest healthcare diagnostics company is right in your backyard? Based out of Burlington, North Carolina, LabCorp® has a lot of different research and development centers around the country including the Research Triangle Park (RTP) in North Carolina.
Laboratory Corporation of America® Holdings (NYSE: LH), an S&P 500 company, is the world’s leading healthcare diagnostics company, providing comprehensive clinical laboratory and end-to-end drug development services. With a mission to improve health and improve lives, LabCorp delivers world-class diagnostic solutions, brings innovative medicines to patients faster and develops technology-enabled solutions to change the way care is provided. With net revenue in excess of $8.5 billion in 2015, LabCorp’s 50,000 employees serve clients in 60 countries. To learn more about LabCorp, visit www.labcorp.com, and to learn more about Covance Drug Development, visit www.covance.com.
End-to-End Distributed System Tracing
Bronto
Bronto Software offers a sophisticated marketing platform for its corporate clients, tracking billions of events per month. Customer events such as opens, clicks, and purchases (conversion) are recorded and analyzed in real-time and displayed to our customers to give them a clear view of how their campaigns are performing.
Project Description
For Spring 2017, the Bronto Senior Design Team will create software for end-to-end distributed system tracing at Bronto.
The Bronto Service-Oriented Architecture (SOA) consists, primarily, of Java services. These services communicate with each other in two ways: HTTP (REST clients) and Bronto’s homegrown message broker, Spew. Spew is similar in concept to AMQP brokers such as RabbitMQ. The goal of this project is to set up an instance of a distributed tracing service (such as Twitter’s open source Zipkin) and integrate it with existing HTTP and Spew clients in Bronto’s services. Work may also involve creating new PoC Java microservices to test out Zipkin before integrating with the existing Bronto codebase.
Key Concepts and Technologies
The NCSU team will get a chance to work with Java microservices, REST over HTTP, AMQP message brokers and distributed systems tracing (Google’s Dapper whitepaper provides the inspiration for Zipkin and a good introduction). The team will have opportunities to select appropriate technologies for the project; these may include Java 8, Jersey, various REST client libraries (e.g. Apache HTTP client, Jersey client), Grizzly (Java HTTP server), Zipkin, Kafka, and Dropwizard (metrics and/or its Java microservice framework).
S3 Client Interface for iRODS
EMC
Background
The Integrated Rule-Oriented Data System is a popular open source data management software platform used for data management and orchestration by Life Science researchers, archivists, and even meteorological organizations. The key benefits of iRODS which stand out to many users are:
- Data Virtualization
- Data Discovery
- Workflow Automation
- Secure Collaboration
iRODS is essentially middleware that provides:
- Data virtualization which abstracts away the peculiarities of physical storage devices into a common abstract connection model supporting long-term data curation
- A machine- and user-defined metadata catalogue which can scale and grow independently of the data storage
- A sophisticated, user-programmable rules engine which can perform any machine actionable activity on data, based on the metadata in the catalogue
- Strong security control which supports wide-area and cross-data-grid collaboration.
You can learn more about iRODS and it working principles via a technical overview brief located at:
https://irods.org/uploads/2016/06/technical-overview-2016-web.pdf
The goal of this project is an attempt to make iRODS easier for non-programmers to use. We will build a prototype plug-in for iRODS, which will allow a system to connect to an iRODS grid as if it were an Amazon S3 client using tools like CyberDuck or S3browser.
Project Scope
The NCSU team will have the opportunity to help determine many aspects of the project and their development process. At a high level we believe the work effort breaks down into the following aspects:
- Set up a 2 or 3 node iRODS grid, which will be used for experimentation and analysis.
- Investigate and understand the C library bindings for accessing iRODS for I/O purposes. iRODS can tie to S3 storage as a back-end storage device. This code (in the iRODS source) may be a good starting point for understanding.
- Decide on an S3 client to use for connecting to the code you will design. We suggest you use an open source tool so you have source available for problem-solving.
- Understand how to build a plug-in I/O interface module for iRODS. This may be easily done via study of the S3 interface.
- Decide whether to build the interface software from scratch or look to see if some open source project provides some capability you can build on.
- Develop prototype code and implement functionality in pieces. For example:
- Basic connection to iRODS via the S3 interface
- Authenticated connection to iRODS via the S3 interface
- Navigate to a bucket
- List objects in a bucket
- Read an object
- Write an object (no multi-part)
- Delete an object
- Explore the possibility of support for a multi-part read/write
How far this project is able to get in full implementation specifics will depend on how complex some of the preliminary tasks prove to be.
The infrastructure for this project can be implemented using virtual machine technology and requires no special equipment.
We are working to arrange participation by members of the iRODS Consortia to help with deep technical questions and advice.
Benefits to NCSU Students
This project provides an opportunity to attack a real life problem covering the full engineering spectrum from requirements gathering through research, design and implementation and finally usage and analysis. This project will provide opportunities for creativity and innovation. Dell EMC will work with the team closely to provide guidance and give customer feedback as necessary to maintain project scope and size. The project will give team members an exposure to commercial software development on state-of-the-art industry backup systems.
Benefits to Dell EMC
The work, if successful, we will look to either document or put into open source via the iRODS community to help with adoption of the technology. There is an existing customer community which requires S3 client interfaces to iRODS in order to adopt the technology.
Company Background
Dell EMC is a part of Dell Technologies. Dell Technologies is the world’s largest privately held technology company. We strive to be the essential infrastructure company – from the edge to the data center to the cloud – not only for today’s applications, but for the cloud-native world we are entering. We do this by:
- Creating and providing innovative products and solutions which meet customer needs
- Being a trusted partner and advisor to our customers providing insight that allows them to leverage their data and infrastructure to it maximum potential
- Providing solutions and services to aid our customers in their digital transformation journey
- Innovating to solve the complex computing and application infrastructure problems of today and tomorrow.
The Research Triangle Park Software Design Center is a Dell EMC software design center. We develop world-class software that is used in our Unity storage, DataDomain, and RSA security products.
Cookomatic
Entrepreneurs
Summary
Our goal for this project is to create an application that generates a cooking schedule to cook a full meal efficiently and such that all dishes finish cooking at the same time. At the moment, there is no existing product on the market that allows for a user to keep track of multiple cooking timelines. Users will be able to import recipes from websites that we support and the schedule will be generated. This idea stems from our own experience with cooking at home and having to warm up cold food because we failed to properly synchronize the cooking of our dishes.
See the mockup application at http://www4.ncsu.edu/~rlhefner/cookomatic (best viewed on a mobile device).
Technical Details
This project entails creating a multi-platform mobile application. The local application would handle all of the user’s interaction: finding recipes, adding dishes, starting the cooking timer, and getting notifications to complete each step. The backend would handle synchronizing account data across devices, maintaining a recipe database for all users, and overall analytics of the service.
For the frontend, we want to use React Native, an Apache Cordova based framework, or a similar technology so that we can target iOS and Android without writing the same app twice. From our analysis, this application’s needs can be met by these frameworks.
For the backend, we want to use a Platform as a Service to host our compute and database workloads. There are many options such as Google App Engine, AWS Lambda, Firebase, etc. that we will look at before our final decision.
Chatbot
Fidelity Investments
Company Overview
At Fidelity, we are focused on making our financial expertise broadly accessible and effective in helping people live the lives they want. We are a privately held company that places a high degree of value in creating and nurturing a work environment that attracts the best talent and reflects our commitment to our associates.
Twelve petabytes of storage. 9,200 servers. 850,000 trades a day. 1,100 transactions per second. 40+ patents. 12,000 technologists. Fidelity Investments is not just a world-class financial institution – we're also a top-tier technology company. Our technology organization focuses on new, forward-thinking ideas. We invest in continuous research, effective deployment and rapid adoption of game-changing technology platforms.
Project Overview
Workplace Investing (WI) is a business unit of Fidelity Investments and this project will be exploring chatbot technologies that will help improve the user experience and accessibility of our applications. WI serves companies and their employees through our web and mobile applications, providing 401k, Health & Wellness, Stock Plan Services and more to employees of thousands of firms. Our millions of users depend on our applications to plan for their retirement and the project concept is to explore how a chatbot type interface could add value to our existing products. In order to develop the experience we’ve decided to start with an internal experience for our Fidelity associates and providing a new way to interact with our internal ticketing system that we use to track tasks and resolve incidents with our applications.
The Fidelity Investments Senior Design Team will develop a chatbot that will use natural language conversation to assist associates in day-to-day tasks, increasing efficiency and reducing redundancy. The project goal is to integrate the chatbot with existing platforms used at Fidelity, such as ServiceNow for support tickets, Splunk for application logs, and Jenkins for build/deployment status. When asked a question the chatbot should be able to interpret what is being asked and either execute the request and return the information in the chat interface or prompt the user for more information. The chatbot is only the user interface for accepting requests from the user, which will then be processed to map natural language input to a set of predefined actions that the bot can perform to return the desired information to the user. The interface can be built to conform with a specific platform, such as Microsoft Skype, or it could be built entirely from scratch. The second element to this solution is the service that will be receiving the user requests and mapping them to the predefined actions.
After some initial research, we have found that API.AI will provide us with the infrastructure needed to meet these goals. However, if there is another tool the students would like to use they can present us with research for consideration. The main goal will be to integrate with HP service manager by creating tickets, modifying tickets, searching key words in tickets, emailing the ticket owner, etc. This will benefit the firm by reducing time spent opening repetitive tickets and tracking down owners.
Example requests for ServiceNow Ticketing System:
Q: What tickets have been opened in the past 24 hours?
[Alternative Format of the Same Request: In the last day, what tickets have been opened?]
A: [list of ticket number and title]
Q: Tell me about ticket M8976533.
[Alternative Format of the Same Request: What’s the summary of Ticket M8976533?]
A: Participant unable to login. Severity 3. Assigned to Christian Hausle.
Q: What is the status of ticket M897667?
[Alternative Format of the Same Request: Ticket M897667, what’s the latest status?]
[Alternative Format of the Same Request: Give me the latest status for ticket M897667.]
A: Ticket M897667 was closed on Tuesday 1/03/2017 with a resolution “Error in configuration file causing service to respond with 404. Config was updated to correct endpoint and the 404 has stopped.”
Stretch Requirements should the team have capacity:
Splunk Integration: Can the user ask if there have been any 400 errors in x-application?
Jenkins Integration: Ask when the last successful build for x-application was. Ask to deploy x-application.
References
https://chatbotsmagazine.com/the-complete-beginner-s-guide-to-chatbots-8280b7b906ca#.vnyl6zitm
https://hubot.github.com/ (open source chatbot framework as an alternative to Microsoft platform, if that’s the preference of the project team)
https://api.ai/ (bot development framework that includes NLP, the bot can then be ‘integrated’ with different platforms like Skype, Alexa, Cortana, Twitter, or Slack. Purpose is to transform natural user language into actionable data in JSON format.)
MarketPlace Migration & Refactoring
Fujistu America
Fujitsu America is one of the top three suppliers of retail systems and services worldwide. Using Microsoft’s .NET development platform, these systems offer a high-performance yet open platform that retailers as diverse as Nordstrom, RadioShack and Dressbarn are able to customize.
Large software projects must periodically undergo refactoring. If the project itself is a Software Development Kit (SDK), the refactoring can affect the solutions dependent on a prior version of the SDK. The work to adopt a new SDK can often require human effort and be tedious and error prone. If the process could be at least partially automated, there could be significant programmer productivity improvement, as well as speedier adoption of the new SDK.
Fujitsu is confronted with one such migration caused by the ‘relocation’ of hundreds of classes to different namespaces between two versions of their SDK. Such a migration is likely in the future as well, so automation processes are of great interest. While the SDK in question is written in C#, the consumers of the SDK are both C# and VB.NET. The complexity of this transformation largely rules out simple text editor automation because the migration is likely to affect both the consumer source code and the project structures that build that source code.
A key enabler of automation for this project is the Roslyn compiler published as open source by Microsoft® with Visual Studio 2015™. This compiler allows programmatic access to source files in the same navigable expression tree as the compiler itself uses. Modification of the source can then be done reliably within that context.
Project Areas and Primary / Stretch Goals
In this project, the following steps (at least) are required:
- Metadata tagging of code artifacts. Since the namespaces (and perhaps names) of classes are different between SDK versions, a mechanism must be developed to initially uniquely identify the artifacts
- Transformation mapping. Once the artifacts are tagged, the from-to mapping must be created to identify how to transform both code and associated build projects. This may require reflection across the compiled binaries of the SKD, as well as inspection of the source file trees with the Roslyn compiler
- Microsoft projects are XML-based and contain references to the specific compiled elements (assemblies) that form the execution dependencies. If the transformation has changed the assembly in which the artifact is compiled, the project needs to be modified appropriately. Similarly, the code element will require modification to adjust namespaces if not class names.
Input and Goals
As input to this project, Fujitsu will provide a sample before and after SDK (in source and compiled form) as well as a sample consumer of the before SDK in both C# and VB.NET.
The goal is to run the automated transformation and have a compatible version of the sample consumers using the new SDK.
As a stretch goal, Fujitsu will run the transformation against an actual customer project under the direction of the team.
Tools Needed
- Enterprise Architect (v13)
- NCSU had access in Fujitsu project in Spring 2016.
- Visual Studio 2015
- SNIP
PIGFARM
LAS
The LAS Senior Design Team will create a software system that will merge similar Apache Pig jobs together to reduce diskread/write access in Pig MapReduce jobs (hence the name PIGFARM). MapReduce is a parallel programming paradigm popularizedby Google in a paper they released in 2004. MapReduce breaks computing tasks into a map step and a reduce step.The mappers work on data stored locally on a node and send their output through the network to reducers that finish thecomputation. Apache Pig is a high-level language that describes a data transformation workflow which is compiled into oneor more Java MapReduce jobs and deployed on Hadoop. The Apache Hadoop software stack (that includes MapReduce) is probablythe most common big data analytic software stack in the world. During the semester, students will set up experiments ona Hadoop cluster to verify that their code works and to measure improvements their software makes to the Pig MapReducesystem. A byproduct of this effort is in the area of “analytical collaboration” which seeks to help data scientists andanalysts better understand common practices among disparate business units. A stretch goal for this semester will be ananalysis of the similarity of data flowing through similar Pig scripts.
Motivation
Large institutions and firms often have data scientists embedded throughout their business units, who create custom analyticstailored to these units’ needs. A commonly used platform for these analytics is the Hadoop MapReduce implementation, andApache Pig is a high-level language abstraction for MapReduce that simplifies and lowers the barrier of entry into MapReduceanalytics. Often, multiple analytic solutions need to access the same datasets. If these solutions are created in an uncoordinatedmanner and run in separate jobs, they may cause more disk I/O in the Hadoop system than is needed (and disk I/O is oftenthe largest bottleneck in MR jobs). Merging the various MR jobs that access the same data into one large job should reducethe disk I/O for the overall system and increase analytic capacity and throughput for the system as a whole.
Details
The Senior Design student team will, over the course of the semester:
- Design experiments on a Hadoop cluster to test the performance of their system. The initial data set will be based on thefreebase RDF triple store, which is 1.9 billion records and 250GB uncompressed. The students will create multiple pigscripts that perform analytics upon this dataset.
- Create a script (in python) that will compile a set of independent Pig scripts into a single Pig script. This script willmerge all of the LOAD statements that access the same data from the various scripts into a single LOAD statement, andthen rename all of the following variables in the rest of the script to assure consistent execution.
- Compile the multiple Pig jobs from step one to automatically create a single Pig job and test the improved performanceon the Hadoop cluster.
- Document the experimental outcomes, the PIGFARM software, and user guide for the project.
Learning
Students will gain hands-on experience with Hadoop, Map/Reduce computing, and the Pig MR scripting language.
Random Fact: North Carolina is the second largest pig farming state.
Source Code Static Analysis
Premier – 2
About Premier, Inc.
Premier, Inc. (Nasdaq: PINC) is a healthcare performance improvement alliance of approximately 3,600 U.S. hospitals and 120,000 other providers. Our mission is simple: To improve the health of communities.
As an industry leader, the Premier alliance has created one of the most comprehensive databases of actionable data, best practices, and cost reduction strategies. Our award-winning and revolutionary technologies enable our members to collaborate more easily and efficiently. Our goal is to improve our members’ quality outcomes, while safely reducing costs. By engaging members and revealing new opportunities, we empower the alliance to improve the performance of healthcare organizations.
Project Description
The Premier Senior Design Team will develop a static code analysis tool that can be applied to a number of large software projects. The tool will analyze the methods, functions, APIs, and web services to create a visual map of the modules, files and, ideally, database tables / values used. It will use different size and colors to emphasize the modules or areas that are most commonly used vs others that might be not used at all. The tool will suggest options for splitting the code into independent modules by externalizing APIs through web services or other technology. Ideally, this tool would be language-agnostic (although support for just .NET would be fine).
When completed, this tool will be used by development teams to analyze dependencies within large monolithic applications and create a path forward for breaking them down into modules and micro-services. This project could be applied to a large, existing code base. This may require legal approval to provide such a code base for students to work with.
Python-to-C++ Native Interface
SAS
SAS has a lot of C++ libraries that we would like to use in other language runtimes. Some languages like Java, make this simple with their Java-Native-Interface code generators. Python has similar language bridging features, and we would like to provide a similar but more robust code generation tool that would make these C++ libraries available from Python as well.
Students will be provided a sample C++ library and a set of XML files describing the library’s public API. The API will be described using the SAS ROBOTS class description syntax. The tool will parse given XML and generate Python interface. In particular, the tool will need to provide:
- The ability to call all the public/modeled C++ API from Python, using appropriate Python idioms and usage patterns.
- Appropriate conversion of arguments types and return values between Python and C++.
- Efficient lifetime management of the memory whose ownership passes across the interface (e.g.: correct cleanup of C++ objects that are owned solely by python objects).
The tool may be written in either Java or Python (preferably Java). When the project is complete, it should be possible to use a C++ library from Python using syntax like the following:
from awesome_library import A, Ba = Noneb = Nonedef call_stuff_in_scope():a = A() # construction of c++ objectsb = B()assert a.value() == 'A' # API calls on c++ objectsassert b.value() == 'B'def ensure_object_was_cleaned_up(o):# <implementation details left to students># returns True if python’s ownership of c++ object was released, else Falsepassassert ensure_object_was_cleaned_up(a)assert ensure_object_was_cleaned_up(b)
Budget Staffing Planner (BSP)
Schwab Performance Technology
Schwab Performance Technology (SPT) is a subsidiary of Charles Schwab that builds comprehensive technology offerings for end investors and for financial advisors to help them manage their business and their client’s investments. A large part of SPT’s technology team is based in Raleigh, NC. This team develops applications for desktop, web, and mobile platforms that provide industrial-strength solutions using technologies and frameworks such as C#, Mongo, SQL, C++, HTML5, Angular.JS, JSON, and REST. We concentrate on the fundamentals of architecture, design, development, and quality assurance to build applications that stand the test of time, which is critical in the financial industry.
Project Description
Annual budget planning and staffing adjustments can take up hundreds of hours across an organization. As proposed budgets are adjusted and teams are altered, the corresponding documentation must be updated. There are tools to handle budget allocations and tools to show team organization but little exists to tie these two things together.
The Budget Staffing Planner (BSP) will offer a comprehensive solution to allow team updates to be reflected against the budget and provide automatic team and managerial diagram updates. Ultimately the tool will be used continuously as plans change throughout the year. It will allow Schwab to efficiently plan staffing against budgets and reduce the overhead of generating multiple versions of documentation as the plans change. BSP will be a true application development effort, with a focus on customer (Schwab managers) efficiency and a complete end product based on specifications.
The team will provide methods to enter data about the budget, staff, teams, managers with organizational hierarchy, etc. This will be a grid like data entry and will require allowing some standardization and customization of the data being entered (e.g. configuration screens for team names). The grid layout must be printable.
Organization and Statistical Display
The BSP will offer printable application screens that show team members and that show organizational reporting structure. It will also display a variety of statistical information about projects, teams, and organizations. Examples of this information are staff roles, staff levels (e.g. senior, associate), location, full time vs. contingent, etc. Forecasted spend vs. budget for multiple projects must be available. The application will show this information in tabular as well as a range of graphical formats and must be printable.
Time Base Team Movement and Budget Spend
The initial implementation can assume that team members are on a team for the full year. If all other requirements can be met, the application will be upgraded to allow monthly staffing movement. Additionally, budgets must be able to be set with different monthly spends. The result of this upgrade is all displays must then allow point in time (monthly) views.
Advanced Staffing Movement and Graphical Staffing Movement
A stretch goal is to allow a graphical method for moving staff from one team to another on the visual displays and to provide simpler methods of getting to the underlying tabular data for staffing movement. For example, flipping two team members by simply dragging them to their appropriate teams and having all associated data updated. Another possibility is selecting one to many team members on the graphical display and using that as a filter for a grid display to simplify showing the tabular version of the staff requiring edits. The team will be asked to propose solutions that enhance usability and will be required to interview the customer in order to determine options that will simplify the workflow.
Project Approach and Technology
The project will be based on some of the technologies SPT has been using for product development. This list may be altered depending on the teams’ existing technology strengths. SPT technologies may include
- C#, JavaScript, and/or HTML5 may be used for the project development based on the team’s abilities and desires
- REST for web services if required
- SQL for the database
SPT strives to develop using best practices while remaining agile. We use the SCRUM and Kanban methodologies and will run the senior project within a similar methodology used by our teams. One mentor will be selected from our development team to be the primary interface with the project team, but other members of our staff will be brought in from time to time to assist with the project.
Project Success
Success will be based on the following accomplishments
- Participating using a SCRUM methodology to understand the benefits of agile development.
- Requirements (epics and user stories) will be provided to the team by the SPT staff. The team will successfully groom the user stories to provide initial estimates.
- Breaking down the user stories into logical tasks and providing task estimation. This will be used to prioritize features within the semester’s time box.
- Architectural and design documentation produced for data and user interface components. A variety of UML and white boarding documentation will be used.
- Producing quality code (well organized, performant, documented)
- Developing a test strategy for unit, component, and overall quality assurance.
- Working application based on the initial requirements and negotiated prioritization completed and demonstrated to internal SPT staff.
SPT is interested in engaging with the brightest students in top-tier computer science programs. New projects have allowed us to open a number of positions for recent and upcoming graduates. We hope to establish strong ties with the best students during their senior year, which could then lead to jobs opportunities when they graduate.
Project Archives
| 2026 | Spring | Fall | |
| 2025 | Spring | Fall | |
| 2024 | Spring | Fall | |
| 2023 | Spring | Fall | |
| 2022 | Spring | Fall | |
| 2021 | Spring | Fall | |
| 2020 | Spring | Fall | |
| 2019 | Spring | Fall | |
| 2018 | Spring | Fall | |
| 2017 | Spring | Fall | |
| 2016 | Spring | Fall | |
| 2015 | Spring | Fall | |
| 2014 | Spring | Fall | |
| 2013 | Spring | Fall | |
| 2012 | Spring | Fall | |
| 2011 | Spring | Fall | |
| 2010 | Spring | Fall | |
| 2009 | Spring | Fall | |
| 2008 | Spring | Fall | |
| 2007 | Spring | Fall | Summer |
| 2006 | Spring | Fall | |
| 2005 | Spring | Fall | |
| 2004 | Spring | Fall | Summer |
| 2003 | Spring | Fall | |
| 2002 | Spring | Fall | |
| 2001 | Spring | Fall |