Projects – Fall 2021
Click on a project to read its description.
Sponsor Background
Bandwidth provides cloud-ready voice, messaging, and emergency service connectivity built for the enterprise. Bandwidth’s customers perform millions of requests per day and this project will help guarantee these requests meet our developer’s specifications.
Background and Problem Statement
Bandwidth designs their APIs using specifications in either json or yaml before implementation. These specifications can be generated via code, annotations, or handwritten by developers, and are used to model both internal and external customer facing APIs. We are looking to validate between our specifications and APIs. This ensures that our APIs are performing as they were designed under the specification.
Project Description
A potential solution for this project may include creating or utilizing an existing specification parser to build a contract testing platform. We are specifically interested in the following guarantees between our specification and APIs.
- The specification is an accurate representation of our APIs.
- Existing consumers of the APIs are not broken with specification changes.
We are also open to any additional validations you can think of!
The solution should allow for our specifications and APIs to be validated from within our GitHub Actions CI/CD pipeline where errors in accuracy and breaking changes are reported. Be creative, how will the results be displayed? What development languages will be used? It’s up to you!
Technologies and Other Constraints
Our constraints are intentionally open ended, allowing for a creative solution to the problem. Our specifications are defined using the OpenAPI standard and must be verified against REST APIs.
An additional constraint placed upon the project is that the end result be executable via GitHub Actions and allow for passing or failing the pipeline. We would like to run this as part of our CI/CD pipeline and DevOps strategy in production.
A mix of homegrown and/or open-source solutions may be required to meet the end goal. Be creative!
Sponsor Background
Deutsche Bank is a German multinational investment bank and financial services company that ranks amongst the top banks in Europe. It spends multi-billion dollars on maintaining and updating its IT.
NCSU’s Senior Design project is a perfect opportunity for our Cary-based IT teams to engage with the students and develop a tangible product that is useful in solving some of our software related needs.
Background and Problem Statement
Communication and Collaboration is key to smooth functioning of geographically dispersed teams in our org. Over the past few years VR technology has steadily matured. A number of options across both the hardware and the software have opened up, such as :
- Hardware: Google VR, iOS/Android/Google Cardboard, HTC Hive, Google Daydream, Oculus Go/Quest/Rift, Lenovo Mirage etc.
- Software: Unity 3D, Autodesk Revit, Unreal Engine, Maya, Google VR SDK, Open VR SDK, Amazon Sumerian, Oculus SDK, Unreal Engine etc.
We are interested in leveraging some of these techs for developing a mobile app and/or a website that would make our in-house presentations/demos immersive, interactive and memorable!
Project Description
This will be a greenfield project. Hence, in the initial few days we will work with students and collectively evaluate the multitude of available H/W and S/W options and decide on the most viable ones.
The initial goal is to develop a MVP ( minimum viable product) wherein a traditional PowerPoint-slides-deck of say 5-10 pages could be presented using VR. Once this is achieved, students will then explore and develop additional interactive features for that product, if time permits.
Technologies and Other Constraints
We would prefer to have the product usable over a set of VR goggles. Prior experience with VR technologies will be beneficial.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
You can’t protect what you can’t see. JupiterOne is a Morrisville, NC based cloud security start-up that provides security practitioners a complete view of their organization’s cyber assets, including user permissions, source code repositories, cloud infrastructure, and more. More importantly, JupiterOne’s cloud-native graph database enables security teams to use the relationships between their cyber assets to detect and remediate complex configurations that may leave their organization vulnerable to attacks.
Using information from JupiterOne’s open-source integrations, security teams could identify a Snyk code vulnerability that targets a Github repository that publishes an NPM package that’s used to deploy a container in AWS. These cross-platform relationships shine light across the entire potential attack surface and enable the team to quickly remediate all the affected resources before an attacker can target them.
Background and Problem Statement
Security is not a zero-sum game. When security engineers from different organizations collaborate to improve their security posture, everyone wins (except for the attackers!). This is why JupiterOne is so passionate about creating open-source software - by building our integrations to Azure, GCP, Github, and others in the open, we expose robust graph-based ingestion engines that can be audited and continuously improved with input from the security community.
Most of JupiterOne’s integrations are open-source and can easily push data into the JupiterOne platform using our open-source SDK. However, we want to enable even those security practitioners who don’t use the JupiterOne platform to benefit from the vast codebase (>70 repositories and growing daily) that we have built to ingest cyber assets into a graph database.
Project Description
The JupiterOne engineering organization has been developing and maintaining an open-source integration SDK for Node.js. This SDK exports a command (yarn j1-integration collect) to execute any of our integrations locally in order to generate what we call entities and relationships (nodes and edges in graph DB terminology). It also currently exports a command (yarn j1-integration visualize) to convert those entities and relationships from yarn j1-integration collect into a rudimentary HTML-based graph using Vis.js. See example output below:
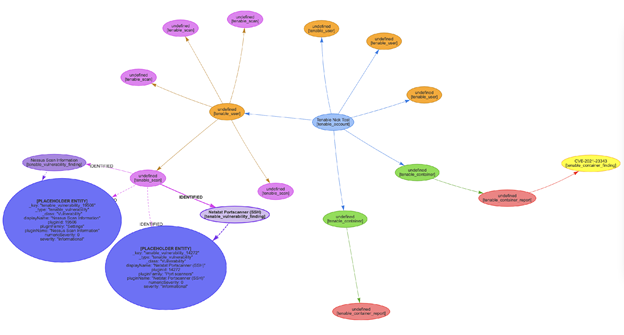
Like the rudimentary HTML tool, the students should leverage the output of yarn j1-integration collect to collect entities and relationships. The students should develop a new tool to push the outputs from yarn j1-integration collect into a graph database. The graph database could be local or remote, but the students should make provisioning a local graph DB simple - using a container would be ideal. Users of this tool may need to manage the addition and removal of single entities/relationships OR entire datasets, and should be able to easily manage CRUD operations for either.
Possible stretch goals include:
- JupiterOne uses the concept of mapped relationships, which are essentially a relationship where only one of the two nodes is known. The students could implement mapped relationship resolution, or either identifying/creating the second node, when mapped relationships are encountered.
- The students could use a query language like Gremlin or Cypher to build complex queries once entities and relationships have been pushed into the graph database. These queries could even be stored in version control for testing purposes OR to share actual security controls with users of this tool. These queries would be the Gremlin equivalent of JupiterOne Query Language (J1QL) queries found here: https://ask.us.jupiterone.io/.
- The students could enable the tool to ingest other open-source graph ingestion tools such as Cartography for collaborative security analysis.
- Other goals may emerge depending on the project schedule.
Technologies and Other Constraints
JupiterOne’s existing open-source tools leverage Node.js, so the students will need to use Node.js at least when interacting with ingestion projects and the open-source integration SDK. We prefer that the students use the CLI to push entities and relationships into the graph database.
Required tools:
- Open-source graph database: Neo4j
Optional tools:
We encourage the students to explore alternatives in each of the below, but we have listed our preferred technologies across this project:
- Graph query language: Gremlin
- Local containers: Docker
- Runtime: Node.js, Typescript
We license our open-source software using MPL-2.0 and would expect this work to use the same.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Outer Banks Blue is a vacation rental management company representing approximately 300 properties located on the northern outer banks of North Carolina that has been in business since 2005. Sandbridge Blue, established in 2010, manages the rentals for approximately 80 properties in the Sandbridge, Virginia area.
Background and Problem Statement
In 2018, a laundry operation was started in Elizabeth City, NC to wash the sheets and towels that are included in each rental. Pack out bags, which are customized quantities of clean sheets and towels, are distributed to each property every week. Properties may have anywhere from 2 to 8 bags depending on the size of the property. Each bag typically contains a mix of sheet sets and towels such that the weight is no more than 40 lbs. Different towels included are bath towels, hand towels, bathmats, and washcloths. Contents of each bag are pre-determined by a sticker (address label size).
In May 2021, we deployed an online Laundry Ordering system created by a CSC Senior Designteam. As we have used it ‘in production’ we have identified several needs and enhancements to further streamline the process. We would like to make enhancements to our online system based on what we have learned post deployment. Additionally, after gaining understanding of the process and systems, we would like to hear proposals on other technologies to improve efficiency and effectiveness of our processes.
Project Description
A few (but not all) of the enhancements we would like to see built into the system are:
- Creating an ‘Arrival Amenities’ pack out sticker that calculates the number of soaps, makeup wipes, toilet paper, kitchen sets, etc. based on the bedding information in the system. Generate a report showing total materials consumed in that order for re-ordering purposes.
- Upgrading the calculation for pack out weight limits to allow a range before creating a new bag
- Ability to add customer options (e.g., Early Check In) on the pack out stickers on a per order per property basis.
- Data quality checks: For example, Bath Towels and Washcloths. If one is increased, the other should auto increase (i.e., we should only enter one number for both)
- Ability to group/sort properties by cleaner on printed sticker sheets
- Creating an audit sheet and have the system randomly pick properties in the order for the receiving location to audit the pack out for quality assurance.
We also are looking for possible solutions to different print media (away from paper address labels).
In addition, we are interested in hearing about other technologies that are available that could further our capabilities (barcoding, RFID, etc.). We believe the project team would be able to provide proposals or options based on their previous course work or work experiences.
If possible, we would like to have the students on the team down for a long weekend (or longer) to stay at one of our properties and observe the processes that utilize this system.
Technologies and Other Constraints
- Work with our Technology Provider to use the existing online system to implement the requested enhancements.
- There is documentation on the technologies/programs the previous team used to create the system.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
ICON provides innovative drug development solutions across all phases and therapeutic areas. ICON Cybersecurity Team is a small group of professionals that share a passion for the topic. Our team is excited to cooperate with NCSU students on the fifth project to further develop the RePlay Honeypots.
Background and Problem Statement
Honeypots are systems that behave like production systems but have less attack surface, less resource requirements, and are designed to capture information about how potential attackers interact with them. Their intent is to trick an adversary with network access to believe that they are a real system with potentially valuable information on it. The honeypot will log the attacker’s behavior to collect valuable information about the adversary and to enable defenders to detect the threat and gain an advantage against it.
Previous Senior Design teams have developed Replay Honeypots--a low-interaction production honeypot system that can be configured and deployed easily, remaining cost effective in large numbers. The system is architected around three main components: 1) a central management system that provides a way to monitor and control honeypots and serves as a central repository of data collected by each honeypot it controls; 2) a series of lightweight, secured honeypots that support various methods of deployment and will simulate network behavior of other systems; 3) a configuration generation tool that will ingest packet capture (PCAP) and Nmap scan outputs, and generates configuration files that honeypots use to determine how they should behave. The Project has recently been released as an Open Source Project on GitHub, and the team will actively contribute.
While this system has come a long way, there are still some areas for improvement:
- The current implementation has a logging capability that logs honeypot interactions to the management console. If these logs are forwarded to a SIEM it would provide the ability to correlate these interactions with other actions across the network.
- The current implementation of the honeypots gets a request, checks it against the request in the configuration, and determines if it passes the similarity threshold. If it does, the honeypot then responds with a predetermined byte sequence from the config. However, some packets might contain information such as timestamps or random values that would give the honeypot away on closer inspection. In order to appear authentic, the honeypots should generate these parts of the response payload instead of using a stored value.
Project Description
For this project, we would like the following enhancements to be implemented.
Central Management System
Here is where users create, view/monitor, and modify honeypot configurations. In Phase 5 the following features are requested:
Device Management / Monitoring:
- Syslog Integration: The system shall have the capability to integrate its generated logs with Syslog.
Honeypots
The initial configuration of a honeypot is based on an Nmap scan of another system that the honeypot must attempt to replicate. With this input, the honeypot configures its simulated services so that an Nmap scan to the honeypot produces no detectable differences from the original system, while having as few attack surfaces as possible. In Phase 5 we would like to make our honeypots more believable as follows:
- The system shall have the ability to use a conventional device fingerprint to completely copy the network/interface of a target.
- The system shall provide the ability to use the captured data to modify the way the device builds packets, calculate fields in headers, and respond to specific traffic.
- When a honeypot responds to interactions, the timestamp portions of the payload should be generated dynamically rather than from a predetermined
- When performing an Nmap scan of a deployed honeypot, the lag time for receiving scan results should be roughly equivalent to the actual system from which the configurations were derived.
- Currently when running an Nmap scan against services “running” on the honeypot, it takes quite a bit more time than a real system would. This issue has not been identified yet.
- The system shall provide the ability to deploy a honeytoken server
- The system should have a wide variety of honeytokens but at a minimum should include the ability to use email addresses, Word documents, PDF documents and API keys.
- The new functionality shall integrate with current Replay functionality.
- The system may use canarytokens as a basis.
Config Generation Tool
The Config Generation Tool is a standalone tool that will ingest packet capture of a system that has undergone a Nmap scan and the respective scan results and generate a configuration file for the Honeypots that can be imported. In Phase 5 the following features are requested:
- The system shall provide the ability to mimic operating systems and networking equipment using the newly requested fingerprint functionality.
- The system shall be resilient to handling large configurations.
- The previous team ran into an issue with adding large configs through the frontend interface. If a config becomes too large, the server will reject it and the user will not be able to add/edit it.
Technologies and Other Constraints
Python3, NodeJS and VueJS are preferred development languages, and the TRIO library is recommended for multi-threading. Docker is currently used to easily manage and deploy honeypots and will remain the preferred solution for this phase. Nevertheless, all functionality of the Honeypot itself needs to be supported and tested on Linux without Dockers. CouchDB is the currently supported Database. Technology pivots are possible but require discussion with the Sponsors.
Each component of the system will be designed with large scale deployments (>100) in mind. Students should use best practices for the development of secure software and document in great detail. Students should also strive to design honeypots to be modular so that additional protocols can be introduced, and additional functionality can be created, e.g. RDP, SSH, SMB Honeypots, Honey Websites and active beaconing. This Project is published on GitHub and the Students will be required to follow GitHub processes and best practices.
Students working on this project will be most successful if they have a strong understanding of network principles such as the OSI Model. Prior successful participation in “CSC 405 – Computer Security” and “CSC 474 – Network Security” is recommended for this project. Previous experience with Nmap and OS configuration is an advantage.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
SAS provides technology that is used around the world to transform data into intelligence. A key component of SAS technology is providing access to good, clean, curated data. The SAS Data Management business unit is responsible for helping users create standard, repeatable methods for integrating, improving, and enriching data. This Senior Design project is being sponsored by the SAS Data Management business unit in order to help users better leverage their data assets.
Background and Problem Statement
With the increased importance of big data, companies are storing or pointing to increasingly more data in their systems. A lot of that data goes unused because a lot of the data is unknown. A data curator can manually inspect a small number of datasets to identify the content, such as travel information or sales records. However, manual classification becomes difficult data as data sizes grow. Storage facilities for big data systems are often called data lakes. As data sizes grow, data lakes frequently become data swamps, where vast amounts of unknown, potentially interesting datasets remain untapped and unused.
Imagine if you could tap into people’s knowledge to help with data curation; to classify, vet, and validate data stored in a system. Doing this sort of curation is hard work though, so why would people bother to do it without some sort of reward to encourage them to participate?
Could you make this process more fun by adding gamification? Similar to websites such as https://genius.com/Genius-how-genius-works-annotated , people that participate in classifying and curating data could earn genius points, gain levels, and earn the recognition of their peers for contributing to the overall knowledge base of data. Your application would serve as a data catalog with pointers to many datasets that could be interesting and useful to people, and that has been curated by knowledgeable end users.
Project Description
Design a web application for curating an index of data assets. Provide useful and interesting ways to encourage users to classify and document the data: is it fit to purpose, what does it contain, how clean or dirty is it, etc. Encourage these users to participate by providing fun and interesting challenges that keep them coming back to do more curation.
Some things to think about:
- Should you provide templates or standards to ensure consistency in how curators respond?
- How can you encourage people to contribute more than once? More than 5 times, 10 times, etc.
- How can you socialize the contributions so that people feel good about what they have done? Gain recognition from peers?
- How can you prevent spammers or non-constructive content from entering into the socially curated catalog?
There is some previous project work that can be leveraged for this project:
- This project has a UI design available, including UX research, from SPRING 2021 - CSC 454 - Human-Computer Interaction - DataGenius: Gamification of Data Curation. You may use this UI design as part of your implementation. The results from the UX research study conducted by that team may prove especially helpful. If needed, SAS can provide a package that includes all of the artifacts from the class. There are some of the important screenshots from this project included below in the references section as well.
- You may wish to leverage the indexing application work from Senior Design Spring 2021 Class DIWA: Data Indexing Web Application. The students in that project built an application that will index metadata about a datasest. This API would be useful for this project because it has the database and code to read in a dataset and create metadata about it in a database. You could use this code and backend database to store your datasets that are to be curated, as well as the datasets that have already been curated, which will give you a jump start on that piece of this project. It likely will need to be extended to handle the status of whether or not something has been curated.
You may also want to review and evaluate other applications that do this sort of thing socialization of knowledge for ideas such as genious.com (mentioned above), wikipedia, kaggle, google dataset search, and others you may think of. There are some links below that describe the social science around gamification that you also may find helpful and interesting as you build this project.
This project has the following objectives:
- Create a web application for curating an index of data assets
- Create a User Interface that leverages gamification principles to encourage users to curate the data referenced in the index
- Provide useful and interesting ways to encourage users to classify and document the data
- Provide a data connector to be able to add new csv files into the index into a queue for curation. As part of this you will want to visualize the queue of things that are to be curated, and also show all the data that has already been curated to users of your application. This is part of the project, to make these aspects of your application fun and compelling to encourage users to do this curation.
- Optional: Test your application with various users to gauge how well your application encourages participation in the data curation task
- Optional: can you run your curation application on a tablet or smartphone? Users might want to curate a few datasets while they have a few minutes; if it’s a gamified application, they might be encouraged to do this sort of thing more frequently.
Technologies and Other Constraints
- React frontend
- Python
- Storage - any preferred storage that the students can work with
- The data format of the input data to be curated can be assumed to be structured/tabular data (rows and columns), such as datasets in csv format (or like excel files).
- You can leverage other senior project work for additional technology suggestions
You will gain some knowledge from this project of machine learning principles. Some background in this area might be helpful, but not required to be successful with this project. Knowledge of Python and REST interfaces will be helpful. You may want to contribute your design into the open-source community. You should have some knowledge of Javascript and will be learning React.
Reference info, Data Sources, other examples, etc.
- https://genius.com/Genius-how-genius-works-annotated
- https://dataskeptic.com/blog/episodes/2020/crowdsourced-expertise
- https://arxiv.org/abs/2006.08108 Expertise and Dynamics within Crowdsourced Musical Knowledge Curation: A Case Study of the Genius Platform.
- Data sources: https://www.analyticsvidhya.com/blog/2016/11/25-websites-to-find-datasets-for-data-science-projects/
- Learning React: https://reactjs.org/community/courses.html
- Here are some screenshots of the gamification UI design project SPRING 2021 - CSC 454 that you can use as a reference and can help you get started on the gamification application. SAS can supply all of the artifacts from this class project if you need them.
Here is the main screen showing the user leader board
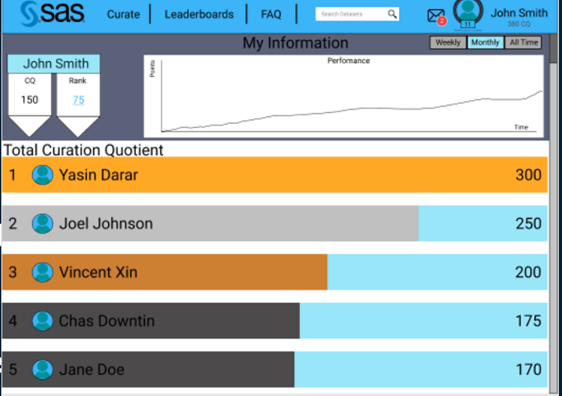
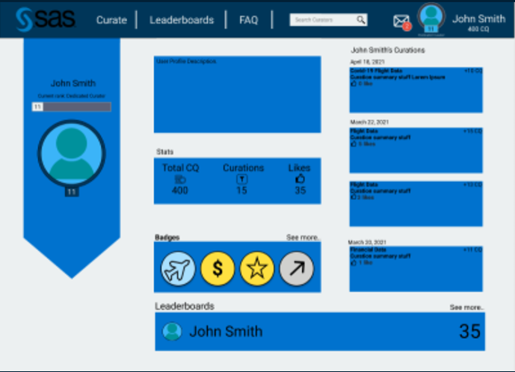
Users can drill in to see how many datasets they have curated, what their progress is, badges they have earned, and how the compare to others. This should encourage them to continue to participate in curation.
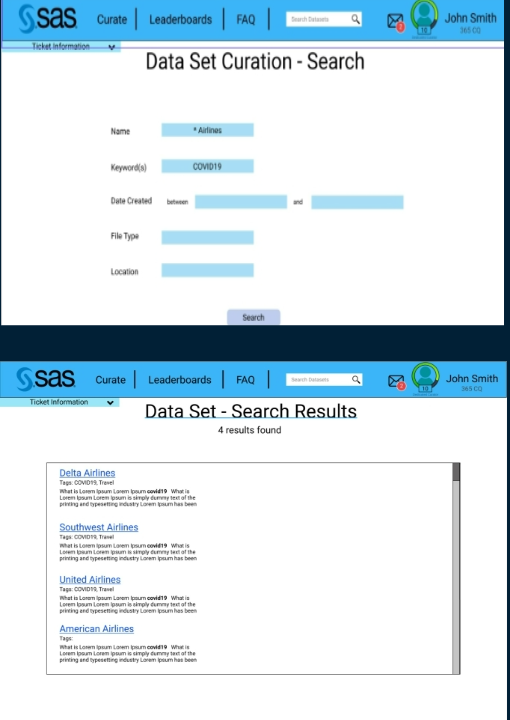
The job board is a way to visualize the queue; what datasets are ready to be taken for curation, anything that is actively being worked on, and things that have already been completed in recent history.

Users might also want to search the curation database to see what has been curated, and what may be ready to be taken. Below are some example search screenshots.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
This project will work specifically with the security division within Bank of America. This division is responsible for a wide range of security including, but not limited to, application security, intrusion detection, insider threat and cyber crime protection.
Background and Problem Statement
Sites such as GitHub and SourceForge can be used to host malicious code (e.g., planned phishing attacks) or non-malicious but non-approved code (e.g., code posted by an employee without proper approval). We would like to design an approach that can perform a generic search in an efficient manner.
Project Description
We learned from a previous approach that there are limitations to querying, for example, GitHub. We would like to extend upon what we have previously learned to create a more generic and more efficient approach. Specifically, we’d like to:
- Investigate a spidering approach to searching code repositories
- Develop a caching approach – e.g., crawl all of GitHub upon the initial query, but then save the relevant information in a back-end database so that subsequent queries only crawl the updates
- Investigate Google’s BigQuery as an alternative approach that has already been developed; also look at GHTorrent and Boa
- Develop an approach that is as agnostic as possible to the source repository (e.g., works on both GitHub and SourceForge at a minimum)
- Develop an approach that can search on any provided text (regex) or image
- Provide a front-end that allows a user to specify their search criteria, provides a progress indicator for crawling the source repository (including time estimates), and provides the results in an easy to consume fashion
- Stretch goal: Instead of regex, look at heuristics for identifying (e.g., BofA)
- Stretch goal: Provide user accounts and require authentication
Technologies and Other Constraints
Recommended technologies:
- Django REST framework in the backend (lean on the libraries available for faster / easier development)
- PostgreSQL (Postgres)
- Jenga REST and OAuth for backend authentication
- Git library for Python
- OpenCV for images
- Assumption: Using a server-client model with a web interface into the database backend
Requirement: Do not use code that is licensed under GPL as that means that any further code developed must be released as open source.
(Possibly) Useful References
- https://www.ndss-symposium.org/wp-content/uploads/2019/02/ndss2019_04B-3_Meli_paper.pdf
- https://ghtorrent.org
- http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.295.7985&rep=rep1&type=pdf
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Cisco (NASDAQ: CSCO) is the worldwide leader in technology that powers the Internet.
Our purpose -To power an inclusive future for all.
Our mission- To inspire new possibilities for our customers by reimagining their applications, securing their data, transforming their infrastructure, and empowering their teams.
Our commitment-To drive the most trusted customer experience in the industry with our extraordinary people and great technologies.
CX Cloud, a brand-new platform for customer and partner technology lifecycle experiences. CX Cloud aligns Cisco technology solutions to customer needs. Currently, the CX Cloud platform performs network optimization with AI (Artificial Intelligence) based actionable insights, provides deployment best practices guidance, and maintains asset visibility. New tools, features, and functions can be introduced to customers through CX Cloud with minimum disruption to production environments.
Background and Problem Statement
“Virtual teams are like face-to-face teams on steroids – they are more cumbersome and provide more opportunities for team members to lose touch, become demotivated and feel isolated,” Brad Kirkman (Poole College) says. Dr. Kirkman spent time partnering with three companies – Cisco, Alcoa, and Sabre – to examine their virtual team operations and came away with three best practice areas virtual teams should focus on – leadership, structures, and communication.
Leadership - How a team is designed – which includes everything from who is included on the team, what their roles are, and which technologies and performance metrics are used. The practice of empowerment and shared leadership by allowing team members to take on some of the leadership responsibilities as they would typically oversee in a face-to-face setting – such as rotating team members’ responsibility for sending out the agenda, facilitating a meeting or taking notes in virtual meeting spaces.
Structures - Improving structures the team has in place to support healthy team processes – including coordination, collaboration, conflict management and decision making. Having a shared vision and language, and leaders who are regularly checking in on team members, is especially important for a diverse team
Communication – What happens before, at the start of, at the end of and in-between meetings is most critical. Dr. Kirkman says. “I recommend leaders always take the first five minutes of any meeting for small talk – allow the team to chat, celebrate personal accomplishments and news and build that camaraderie that comes with being a team.”
To support Dr. Kirkman’s research and to support wellness of employees engaged in virtual teamwork, new software tools may be designed and created to provide employees the ability to feel more connected, motivated, and engaged.
https://poole.ncsu.edu/thought-leadership/article/equipping-leaders-to-support-virtual-teams/
Project Description
Students may design and create a new software application to help measure employee’s self-reported wellness in key areas of leadership, structures, and communication to enhance collaboration, individual leader contributions, and communication to peers via personas.
Project design should include a method for user-centered data collection, polling intervals, and insight reporting that provides participating users' personas and their organizations to gain key insight areas for employee wellness and engagement.
Functional areas should allow participating users the ability to remain anonymous and combine their results with other participating users with trending and historical retrospectives to understand personal and team impact in key areas of leadership, structures, and communication.
Added areas that the solution may explore can include areas of self-reported user feedback through anonymized summary data for indicators of employee's needs, concerns, and priorities that leadership and management teams should use to improve meeting, team, and business goals.
Software solutions should create assessment indicators to support healthy team leadership, structures, and communications through standardized questions and measurement scale ((I.e. “I (was/was not) able to get my point across in my last meeting”, “I (love/loathe) tasks I need to complete from my last meeting”, “I felt (heard/unheard) in my last meeting”, “I felt that my last meeting was a great/good/poor/bad use of my time”, This meeting was “(productive/unproductive)”)).
Consider asking open ended questions in polls. (I.e., “I would keep doing ______”. “I would change ________”. “I value ____”, “I do not value _____” to gain deeper perspectives and aggregate results for consumption by users and leaders.
Technologies and Other Constraints
Software tools to aid employee’s wellness can be developed on any platform and should be accessible from web/mobile (to support use cases for hybrid work and team collaboration).
Students should create a storyboard detailing a business organization, personas, and example interactions with the created software tools to help employee’s wellness or outcomes. Student may solve for unidentified workplace issues/challenges and possible outcomes related to leadership, structures, and communication.
Constraints - No expected issues in development since users would be persona-based. No expected application dependencies as a stand-alone app.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Dr. Jennings and Ms. Marini are the scheduling officers for our department. They are responsible for collecting a list of classes that will be taught each semester, placing them on the calendar, and entering the resulting schedule into the NCSU MyPack system. This is a complex task that is done today using Google Forms, a set of spreadsheets, and a lot of cut-and-paste operations.
Background and Problem Statement
Our department typically offers more than 200 sections (lectures, labs) each semester, so there is a lot of data involved, and it's format is complex. Last year, a Senior Design team created a "version 1.0" of the Course Scheduling Utility as a web application backed by a database. The application supports loading initial data from CSV files, and then allows drag and drop actions to place sections onto a calendar. But this is only part of what is needed! The department scheduling officers must check the integrity of the schedule manually, which means ensuring that certain key courses are offered at different times (because they are often taken together), certain labs are placed in special lab rooms, and many other constraints. Validating a proposed schedule in this way takes hours, and it is easy to miss something.
Project Description
This semester, we are looking for a team that can pick up the existing "first draft" of the application and run with it. Note that this application must allow concurrent users to work on the schedule for a single semester. This is not a trivial requirement!
A key function that is needed is a customizable system of rules that the application will enforce automatically. The rules will encode constraints about which courses cannot be taught at the same time, which lab sections must be placed in specific (known) rooms, and more.
In addition, the application must be able to generate a final schedule report in a format similar to the one that MyPack uses. Ideally, the application could read a report generated by MyPack and produce a report of the differences, so that the scheduling officers can see if there are discrepancies between what they scheduled and what the University has done with those scheduling requests.
Finally, the application must be easily installable, so that the CSC IT staff can deploy the application at the end of the semester for use by the scheduling officers.
A successful application will provide a good user experience, reliable constraint (rule) checking to catch errors, and significant labor savings for the department.
Technologies and Other Constraints
The application must remain web-based. The team will work with the CSC IT staff on technology constraints. The current application is written in PHP using an ORM package to interface with a MySQL database.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
IBM is a leading cloud platform and cognitive solutions company. Restlessly reinventing since 1911, we are the largest technology and consulting employer in the world, with more than 350,000 employees serving clients in 170 countries. With Watson, the AI platform for business, powered by data, we are building industry-based solutions to real-world problems. For more than seven decades, IBM Research has defined the future of information technology with more than 3,000 researchers in 12 labs located across six continents.
Background and Problem Statement
Telescopic follow-up of transient astronomical events is one of the most desirable and scientifically useful activities in modern observational astronomy. From a scientific perspective, pinpointing a transient event can be essential for discovering more about the source, either by directing more powerful telescopes to observe, or to maintain a near continuous record of observations as the transient evolves. Very often transients are poorly localized on the sky and telescopes have a limited field of view thus pin-pointing the transient source is often a daunting task. Perhaps most importantly, the number of large telescopes on the planet is small, and they cannot be commandeered to randomly search for every transient of interest.
http://ccode.ibm-asset.com/cas/centers/chicago/projects/research/ctn/
Project Description
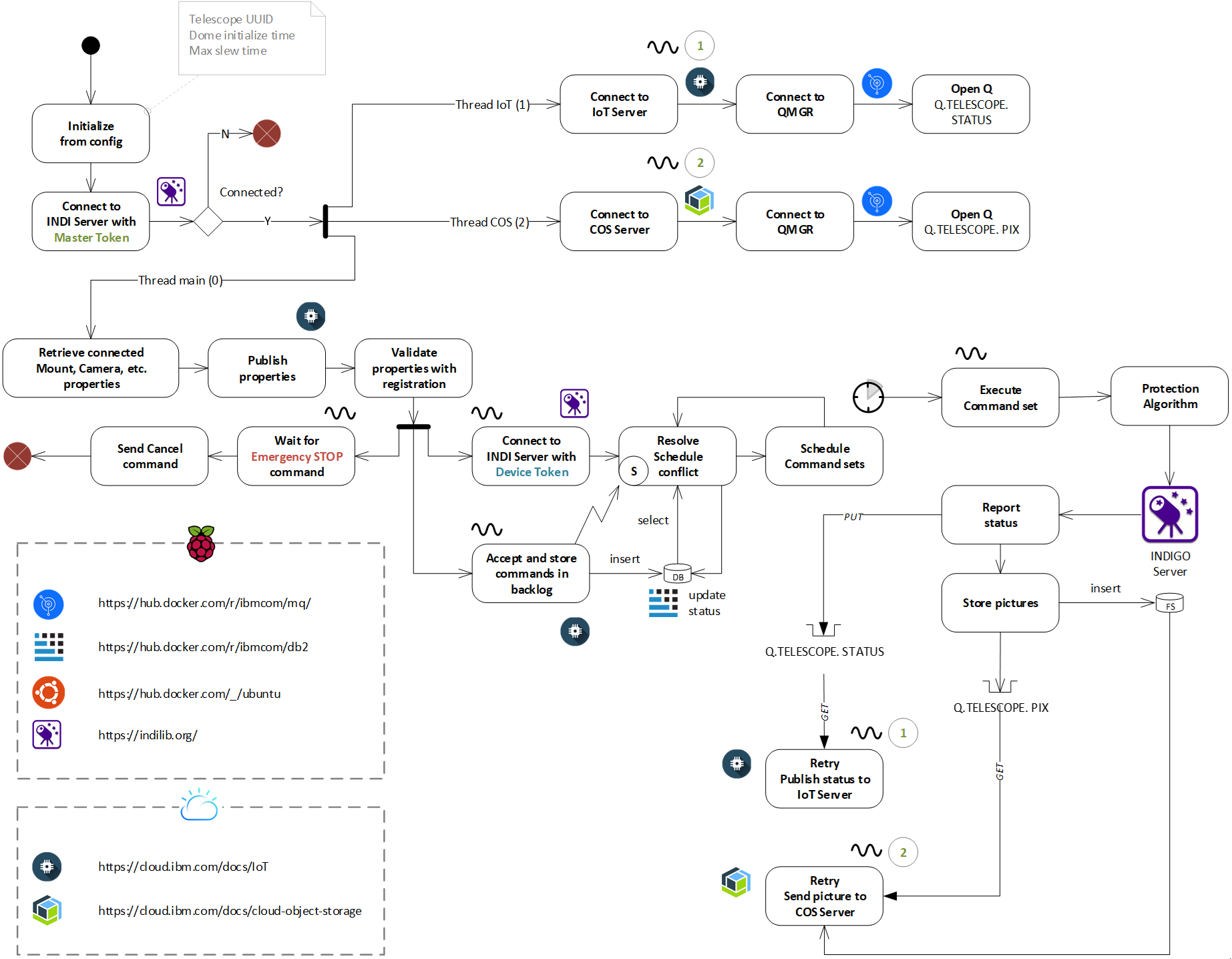
The Telescope Device Controller is a component that would be local to the telescope and may be run on a laptop or on a Raspberry Pi to communicate with the IBM Cloud to the Telescope Commander component through Watson IoT Platform. The software will be developed in Java 16 and run in a Docker container. The software would consider the complexity of poor network connectivity and will incorporate a scheduler, a queuing mechanism using IBM MQ on Docker and storing information and commands in the IBM DB2 database on Docker. The images taken by the telescope will be stored and forwarded to IBM Cloud Object Storage (COB). If there are connectivity issues, a separate thread will store the images when connectivity is resumed. The application will be communicating with the Indigo Server locally in simulation mode. The complete solution must be packaged and deployed to the IBM Cloud OpenShift instance allocated for the project using the Tekton pipeline in a single Pod.
Technologies and Other Constraints
Java, Watson IoT, IBM MQ, IBM DB2, Docker, RedHat OpenShift on IBM Cloud, Tekton
All software developed will be released as Open Source under MIT license.
Students must follow the high level design attached for the development of the code. Mentoring assistance will be provided by IBM as well as resources on the IBM Cloud to work on the project.
Sponsor Background
IBM is a leading cloud platform and cognitive solutions company. Restlessly reinventing since 1911, we are the largest technology and consulting employer in the world, with more than 350,000 employees serving clients in 170 countries. With Watson, the AI platform for business, powered by data, we are building industry-based solutions to real-world problems. For more than seven decades, IBM Research has defined the future of information technology with more than 3,000 researchers in 12 labs located across six continents.
NCSU College of Veterinary Medicine (CVM) is dedicated to advancing animal and human health from the cellular level through entire ecosystems.
Background and Problem Statement
Background: Infectious diseases (ID) and antimicrobial resistance (AMR) have emerged as one of the major global health problems of 21st century affecting animals, humans, and the environment. Around the clock, many researchers, institutions, national and international agencies are continually reporting the occurrence and dissemination of ID and AMR burden in "one health" perspective. In the scientific world there is plenty of data related to ID and AMR being generated.
It is important to analyze and study these data reports to address future emerging problems which threaten global health. This requires vast computing resources to analyze and interpret the data. In recent years, artificial intelligence (AI), which uses machine learning and deep learning algorithms, has been effective in digesting these "big data" sets to give insight on AMR and ID.
Project Description
We propose to work on an AMR expert system based on NLU/NLP. The expert system integrates data from databases and publications into a knowledge graph, which can be queried to retrieve known facts and to generate novel insights. This tool uses advanced AI, allowing users to make specific queries to the collections of papers and extract critical AMR knowledge – including embedded text, tables, and figures.
Examples of the types of queries:
- Which anti-microbial drugs have been used so far and what are the outcomes?
- Identify new, reported risk-factors
- Ranked antimicrobial drugs that are mentioned in AMR related articles.
- Ranked bacteria that are mentioned in the AMR related articles.
Currently, we have an initial pipeline of an AMR expert system with data related to approximately 400 papers. It includes a basic domain specific language model and NLU engine to return articles and knowledge across the articles. We would like to enhance the expert system with advances in the domain specific natural language model, innovative training method, and data visualization for knowledge graph queries.
In phase 2 we plan to address the following item and skill focus area.
- Enhance domain specific NLU Model – Assisted by Dr. Keelara who helped to build initial model
- Innovative iterative training of AI model – IBM Watson + open-source tool
- Visualization for knowledge graph queries – IBM Watson for backend and Open-source tool for front end visualization
- Data ingestion -- open-source tool to do data scraping, Watson tool to extract tables, figures etc.
- End-to-end pipeline of AMR phase 2 expert system.
Skills: NLU/NLP, Data Visualization, Cloud AI tools, Cloud devops. Front end interface design
Technologies and Other Constraints
GitHub (preferred)
IBM Watson Discovery Service (required), IBM mentors will provide education related to this service
NLP Machine Learning
Web front end (initial pipeline includes React, but flexible)
Cloud Services for AI and Devops
Sponsor Background
Siemens Healthineers develops innovations that support better patient outcomes with greater efficiencies, giving providers the confidence they need to meet the clinical, operational and financial challenges of a changing healthcare landscape. As a global leader in medical imaging, laboratory diagnostics, and healthcare information technology, we have a keen understanding of the entire patient care continuum—from prevention and early detection to diagnosis and treatment.
Our service engineers perform planned and unplanned maintenance on our imaging and diagnostic machines at hospitals and other facilities around the world. Frequently, the engineers order replacement parts. The job of the Managed Logistics department is to make the process of sending these parts to the engineer as efficient as possible. We help to deliver confidence by getting the right part to the right place at the right time.
Background and Problem Statement
In order to keep our logistics operation running as smoothly as possible, the Operational Intelligence (OI) team automates tasks, develops user-friendly software, and gathers as much relevant data as possible for all parts of the supply chain. Over time, the team has collected a wide variety of data sets and is receiving inquiries about the data from both inside and outside the department. While the OI team can provide data analysis, the number of requests is growing. In some cases, the most efficient solution is to give the requestor the data and let them analyze it themselves. The big problem with this, a problem we’re asking you to solve, is that figuring out how to use the data is too complicated for most of our users. In recent semesters our senior design teams have created a user-friendly tool that can help our users dive into the relevant tables and fields.
Project Description
T Our primary goal for this semester is to have a sustainable solution for deployment. Sub-goals include developing an authentication system and a dependency management system or policy. Beyond these goals, if time permits, we are interested in improvements to usability – we want our users to have a comfortable and intuitive experience navigating the tool.
Technologies and Other Constraints
This project is a continuation from previous semesters and c Some experience with JavaScript and Python will be helpful. Our goal is to deploy the solution on an Ubuntu 18.04 server.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Katabasis is a non-profit organization that specializes in developing educational software for children ages 8-15. Our mission is to facilitate learning, inspire curiosity, and catalyze growth in every member of our community by building a digital learning ecosystem that adapts to the individual, fosters collaboration, and cultivates a mindset of growth and reflection.
Background and Problem Statement
Rural youth face a series of barriers from entering the computing job market. Aside from living in regions with limited technology infrastructure, rural schools are not as likely to have advanced computing courses and rural areas tend to be slow to adopt disruptive ideas and technologies. For computing to be more widely adopted by these groups, materials need to be created that are culturally meaningful and demonstrate how computing will impact their future.
Project Description
We are seeking to develop a game-based learning environment that teaches children core computer science principles in a simulation themed around the future of farming. By selecting this setting, we aim to increase the appeal of computer science to rural and low income populations who are underrepresented in computer science fields. We envision the game having players programming autonomous vehicles that fulfill various tasks on a farm. These Unmanned Agricultural Vehicles (UAVs) have modular attachments that upgrade the UAVs to complete more complex tasks via programming logic. We envision the best way of accomplishing this is by the development of a new block-based programming system (similar to Scratch), but specifically tailored not only to the mechanical, but also the thematic needs of this product. That being said, we would be eager to hear any innovative ideas the team might have for incorporating a pre-existing block based programming language, or other alternative means of reinforcing and integrating computer science concepts through gameplay. Through the customization of their mechanical components, and differing complexity of the tasks asked of them, this game will demonstrate core programming logic principles such as: Variables & Constants, Conditionals, Looping, Data Structures, and Sorting. As such, these are the principles that the gameplay mechanics, be it the block-based programming or otherwise, should focus on showcasing.
A key part of this project will be creating software that can effectively tackle the computer science education, agricultural education, and fun and engaging gameplay elements that are the three cores of the project. We will be providing guidelines for what educational content we want to see. For computer science, we will want to tackle several basic principles such as Variables & Constants, Conditionals, and Looping. We would really like to see our team offer their own take on how to tackle these computer science topics with which they will be intimately familiar. We will be providing detailed materials related to agricultural content to explain the target lessons and teachings we would like to see included.
As far as gameplay, we envision the team building a game which integrates learning concepts in spatial reasoning, computer science, and agriculture. The player will program autonomous vehicles to maximize farm production while reducing synthetic inputs; for instance, in programming a drone’s optimal route to harvest/water/attend to a field of crops. Gameplay will emphasize real world farming objectives, such as planting crops, controlling weeds and pests, managing soil health and nutrients, and harvesting produce. Their farm will be assessed by factors such as produce yields, input costs, aesthetic appeal, and carbon sequestration. As inspiration, we would suggest looking at other instances of “programming games” that teach core concepts well while effectively encapsulating them into an entertaining game experience: Human Resource Machine (https://tomorrowcorporation.com/humanresourcemachine), while True: learn() (https://store.steampowered.com/app/619150/while_True_learn/). Furthermore, think about what traditional game principles might apply effectively to programming or agricultural education, such as resource management, optimization/efficiency, Non-player Character(NPC) AI behaviours, quest completion/prerequisites, etc.
While the game is intended to primarily serve populations that are underrepresented in technology fields, it is designed to broadly appeal to children ages 8 to 15 by incorporating concepts from multiple academic and artistic disciplines. By catering to these diverse interests, children will be able to grasp new or challenging concepts by connecting the material with their individual affinities and experiences.
In the development of this game, we want our team to be very conscious of all of the stakeholders at play and take all of their needs into account. These include, but are not limited to: the children playing the game, the educators utilizing the game, the researchers hoping to collect data from the game, our company developing the game, your “managers” (teachers) looking to measure your performance, etc.
In addition to developing the game, the team will be expected to test not only the functionality of the software, but also its effectiveness at meeting the various goals, including mastery of content, engagement/enjoyment, and replayability. We will want the team to design and implement a user experience testing session that they will then conduct on a group of middle school aged students. We will arrange for our team to have access to these students at around the midway point of the semester, and handle all of the scheduling and permission logistics that entails. However, we expect the team to be the ones to both design and conduct the sessions. Feedback from these sessions will be used to determine improvements and changes to be made throughout the latter portion of the Senior Design Team’s development, in the second half of the semester.
Technologies and Other Constraints
For the choice of game engine, we would recommend looking at options such as Unity, Unreal, or Godot. That being said, we are flexible about this choice, particularly if the team has existing experience or preference for another option, though we would like to hear the team’s reasoning as to why a certain engine is a good fit for this project. As we will be further developing the project afterwards, we would also like the team to think about how easy/difficult future development would be in the chosen engine.
Other technical constraints include the ability to run the game on computers with low-mid tier specs, and ideally, a web version that does not require high speed internet access. This is essential to ensure the game is accessible to the communities we are targeting.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
Katabasis is a non-profit organization that specializes in developing educational software for children ages 8-15. Our mission is to facilitate learning, inspire curiosity, and catalyze growth in every member of our community by building a digital learning ecosystem that adapts to the individual, fosters collaboration, and cultivates a mindset of growth and reflection.
Background and Problem Statement
Katabasis works to serve children in underprivileged communities across eastern NC. One of the central ways we do this is by conducting summer camps and after school programs where kids learn about computers and get hands-on experience building their very own computer with refurbished components we provide for them. This is a significant logistical undertaking, involving coordinating with many different county leaders and organizations, finding and organizing many computer components, and planning out individual camp sessions, tailored to the needs of the different locations. To streamline this process, we wish to have a system developed to aid in coordinating these efforts, and get more computers out into the community. Over the long term, we hope to have this system coordinate camps between community stakeholders without the need for significant involvement on the part of Katabasis. We aim to empower community organizations with the resources they need to run these camps on their own without needing to wait on Katabasis for permission or guidance.
Project Description
Katabasis is seeking a system to coordinate its activities and resources with those of our local partners across North Carolina. This system would be primarily used by Katabasis initially, but ideally we would like others within our network to have access to it in different capacities in the future, so we would like for the team to develop the system flexibly relative to this notion.
We envision a system that coordinates 3 broad considerations: computer components, local partners, and camp scheduling.
- Camp Resources: This system will be the principal means of tracking the various partners (individuals and organizations) aiding in the execution of these camps and the resources they can provide to allow for the successful implementation of one or more camps.
- Camp Facilities: To track what facilities are available to host camps, we desire the system to include a database that captures key attributes of the location. Such attributes include the address, number of campers they can support, date ranges when the facility can be available, notice time to reserve the facility, and facility point of contact.
- Camp Participants: In order to reach the kids that will benefit most from these camps, the system needs to catalog community organizations and the number of kids they serve of the target age range, kids that have been suggested by community champions, and the town closest to these kids.
- Camp Staff: To ensure sufficient manpower is allocated to each camp, we desire the system to catalog information on persons that have expressed interest in participating in this mission. Important information to capture includes their name, methods of contact, previous camps they were involved with, and the locations they are willing to help at.
- Interests: For each partner (donors, community leaders, local nonprofits, etc.) we wish to capture what interest/cause is important to them, and the level of engagement they desire
Initially this system will be handled internally only, but we would like the system to allow Katabasis the flexibility to develop the system further and authorize different users to access and update information pertinent to them only.
- Computers & Components: To track the computers and peripheral components needed to assemble a desktop computer appropriate for home use, we envision the system incorporating an inventory system to track the status and quantity of our computer components. On top of the basic inventory system, the system should highlight compatibility concerns between components, suggest optimal pairing of components to maximize the number of computers that can be assembled, and suggest what partner organizations receive the computers based on their technology desires and time since previous camp.
- Scheduling & Logistics: We desire the system to incorporate a scheduling aid that optimizes camp dates and locations based on resources available. This will cross-reference data provided by the other 2 components of the system; scheduling a camp requires both assistance from partners and parts for the computer builds.
Due to the interwoven nature of many of these features, several of the requirements listed above will be corequisites of one another, and will require the team to be very conscious of their overlap, and plan their implementation accordingly. The scheduling portion in particular will present this challenge extensively; in order to schedule a camp, the system needs to cross-reference available components, a valid location, and nearby volunteers, at the very least.
Furthermore, in the development of this tool, we want our team to be very conscious of all of the stakeholders at play and take all of their needs into account. These include, but are not limited to: Katabasis’s need for a tool to coordinate the critical elements needed to run these camps, teachers’ desire to educate and empower students with limited resources, nonprofits supporting impoverished communities, community members looking to support their community, your “managers” (teachers) seeking to measure your performance, among others. While not all of these stakeholders may be users of the system, we do want the system to be designed in such a way that addresses all of these interests effectively. Of those who do access the system, individuals and organizations will only access specific aspects of the software and data contained.
Technologies and Other Constraints
For this web-based application, we would be eager to see what tools the team has experience with and what they think would be the best choice for this project. A suggestion is the MERN webstack, or a MEAN stack for those without React experience. You will have to explain and justify this choice to us, as we will likely be iterating and developing this tool further in the future.
Students will be required to sign over IP to sponsors when the team is formed
Sponsor Background
NetApp is a cloud-led, data-centric software company dedicated to helping businesses run smoother, smarter and faster. To help our customers and partners achieve their business objectives, we help to ensure they get the most out of their cloud experiences -- whether private, public, or hybrid. We provide the ability to discover, integrate, automate, optimize, protect, and secure data and applications. At a technology level, NetApp is the home of ONTAP (our custom storage focused operating system); cloud, hybrid and all-flash physical solutions; unique apps and technology platforms for cloud-native apps; and an application-driven infrastructure which allows customers to optimize workloads in the cloud for performance and cost.
From http://www.spec.org: “The Standard Performance Evaluation Corporation (SPEC) is a non-profit corporation formed to establish, maintain and endorse standardized benchmarks and tools to evaluate performance and energy efficiency for the newest generation of computing systems. SPEC develops benchmark suites and also reviews and publishes submitted results from our member organizations and other benchmark licensees.”
Background and Problem Statement
Real consumer storage workloads are complex and require tuned storage systems to optimize their performance. Unfortunately, it is generally problematic to gain access to production customer systems to dynamically tune them, or to develop new storage controller algorithms better suited to improving their performance. Therefore, both storage customers and vendors often turn to synthetic workload reproduction in the hopes that a workload “close enough” to the production workload can be created and used as a basis for understanding and improving performance. This requires not only a workload generator that can reproduce workloads, but which can also transition through workload attributes to emulate how the customer workload varies over time. The SPECstorage Solution 2020 benchmark supports both static and dynamically updated workloads, however there is no user-friendly way to modify and update dynamic workloads in real time and custom workload definitions are handled entirely through the use of yaml files and an expectation that these are directly edited in a text editor. A user interface is required which will allow users to easily make modifications to workload definitions, see those changes dynamically applied to a running system, and monitor the benchmark’s performance as changes are made. This system can then be used by consumers as well as storage vendors to study and optimize the storage behavior of production workloads.
Project Description
As noted above, a user interface is required which will allow users to easily make modifications to workload definitions, see those changes dynamically applied to a running system, and monitor the benchmark’s performance as changes are made. The main deliverable of this project is this graphical user interface, which will interact with the existing SPECstorage Solution 2020 API.
The students will need to create a graphical interface that will:
- Permit the input of workload modifications in real time. There are several hundred workload attributes that are malleable. The solution needs to provide a user-friendly interface that enables modification of these attributes.
- Provide visualization of the storage system’s behavior (as perceived at the client level) including operation types, operation rates, and throughput values per process, per node, and system aggregate. Visualize latency information per process, per node, and aggregate for the solution under test.
- Enable the user to visually identify bottlenecks and any imbalances in the workloads.
- Detect and provide visual feedback to the user if the delivered performance is not conforming to the requested definition.
- The graphical interface should also support ease of use methods for input (such as sliders or knobs) that make modifications easy for the user and yet provide numerical data for visualization and consumption for analysis, capacity planning, vendor product engineering, conferences, and trade shows, by vendors or consumers.
- The input and visualization methods are intended to be used by consumers on conventional desktops, laptops, tablets, or even cell phones.
- Interface with the SPECstorage Solution 2020 API for dynamic workload manipulation and sampling.
- Archive results in a database for later use by capacity planning, POC labs, consumers, and potential AI ingestion, training, and inferencing.
- Provide visual replay of the statistics collected over the duration of the collection.
Stretch goals if resources are available:
- Develop a similar UI for initial workload definition and creation. Instead of applying this workload definition to a running system, this UI would result in output of a .yaml file used for later benchmark execution.
- Develop a UI to visualize the results of a completed benchmark. This would likely start by providing a visualization of the high level metrics (achieved operations/sec and latency at each load point), and then move to providing methods to dive deeper into the performance of individual op types. In addition, since, today, benchmark results are stored in simple text files and client-related performance information is spread out across many different files, it can be difficult to understand the relationship between individual clients (and client processes) and overall benchmark performance. It is hoped that students would develop an effective method to visualize these relationships – this could be as simple as displaying the data all together, or go beyond this to, for example, summarize similar data and highlight outliers.
- Implement a portable automated tool, or system of tools, that can collect all of the workload attributes from a running production environment for import into the SPECstorage Solution 2020 modeling definitions.
- Provide analytics on the attributes and the model’s characteristics and similarities to other workloads in the archive from above.
Technologies and Other Constraints
There is expected to be no NetApp-specific IP as part of this project. NetApp is a user of the SPECStorage 2020 benchmark, Don is both a NetApp employee and the chair of the SPEC Storage committee and Ken is NetApp’s primary SPEC technical representative. This work is in support of industry standards and supporting easier use of a vendor neutral benchmark in the storage industry.
It is expected that students will opensource their work or donate the work directly to SPEC. The solution should be based on widely available free technologies / platforms and should be designed to interface with both *nix and Microsoft Windows-based systems. Desktop, web-based and mobile solutions are all within scope, tbd by the design team. No explicit technology solution is defined/required.
Students will need to work with the SPECstorage Solution 2020 benchmark. The current cost for this benchmark is $500 for academic institutions, but the SPEC Storage committee has been informed of the potential project and has requested a free license to support the work.
Students will need to be able to generate a workload against a storage solution of some variety, however no significant load is needed. Initial work could proceed with a single virtual client (windows or linux based) and a virtual-based storage system (a system capable of handling NFS or SMB-based I/O) providing as little as a TB of storage. Later work will require a beefier configuration, but it is expected that if this isn’t available through NCSU, resources can be made available through iozone.org (which Don maintains).
Students will be offered opportunities to meet with the SPEC Storage committee to discuss the project and share their results, both interim and final. Active members of the committee include some individual contributors as well as representatives from NetApp, Pure, WekaIO, Dell EMC, IBM, nVidia, and Intel. The committee meets normally on alternating Tuesdays at 2 PM eastern. It is highly desired that students can take advantage of this opportunity.
Sponsor Background
At Sunder Networks, our focus is on building innovative solutions for legacy network problems. To that end, we are building out a network operating system that will allows us to rapidly develop these solutions or "Apps" and deploy them across disparate network hardware devices (build once, deploy everywhere). Sunder includes the libraries and tooling that will allow developers to not only build custom, innovative new network Apps, but we also plan to bring the full CI/CD (Continuous Integration / Continuous Delivery) software lifecycle model all the way down to the network hardware layer.
Historically, new network platform development spans years of development and testing. By building an operating system with APIs and a system for Closed Loop Verification we believe we can largely reduce development costs and open up the ecosystem to innovation from a much wider range of potential developers.
Background and Problem Statement
The emerging practices and capabilities of the SDN revolution (see Figure 1) have enabled an incredible opportunity for innovation within the networking ecosystem. Usually it takes a dedicated platform team and lab full of heterogeneous switching platforms to develop and test against before going to production with new network features or fixes. While unlimited resource hyper-scale companies (e.g., Google Network Infrastructure or Facebook Engineering Networking) are able to devote the type of resources required for this network workflow, the vast majority of enterprise customers do not have the network engineering resources to build and maintain their own network and tooling.

Figure 1: Software Defined Networking (SDN) milestones
In computer science and engineering, a test vector is a set of inputs provided to a system in order to test that system. Google and the Open Networking Foundation have created a framework for using test vectors to verify network behavior. Our plan is to build this framework into a fully automated CICD network pipeline and that’s where we need your help!
Project Description
Experience has shown that verification works best in settings where the overall system is constructed in a compositional (i.e., disaggregated) manner. Being able to reason about small pieces makes verification tractable, and the reasoning needed to stitch the components together into the composite system can also lead to insights. With disaggregation as the foundation, verifiability follows from (a) the ability to state intent, and (b) the ability to observe behavior at fine granularity and in real-time. Our network operating system, Sunder, provides this important disaggregation and also for the first time, reliable APIs at all levels of the stack to reliably observe network behavior.
Sunder
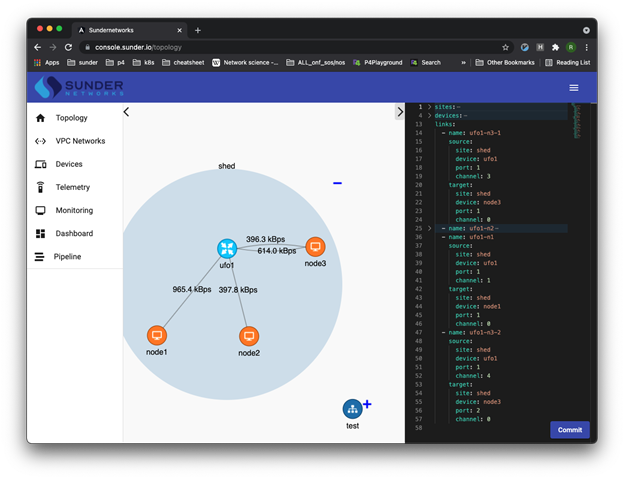
The detailed Software-Defined Networking architecture we are employing is best described in the link below, but generally speaking Sunder is an open-source based Network Operating System and Network Controller that runs on “whitebox” or commodity network hardware. We are calling the controller aspect of Sunder a “Cloud Network Controller” because we are able to manage any number of network devices via the same console and also because we are introducing several Cloud Networking features like “VPC Networks” and “Tenants” to traditional hardware networking.
https://sdn.systemsapproach.org/arch.html
Network verification is an exercise in continually building on known and reliable information. To reliably test a network it is necessary to first verify the most basic inputs and outputs before moving on to increasingly more complex test cases, similar to working your way up the OSI model. We need your team’s help designing the testing methodology and hierarchy, building out the test cases and test vectors, and also building the automation pipeline to execute these test vectors on both virtual and physical network switches to achieve fully automated, closed loop network verification.
In a well-designed testing methodology each test should build trust for the next test. For example, it is important to verify that your test tooling and interface outputs are consistent with each other and reliable before moving on to multi-device throughput testing.
The full network operating system and controller are still under development, but students will be able to use the fundamental building blocks in the form of a local test and development controller. This is a docker container which has the core functionality needed for testdev iterations. For example, each new test run requires setting the network forwarding pipeline indicated by the test suite and writing a set of entries specifying the packet matching needed to forward correctly.
Though we will discuss P4 code development, the students will be provided with fully functioning P4 programs as the starting point for their testing. Students will also be provided with a container-based virtual networking environment as well as the open-source “Test Vectors” code base (see link below) which provides both the structure for test cases and the runner for those cases. Additionally, in our lab we have multiple Wedge100BF-32X which are Tofino - based (P4 programmable pipeline silicon chips), 100Gig whitebox switches that we will ultimately be using to verify network functionality. Students will have access to our lab and hardware for their development and testing throughout the semester.
The formal definition of test vector can be found in the overview docs https://github.com/stratum/testvectors/blob/master/docs/testvectors_overview.md but we recommend you review the recording of the first testvector SDN testing approach here.
https://github.com/stratum/testvectors/blob/master/docs/images/test_vectors.png
{kind=link}
Each Test Vector Contains:
- test_case_id - Unique identifier for the test case in the Test Vector.
- Multiple Action Groups - Each action group is a set of actions that can be executed sequentially or in parallel or random order.
- Multiple Expectations - These are executed after all the actions are executed to verify expected system state.
Example: Simple Network Topology
Example: Test Vector
Test Layer 2 Reachability Between Two Hosts (host1 and host2)
- host1 sends arp request, broadcasted
- expect switch to replicate packet and send on all ports in broadcast domain
- do not expect ports outside of broadcast domain to receive (host3 in this case)
- query P4Runtime API confirms only pipeline objects related to this flow increment count. The pipeline students will be working with models of the layer2 domain aka broadcast domain using a BD object, this step and description is for describing that each test will have some p4 runtime state that is relevant but this will vary per test type. Layer 2 tests will generally involve broadcast domains “BDs” while Layer 3 tests might be concerned with VRFs.
- query gNMI API confirm only broadcast counters incremented during this stimulus, confirm counter directionality RX vs TX
- host2 sends arp reply, unicasted
- expect switch to only send to port of host1
- query P4Runtime API confirm counter : object type (BD/VRF) etc
- query gNMI API directionality RX/TX,
- host1 sends unicast flow/icmp
Technologies and Other Constraints
- P4 (p4.org) - (no prior experience required)
- Go (golang.org) - (suggested, not required)
- Kubernetes (k8s.io) - (suggested, not required)
- Docker (docker.io) - (required)
- Python (python.org) - (required)
- Communications Network Concepts (suggested)
- Network Security Concepts (suggested, not required)
- Network and Systems Testing Concepts (suggested, not required)
- CICD / DEVOPS / Automated Software Lifecycle Concepts (suggested)
Sponsor Background
Michael DeHaan is a NCSU & CSC492 grad who enjoys analog synthesizers and electronic music production. In software-land, he previously created Ansible (http://ansible.com) and several other IT / cloud / systems-management applications used by a relatively large number of companies worldwide. Michael also previously served as a technical consultant for CSC492 for several semesters.
Background and Problem Statement
This project is about teaching computers to understand how to compose awesome music that doesn’t sound like it was produced by computers.
Project Description
For starters, we probably want to teach computers to study existing music a bit, because the general “rules” for what makes music in a certain genre sound a certain way can be difficult to code explicitly. To do this, the internet has lots of freely available MIDI files that contain musical notes to various popular songs, video games, and classical works that we can download. MIDI files can be played back with your typical computer or web browser, but they sound a lot better when dropped into a Digital Audio Workstation like Garage Band or Ableton Live, or even hooked to hardware synthesizers (or tesla coils or floppy drives… see youtube, etc!)
By parsing these MIDI files and recording representations of music in a key-agnostic way (chord types and interval sequences, etc.), and coupling that with some expert-systems type logic about what sounds musically “normal” or “interesting,” we can theoretically produce other types of music in the same genre and create some completely new works based on our preferences.
Possible Example Goals
- Hello World: replay this song but in a different scale
- Take a melody that someone hand-wrote and add a bassline, chords, and percussion on separate tracks.
- Take the soundtrack to the Legend of Zelda and make it bluesy. Don’t just do a scale change, but incorporate some elements from blues songs.
- Produce a piece similar to Bach at 128 bpm in D locrian mode, but one that isn’t too derivative.
- Produce a piece that blends the styles of John Phillips Sousa and Takashi Tateishi, who wrote the music to Megaman 2, morphing about halfway through.
- Take these two separate melodic sections from two separate songs and create a bridge between them that seems to fit.
- Make a speed metal version of Mary Had A Little Lamb
- Explore what happened if Led Zeppelin had an Ice Cream Truck
- Feed in a short melody and have the computer finish the song
- Produce a 24 hour long song that gradually morphs between genres that never gets boring. Let someone input some parameters about what they want to get so things are tunable, and it sounds very different the next time it is run.
Invention of better or more exciting goals can largely be up to you :)
Research And Ideas
First and foremost, this should be a very creative project.
There’s a lot of opportunity for experimental research in this project and we’ll definitely be looking to see how far the team can take it. There is no getting done early though; it’s about how far you can go, and how things can continue to get better. (We should be able to actually hear your progress from one presentation to another!)
One thing that may be important is that if there’s an AI component; we want to know why it works and why what gets decided. Expert-systems level approaches, where the code itself gains more of an understanding of what the music theory behind a decision is, are perhaps more interesting than AI approaches where the code doesn’t exhibit that awareness. For instance, the code has to know about scales and intervals and chords, but it’s even better if it knows more about compositional techniques.
As an example of this, an intermediate program task might be “for this genre of music, these are the most common interval patterns and keys”, and “when this pattern occurs, the most likely things to play next might be these things” so on. Thus, the team for this project should be able to produce a relatively interesting report with some new musical conclusions! At first, simple techniques like Markov chains might come into play. To get things to be really good though, we’ll probably want to go farther. Detecting similarities between artists and genres may also be interesting, but being able to have the program say why they are different is even more so.
Technologies and Other Constraints
Tools
Language choice for this project is wide open, but your sponsor has some sample code in Python and Swift that may be useful as a pseudo code reference for generating scales and chords and so on that could be helpful. The Swift version is less buggy (because it does less), but could be easily translated back to Python.
Whatever language is chosen needs to be productive and have good libraries for reading and writing MIDI files. It’s not expected that this project has a user interface or a webapp. It’s up to the team, but it might also make sense to write some visualization tools along the way to help understand the program’s choices. Selecting an output song’s parameters could involve a simple command-line app that could evolve over time. The program probably could benefit from a database to store chunks of songs, but it doesn’t have to have one.
Skills
Musical interest and backgrounds from the team is fantastic, but extensive music theory knowledge or ability to play an instrument is not required. Music is fundamentally math, and scale generation is not too complex once we get started.
Sponsor Background

Autonomous vehicles technology is maturing and could offer an alternative to traditional transit systems like bus and rail. EcoPRT (economical Personal Rapid Transit) is an ultra-light-weight and low-cost transit system with autonomous vehicles that carry one or two passengers at a time. The system can have dedicated guideways or, alternatively, navigate on existing roadways where the vehicles are routed directly to their destination without stops. The advantages include:
- Dual mode – existing roadways and pathways can be used for low install cost in addition to elevated roadways at a lower infrastructure cost than existing transit solutions
- A smaller overall footprint and less impact on the surrounding environment so guideway can go almost anywhere.
The research endeavor, ecoPRT, is investigating the use of small, ultra-light-weight, automated vehicles as a low-cost, energy-efficient system for moving people around a city. To date, a full-sized prototype vehicle and associated test track have been built. For a demonstration project, we are aiming to run a fleet of 5 or more vehicles on a section of Centennial campus. The Vehicle Network server will serve as the centralized communications and vehicle routing solution for all the vehicles.
Background and Problem Statement
With the aim of running a multi-vehicle live pilot test on Centennial Campus, the overarching goal is to create a Vehicle Network Controller (VNC) and the associated Robot Operating System (ROS) vehicle client software to guide the vehicles and provide interaction to users. Please refer to the architectural diagram below showing the server architecture of the solution. The VNC will manage a fleet of cars, dispatching them as needed for ride requests and to recharge when necessary. It will also provide interaction to users to both make these requests and manage the network itself.
Project Description
The work on the VNC would be a continuation of the work from another senior design team from Spring 2021. The current VNC solution provides a means to simulate multiple vehicles, evaluate metrics of performance, create administrators/users, and allow for vehicle clients to interact with the server in different ways. Though still considered an alpha stage at this point, there is a need to further develop the VNC to make it ready to be used with physical vehicles.
The goals of the project involve further enhancing, improving, and testing the system as a whole, making the simulation more turn-key, and demonstrating the ability to interface with actual physical vehicles. Below is an exhaustive list of possible areas to explore. Initial meetings will be used to refine the scope of these goals.
- Develop a mobile app for people calling the vehicle
- Develop the client vehicle ROS package with a secure connection to interact with the VNC
- Include ability to monitor battery voltages
- Include charging stations
- Algorithms to re-route vehicles to charging stations when battery is low
- Algorithms to better improve vehicle assignment to requested ride
- Include vehicle storage depot in VPN to allow storage of excess vehicles
- For running multi-vehicle simulations, include improved usability of the GUI interface for server.
- Include top-level input parameters such as number of vehicles, number of passengers per hour, relative distribution of people at stations
- Include ability to draw paths with mouse and have them persist through sessions
- Ability to set the number of vehicles that can be parked at each station
- Further improve multi-vehicle simulations
- Make running simulations more turn-key
- Add physics within the emulated vehicle module
- Further refine KPI’s for success (i.e. dwell time, ride time)
- Further explore the vehicle routing algorithm

Technologies and Other Constraints
The ecoPRT system includes several components. The particular technologies used by the team will depend on what components and extensions are chosen as the focus for this semester’s project. The following table shows some technologies the team is likely to encounter.
|
Name |
Description / Role |
Version |
|
ROS |
Robot OS system for running on he autonomous vehicle |
Melodic |
|
NodeJS |
This will run on the web server and will serve the website and connect the website to the database. It will contain a REST API. The REST API will allow the website and other services to access the functions of the web application. |
8.9.4 |
|
Python |
Used to write the Vehicle Server and Vehicle Client processes |
3.4.9 |
|
MySQL |
Used to provide persistent storage on the server, for data that fits well in the relational model. |
14.14 |
|
Neo4j |
Graph database, used for storing graph-like data. Uses the Cypher query language. |
3.4.9 |
|
Bootstrap |
Using Bootstrap will give more freedom to customize the look and feel of the web application. It also makes it easier to make a mobile-friendly version of the website. |
4.0.0 |
|
AngularJS |
Used for the logic of the website. It works very well for data binding which is the bulk of the web application, since all data is pulled from the database. |
1.6.8 |
|
Express |
Routes URLs to files and/or functions |
4.16.2 |
|
HTML5 |
Used to create web pages |
5 |
|
REST |
Used to get information from the server and send it to the front end |
- |
|
Socket.io |
Used to get information from the server and send it to the front end |
2.0.4 |
|
CasperJS |
Used for automated testing of web applications with JavaScript |
1.1.0-beta4 |
|
Mocha |
JavaScript framework for Node.js that allows for Asynchronous testing |
5.0.5 |
|
Chai-HTTP |
Assertion library that runs on top of Mocha |
4.0.0 |
|
Istanbul (nyc) |
Used for determining code coverage |
11.7.1 |
Backward instructional design involves outlining learning objectives (“what should students know”), creating assessments aligned to the learning objectives to measure evidence of student achievement (“how will students demonstrate knowledge”), and planning instructional methods (“how will students gain the knowledge and skills to meet the learning outcomes”). Using backward design, instructors can more easily analyze student performance in courses for course improvement and accreditation efforts. However, other than raw grades, students rarely have an opportunity to review detailed data about their own performance in a course. Currently, few tools exist to facilitate analysis of student performance on learning objectives, and few tools exist to give students insight into their performance on learning objectives.
To help make adopting backward design more readily accessible to instructors, and to allow students to benefit from additional data and insight into their own performance in a course, the team will create a web application that allows instructors to:
- Create a set of learning objectives for each lecture topic in a course (for example, using Bloom’s taxonomy to define or categorize learning objectives)
- Add/Edit/Delete mappings of assignment questions to specific learning objectives (for example, Homework 1 Question 1 assesses learning objective 1A)
- Upload data with student grades on assignment questions (for example, exports of grade data from Moodle quizzes or Gradescope assignments)
- View statistics/charts of student performance against learning objectives (for example, displaying charts and displaying lists of the top 5 learning objectives with highest performance and top 5 lowest performance)
- Create PDF reports of student performance against learning objectives (for example, box-and-whisker plots for each topic or learning objective; references to relevant supplemental materials in textbooks or online, etc.)
Ultimately, the web application could help instructors more quickly identify students who need additional support, extra practice on specific topics, or other educational interventions to support student achievement and success.
Required Technologies
- Java
- Spring Boot
Sponsor Background
The Laboratory for Analytic Sciences (LAS) is a mission-oriented translational research lab focused on the development of new analytic technology and intelligence analysis tradecraft. Researchers, technologists, and operations personnel from across government, academia and industry work in collaboration to develop innovations which transform analysis workflows.
Background and Problem Statement
Machine learning is ubiquitous in today’s world of big data. To be reliable, machine learning requires iteration to learn from the data, and machine learning models of today to build more efficient and effective labeled data sets and models tomorrow. Different data labeling techniques, model strategies, and the effectiveness of their associated applications provide important insights that inform continued machine learning development. Tracking and managing each iteration, or version, for data and models is thus important to make one’s machine learning repeatable and robust.
Project Description
This project will build a repository for labeled data sets and machine learning models to track each data set iteration and model version. This project will also build an associated UI for access and discoverability. Enabling creation of data sets, labels, and models themselves is not a focus of the project, rather a system to track and manage such objects in an environment where training data sets can be updated, new labels can be supplied, and associated models may be generated dynamically. Using technologies suggested below (or similar) the team will build a web application with functional UI, REST API(s), a backend database to track versions and other associated metadata of data sets/labels/models, and a database to store the actual data sets/labels/models (could simply be an S3 bucket). Stretch goals include Dockerization of the project and including access controls for the app. LAS has existing machine learning data sets/labels/models that we will provide for development, testing and demonstrative purposes.
Technologies and Other Constraints
In most cases the team will be free to select appropriate technologies to fit the functional requirements of the application. Below we note several specific requirements, and offer some suggestions/recommendations for some components of the project.
- Database – No specific technology required, could be SQL-based (e.g. MariaDB, Postgres, MySQL)
- Backend – No specific technology required, preference for Python (Flask or Django), Node.js (Adonis), or PHP (Laravel)
- Frontend – Strong preference for React
- Dockerization of web app – preferred
Additional Note:
- Public distributions of research performed in conjunction with US Government (USG) persons or groups are subject to pre-publication review by the USG. As a result, we will require students to submit certain documents for pre-publication review during the semester. In the case of the LAS, this review process is performed with great expediency, is transparent to research partners, and is of almost no consequence to students (other than perhaps having to complete certain course assignments slightly in advance of the course deadline to allow time for the review process).
Sponsor Background
Merck's mission is to discover, develop and provide innovative products and services that save and improve lives around the world. Merck's Cyber Fusion center mission is to ensure that our products, people and patients are protected from any impact from a cyber situation.
Background and Problem Statement
Merck receives threats of several types, for example: natural disasters and weather events can threaten Merck’s properties; riots against large pharmaceutical companies and vaccines can cause damage to Merck’s reputation; Militant groups, cartels, and rioters all pose threats to Merck personnel and products. Other nation states or competing pharmaceutical companies may also pose a threat to Merck’s intellectual property.
This project is concerned with a particular type of threat. Most pharma organizations have seen a significant uptick of insider threat incidents. According to security experts, both in government and industry, employees, contractors and third parties continue to be one of the main anticipated threats to corporations, with the likelihood to cause as much damage as external threats.
Current behavioral and sentiment analysis outcomes are not yielding high-confidence behavioral patterns for intentional or unintentional threats posed by employees, contractors or third parties. These threats can relate to malicious Intellectual Property exfiltration, various financial gain, nation state benefit or other nefarious objectives. Some of the issues that we are facing are:
- Analytical models are based on statistical anomaly detection or unsupervised modeling (e.g. k-means clustering). Training these models is difficult because data from cyber criminals are limited.
- Training and test data are based on approximation & probabilities (i.e. based on simulations or assumptions)
- Looking at sentiment analysis and user behavioral analysis from a computer science perspective, rather than from a criminal & behavioral sciences perspective.
- Constant model decaying leading to high false positive rates. This is due to the fact that threat landscapes keep changing, and training data sets are very limited. Cyber criminals naturally hide their steps so data available for model training is very limited. Merck would like to look at innovative ways to create training sets (perhaps leveraging kinetic data from other criminal behavior).
Project Description
During the Spring 2020 semester, a previous Senior Design team worked on this problem using simulated Twitter data. This semester, we would like to start from this algorithm, analyze its effectiveness, recommend changes and enhancements, design and implement them, and finally apply them to simulated IM internal data.
The Spring 2020 team was able to accomplish the following:
- Full stack implementation with a login system.
- The existing system provides for bulk data uploads through CSV files. A user can input a raw text entry to the frontend and have it all processed for potential threats.
- At the heart of the system, the backend features an algorithm for detecting new threats based on the content of the text. This component uses VADER for Natural Language Processing and for handling emojis.
- The system provided a map to display threats based on location data. The latitude and longitude associated with a raw text entry are verified to see if the threat is within range of a Merck facility. It also provides a mechanism for asynchronous, email notification of new threats.
There are three major aspects to the Fall 2021 Merck Senior Design project.
- The team will update logic and Improve on visualization of the existing software. This will include addition of a sentiment rating or index to represent a risk factor for an individual. This rating will reflect both internal chat messages as well as external social media data. Students will need to collect and create their own datasets to develop and demonstrate these features.
- After gaining an understanding of existing software, the team will conduct additional research in the area of insider threat detection in an effort to identify the latest techniques and tools. The team will report findings and recommendations for the best directions to extend and enhance the project. This investigation should include looking at criminal behavior and their interaction/ influence on insider threats.
- After identifying a technique and/or tools, the team will develop and implement a new algorithm leveraging the same techniques used in the early project or improving on them. Consider answering questions like: “What signals can we mine that will reflect a change in motive and lead to a nefarious behavior?”, “ What are the data attributes that empirically map to human behavior?”
Key Assumptions
- The project will focus on English text like what might appear in a chat session (e.g., social media, internal chat)
- The system will depend on manual data ingestion., but the system is not expected to be able to acquire this data automatically.
- Latitude and longitude data can be considered to be as reliable as the source of the text. For internal chats, this data may not be needed, or it may be appropriate to make assumptions about the location.
- For privacy reasons, the sponsor won’t be able to provide real-world data. The team will need to create and acquire needed data for designing, developing, testing and demonstrating their work.
- The system is only expected to handle threatening text input only. Other types of sentiment analysis are not expected.
- An insult is considered a “threatening” sentiment.
Technologies and Other Constraints
The Spring 2020 Merck Senior Design team produced a proof-of-concept sentiment analysis tool that leveraged the several technologies. The 2021 team will be using many of these same technologies as they refine and extend the existing work.
- AWS-based backend infrastructure
- Python/Flask API and data processing
- VADER for sentiment analysis
- Angular 2+ frontend
- PyUnit tests for API and backend
- Black Box test suite for frontend
Deliverables from the previous Senior Design project will be provided to students once the team is formed.
Students will be required to sign over IP to sponsors when the team is formed
Project Archives
| 2026 | Spring | Fall | |
| 2025 | Spring | Fall | |
| 2024 | Spring | Fall | |
| 2023 | Spring | Fall | |
| 2022 | Spring | Fall | |
| 2021 | Spring | Fall | |
| 2020 | Spring | Fall | |
| 2019 | Spring | Fall | |
| 2018 | Spring | Fall | |
| 2017 | Spring | Fall | |
| 2016 | Spring | Fall | |
| 2015 | Spring | Fall | |
| 2014 | Spring | Fall | |
| 2013 | Spring | Fall | |
| 2012 | Spring | Fall | |
| 2011 | Spring | Fall | |
| 2010 | Spring | Fall | |
| 2009 | Spring | Fall | |
| 2008 | Spring | Fall | |
| 2007 | Spring | Fall | Summer |
| 2006 | Spring | Fall | |
| 2005 | Spring | Fall | |
| 2004 | Spring | Fall | Summer |
| 2003 | Spring | Fall | |
| 2002 | Spring | Fall | |
| 2001 | Spring | Fall |